 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Federated Anomaly Detection for Multivariate Time Series Data
May 09, 2022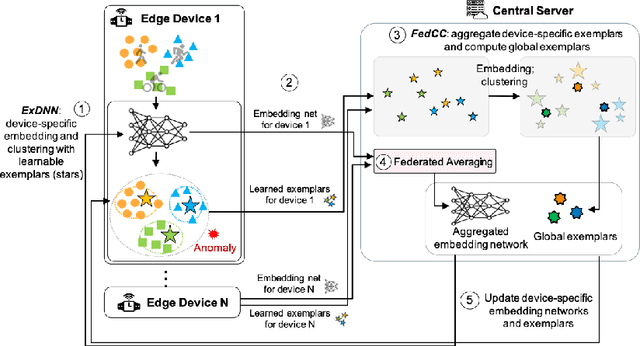
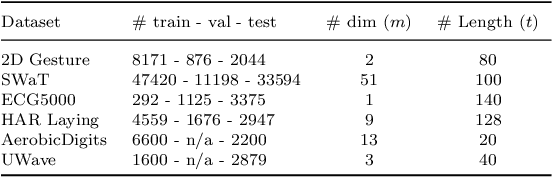
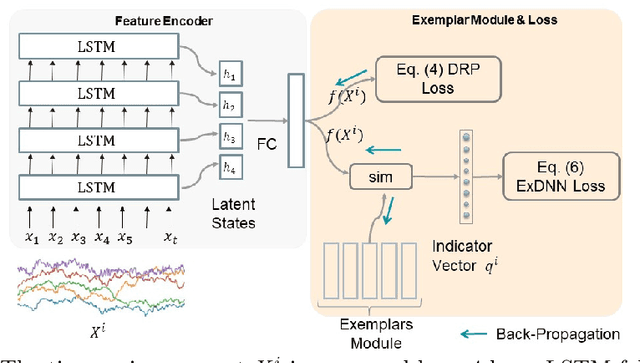
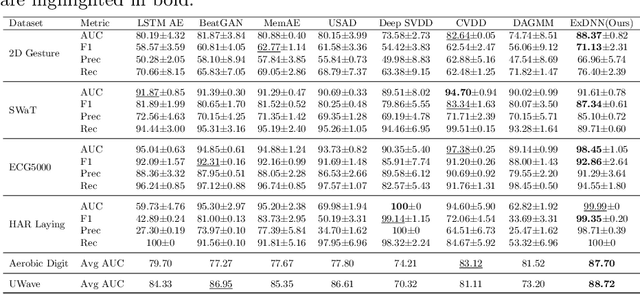
Despite the fact that many anomaly detection approaches have been developed for multivariate time series data, limited effort has been made on federated settings in which multivariate time series data are heterogeneously distributed among different edge devices while data sharing is prohibited. In this paper, we investigate the problem of federated unsupervised anomaly detection and present a Federated Exemplar-based Deep Neural Network (Fed-ExDNN) to conduct anomaly detection for multivariate time series data on different edge devices. Specifically, we first design an Exemplar-based Deep Neural network (ExDNN) to learn local time series representations based on their compatibility with an exemplar module which consists of hidden parameters learned to capture varieties of normal patterns on each edge device. Next, a constrained clustering mechanism (FedCC) is employed on the centralized server to align and aggregate the parameters of different local exemplar modules to obtain a unified global exemplar module. Finally, the global exemplar module is deployed together with a shared feature encoder to each edge device and anomaly detection is conducted by examining the compatibility of testing data to the exemplar module. Fed-ExDNN captures local normal time series patterns with ExDNN and aggregates these patterns by FedCC, and thus can handle the heterogeneous data distributed over different edge devices simultaneously. Thoroughly empirical studies on six public datasets show that ExDNN and Fed-ExDNN can outperform state-of-the-art anomaly detection algorithms and federated learning techniques.
Explainable Fairness in Recommendation
Apr 24, 2022
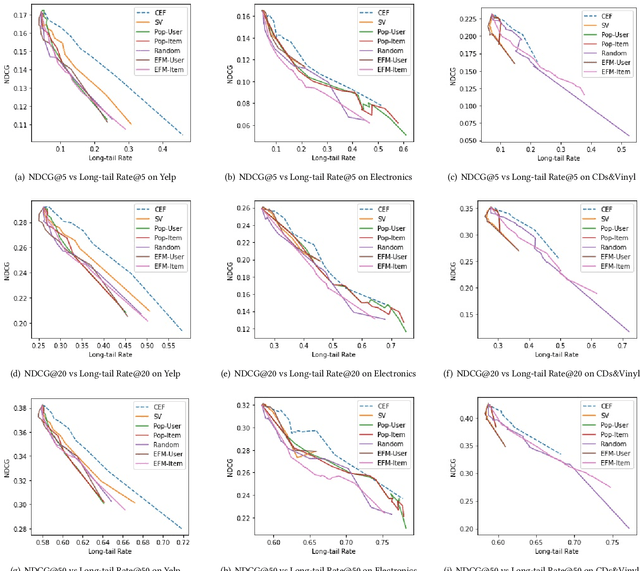
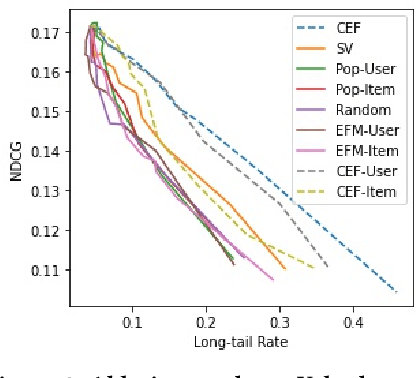
Existing research on fairness-aware recommendation has mainly focused on the quantification of fairness and the development of fair recommendation models, neither of which studies a more substantial problem--identifying the underlying reason of model disparity in recommendation. This information is critical for recommender system designers to understand the intrinsic recommendation mechanism and provides insights on how to improve model fairness to decision makers. Fortunately, with the rapid development of Explainable AI, we can use model explainability to gain insights into model (un)fairness. In this paper, we study the problem of explainable fairness, which helps to gain insights about why a system is fair or unfair, and guides the design of fair recommender systems with a more informed and unified methodology. Particularly, we focus on a common setting with feature-aware recommendation and exposure unfairness, but the proposed explainable fairness framework is general and can be applied to other recommendation settings and fairness definitions. We propose a Counterfactual Explainable Fairness framework, called CEF, which generates explanations about model fairness that can improve the fairness without significantly hurting the performance.The CEF framework formulates an optimization problem to learn the "minimal" change of the input features that changes the recommendation results to a certain level of fairness. Based on the counterfactual recommendation result of each feature, we calculate an explainability score in terms of the fairness-utility trade-off to rank all the feature-based explanations, and select the top ones as fairness explanations.
Breast Cancer Induced Bone Osteolysis Prediction Using Temporal Variational Auto-Encoders
Mar 28, 2022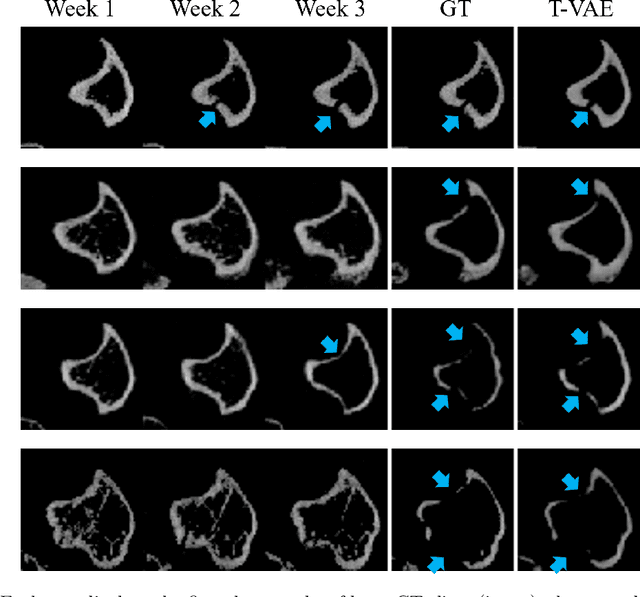
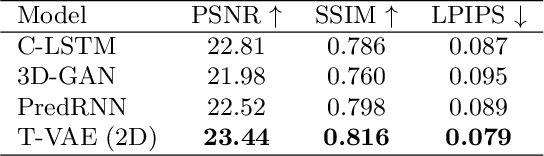
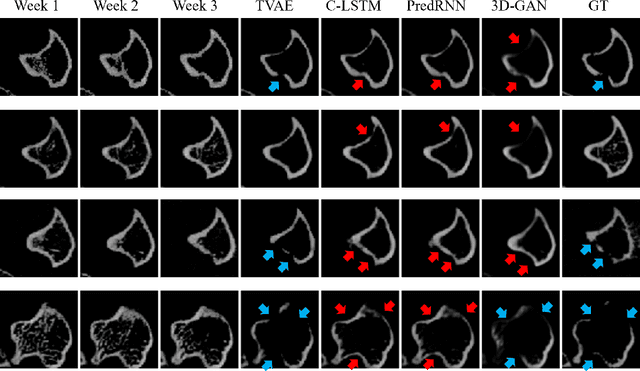

Objective and Impact Statement. We adopt a deep learning model for bone osteolysis prediction on computed tomography (CT) images of murine breast cancer bone metastases. Given the bone CT scans at previous time steps, the model incorporates the bone-cancer interactions learned from the sequential images and generates future CT images. Its ability of predicting the development of bone lesions in cancer-invading bones can assist in assessing the risk of impending fractures and choosing proper treatments in breast cancer bone metastasis. Introduction. Breast cancer often metastasizes to bone, causes osteolytic lesions, and results in skeletal related events (SREs) including severe pain and even fatal fractures. Although current imaging techniques can detect macroscopic bone lesions, predicting the occurrence and progression of bone lesions remains a challenge. Methods. We adopt a temporal variational auto-encoder (T-VAE) model that utilizes a combination of variational auto-encoders and long short-term memory networks to predict bone lesion emergence on our micro-CT dataset containing sequential images of murine tibiae. Given the CT scans of murine tibiae at early weeks, our model can learn the distribution of their future states from data. Results. We test our model against other deep learning-based prediction models on the bone lesion progression prediction task. Our model produces much more accurate predictions than existing models under various evaluation metrics. Conclusion. We develop a deep learning framework that can accurately predict and visualize the progression of osteolytic bone lesions. It will assist in planning and evaluating treatment strategies to prevent SREs in breast cancer patients.
CM-GAN: Image Inpainting with Cascaded Modulation GAN and Object-Aware Training
Mar 22, 2022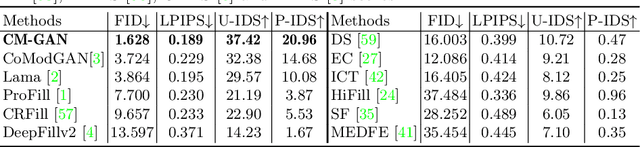
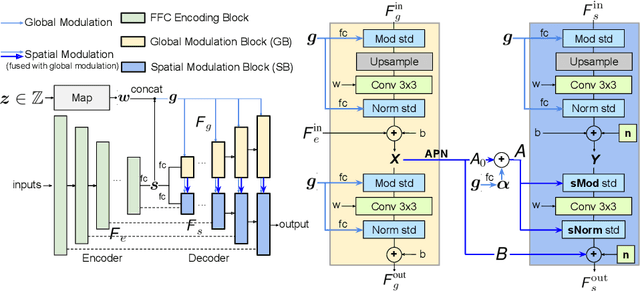
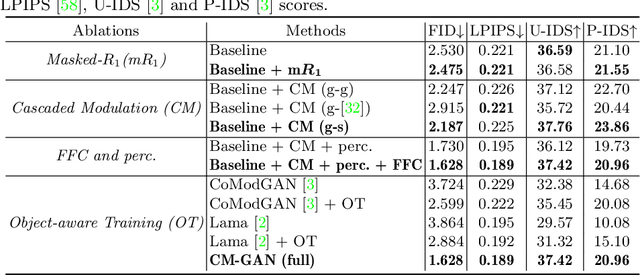

Recent image inpainting methods have made great progress but often struggle to generate plausible image structures when dealing with large holes in complex images. This is partially due to the lack of effective network structures that can capture both the long-range dependency and high-level semantics of an image. To address these problems, we propose cascaded modulation GAN (CM-GAN), a new network design consisting of an encoder with Fourier convolution blocks that extract multi-scale feature representations from the input image with holes and a StyleGAN-like decoder with a novel cascaded global-spatial modulation block at each scale level. In each decoder block, global modulation is first applied to perform coarse semantic-aware structure synthesis, then spatial modulation is applied on the output of global modulation to further adjust the feature map in a spatially adaptive fashion. In addition, we design an object-aware training scheme to prevent the network from hallucinating new objects inside holes, fulfilling the needs of object removal tasks in real-world scenarios. Extensive experiments are conducted to show that our method significantly outperforms existing methods in both quantitative and qualitative evaluation.
Self-Sustaining Representation Expansion for Non-Exemplar Class-Incremental Learning
Mar 16, 2022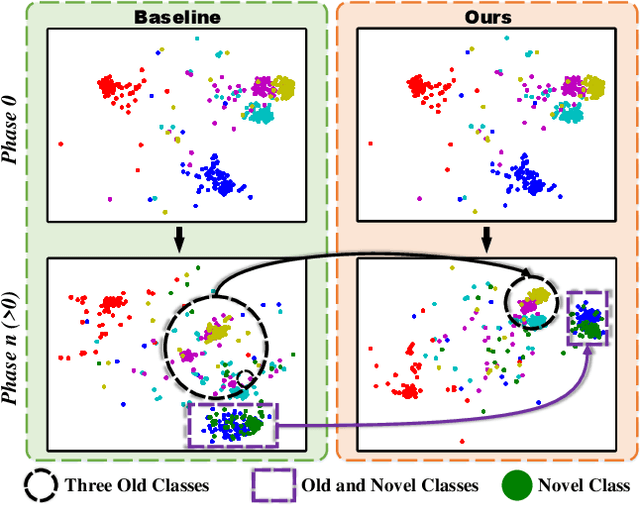
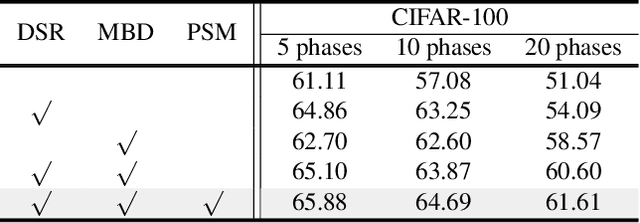
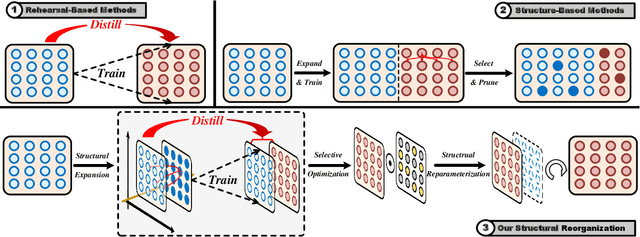
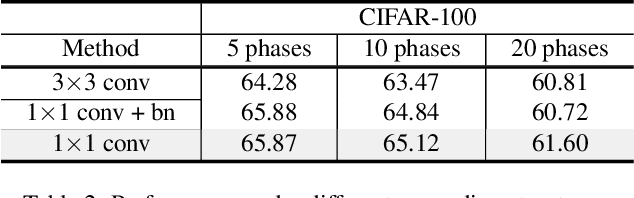
Non-exemplar class-incremental learning is to recognize both the old and new classes when old class samples cannot be saved. It is a challenging task since representation optimization and feature retention can only be achieved under supervision from new classes. To address this problem, we propose a novel self-sustaining representation expansion scheme. Our scheme consists of a structure reorganization strategy that fuses main-branch expansion and side-branch updating to maintain the old features, and a main-branch distillation scheme to transfer the invariant knowledge. Furthermore, a prototype selection mechanism is proposed to enhance the discrimination between the old and new classes by selectively incorporating new samples into the distillation process. Extensive experiments on three benchmarks demonstrate significant incremental performance, outperforming the state-of-the-art methods by a margin of 3%, 3% and 6%, respectively.
Point Cloud Denoising via Momentum Ascent in Gradient Fields
Mar 15, 2022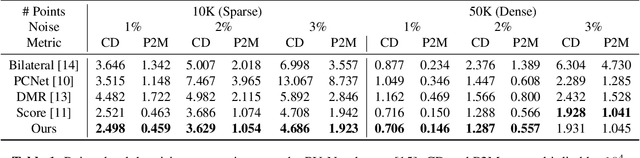
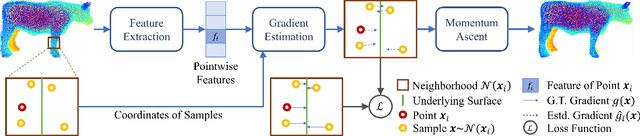

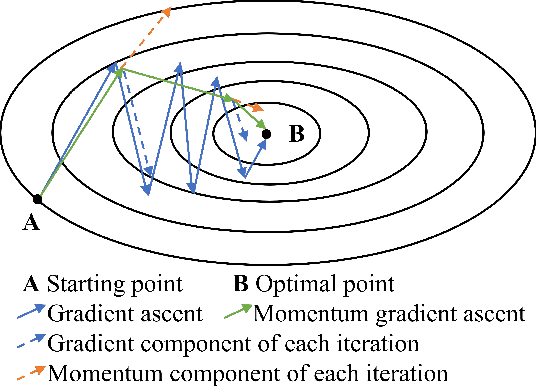
To achieve point cloud denoising, traditional methods heavily rely on geometric priors, and most learning-based approaches suffer from outliers and loss of details. Recently, the gradient-based method was proposed to estimate the gradient fields from the noisy point clouds using neural networks, and refine the position of each point according to the estimated gradient. However, the predicted gradient could fluctuate, leading to perturbed and unstable solutions, as well as a large inference time. To address these issues, we develop the momentum gradient ascent method that leverages the information of previous iterations in determining the trajectories of the points, thus improving the stability of the solution and reducing the inference time. Experiments demonstrate that the proposed method outperforms state-of-the-art methods with a variety of point clouds and noise levels.
RawlsGCN: Towards Rawlsian Difference Principle on Graph Convolutional Network
Feb 28, 2022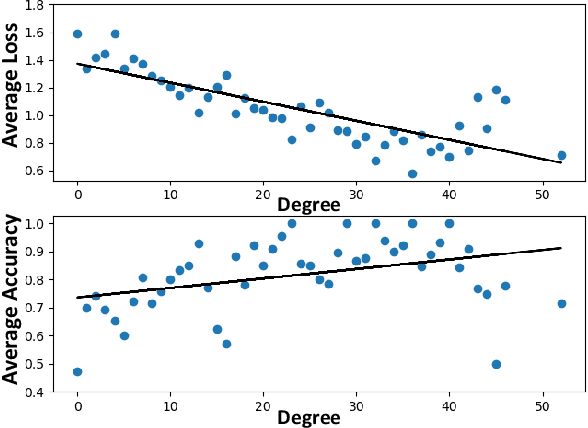

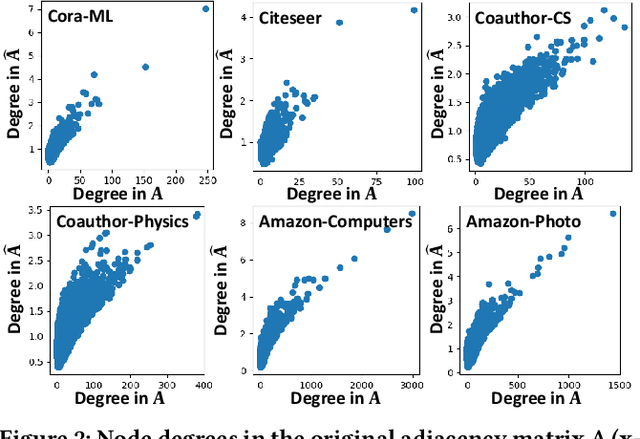
Graph Convolutional Network (GCN) plays pivotal roles in many real-world applications. Despite the successes of GCN deployment, GCN often exhibits performance disparity with respect to node degrees, resulting in worse predictive accuracy for low-degree nodes. We formulate the problem of mitigating the degree-related performance disparity in GCN from the perspective of the Rawlsian difference principle, which is originated from the theory of distributive justice. Mathematically, we aim to balance the utility between low-degree nodes and high-degree nodes while minimizing the task-specific loss. Specifically, we reveal the root cause of this degree-related unfairness by analyzing the gradients of weight matrices in GCN. Guided by the gradients of weight matrices, we further propose a pre-processing method RawlsGCN-Graph and an in-processing method RawlsGCN-Grad that achieves fair predictive accuracy in low-degree nodes without modification on the GCN architecture or introduction of additional parameters. Extensive experiments on real-world graphs demonstrate the effectiveness of our proposed RawlsGCN methods in significantly reducing degree-related bias while retaining comparable overall performance.
MANet: Improving Video Denoising with a Multi-Alignment Network
Feb 20, 2022
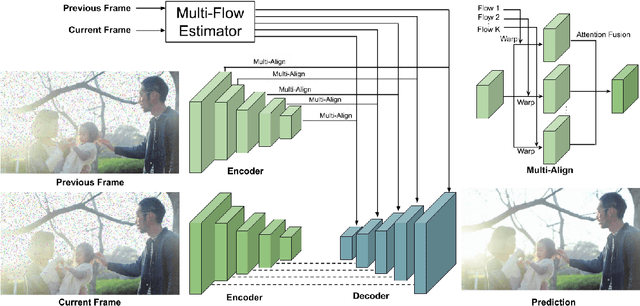
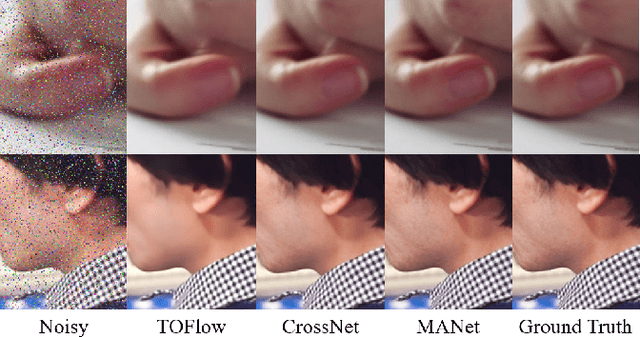
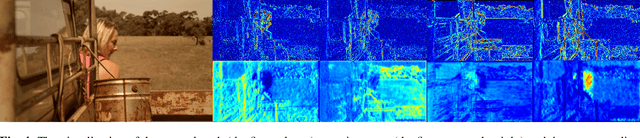
In video denoising, the adjacent frames often provide very useful information, but accurate alignment is needed before such information can be harnassed. In this work, we present a multi-alignment network, which generates multiple flow proposals followed by attention-based averaging. It serves to mimics the non-local mechanism, suppressing noise by averaging multiple observations. Our approach can be applied to various state-of-the-art models that are based on flow estimation. Experiments on a large-scale video dataset demonstrate that our method improves the denoising baseline model by 0.2dB, and further reduces the parameters by 47% with model distillation.
Cross-modal Contrastive Distillation for Instructional Activity Anticipation
Jan 18, 2022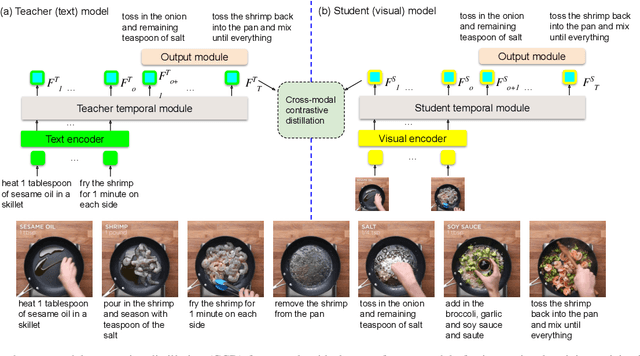
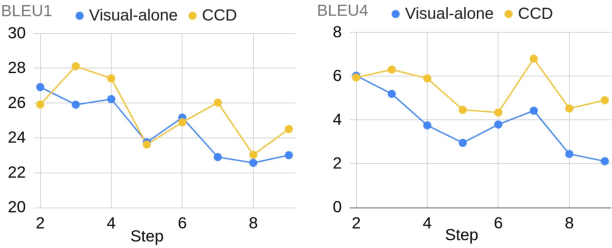

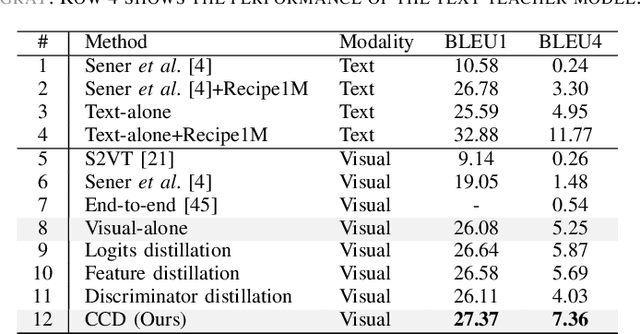
In this study, we aim to predict the plausible future action steps given an observation of the past and study the task of instructional activity anticipation. Unlike previous anticipation tasks that aim at action label prediction, our work targets at generating natural language outputs that provide interpretable and accurate descriptions of future action steps. It is a challenging task due to the lack of semantic information extracted from the instructional videos. To overcome this challenge, we propose a novel knowledge distillation framework to exploit the related external textual knowledge to assist the visual anticipation task. However, previous knowledge distillation techniques generally transfer information within the same modality. To bridge the gap between the visual and text modalities during the distillation process, we devise a novel cross-modal contrastive distillation (CCD) scheme, which facilitates knowledge distillation between teacher and student in heterogeneous modalities with the proposed cross-modal distillation loss. We evaluate our method on the Tasty Videos dataset. CCD improves the anticipation performance of the visual-alone student model by a large margin of 40.2% relatively in BLEU4. Our approach also outperforms the state-of-the-art approaches by a large margin.
Distribution-aware Margin Calibration for Semantic Segmentation in Images
Dec 21, 2021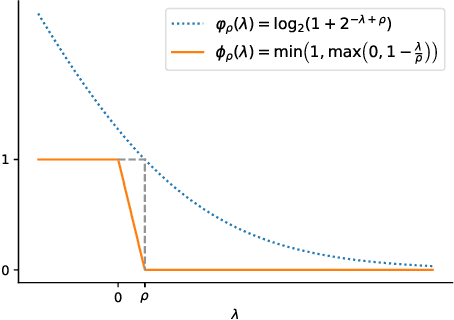
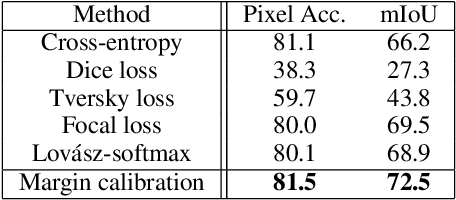

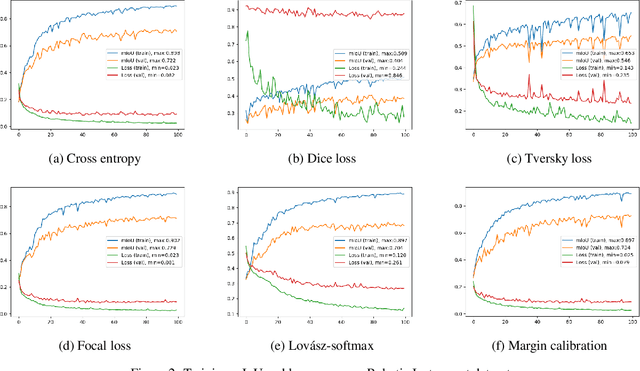
The Jaccard index, also known as Intersection-over-Union (IoU), is one of the most critical evaluation metrics in image semantic segmentation. However, direct optimization of IoU score is very difficult because the learning objective is neither differentiable nor decomposable. Although some algorithms have been proposed to optimize its surrogates, there is no guarantee provided for the generalization ability. In this paper, we propose a margin calibration method, which can be directly used as a learning objective, for an improved generalization of IoU over the data-distribution, underpinned by a rigid lower bound. This scheme theoretically ensures a better segmentation performance in terms of IoU score. We evaluated the effectiveness of the proposed margin calibration method on seven image datasets, showing substantial improvements in IoU score over other learning objectives using deep segmentation models.