 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Catastrophic Forgetting in Large Language Models During Continual Fine-tuning
Aug 21, 2023



Catastrophic forgetting (CF) is a phenomenon that occurs in machine learning when a model forgets previously learned information as it learns new information. As large language models (LLMs) have shown excellent performance, it is interesting to uncover whether CF exists in the continual fine-tuning of LLMs. In this study, we empirically evaluate the forgetting phenomenon in LLMs' knowledge, from the perspectives of domain knowledge, reasoning, and reading comprehension. The experiments demonstrate that catastrophic forgetting is generally observed in LLMs ranging from 1b to 7b. Furthermore, as the scale increases, the severity of forgetting also intensifies. Comparing the decoder-only model BLOOMZ with the encoder-decoder model mT0, BLOOMZ suffers less forgetting and maintains more knowledge. We also observe that LLMs can mitigate language bias (e.g. gender bias) during continual fine-tuning. Moreover, we find that ALPACA can maintain more knowledge and capacity compared with LLAMA during the continual fine-tuning, which implies that general instruction tuning can help mitigate the forgetting phenomenon of LLMs in the further fine-tuning process.
Towards Multiple References Era -- Addressing Data Leakage and Limited Reference Diversity in NLG Evaluation
Aug 10, 2023



N-gram matching-based evaluation metrics, such as BLEU and chrF, are widely utilized across a range of natural language generation (NLG) tasks. However, recent studies have revealed a weak correlation between these matching-based metrics and human evaluations, especially when compared with neural-based metrics like BLEURT. In this paper, we conjecture that the performance bottleneck in matching-based metrics may be caused by the limited diversity of references. To address this issue, we propose to utilize \textit{multiple references} to enhance the consistency between these metrics and human evaluations. Within the WMT Metrics benchmarks, we observe that the multi-references F200spBLEU surpasses the conventional single-reference one by an accuracy improvement of 7.2\%. Remarkably, it also exceeds the neural-based BERTscore by an accuracy enhancement of 3.9\%. Moreover, we observe that the data leakage issue in large language models (LLMs) can be mitigated to a large extent by our multi-reference metric. We release the code and data at \url{https://github.com/SefaZeng/LLM-Ref}
Human-M3: A Multi-view Multi-modal Dataset for 3D Human Pose Estimation in Outdoor Scenes
Aug 06, 2023



3D human pose estimation in outdoor environments has garnered increasing attention recently. However, prevalent 3D human pose datasets pertaining to outdoor scenes lack diversity, as they predominantly utilize only one type of modality (RGB image or pointcloud), and often feature only one individual within each scene. This limited scope of dataset infrastructure considerably hinders the variability of available data. In this article, we propose Human-M3, an outdoor multi-modal multi-view multi-person human pose database which includes not only multi-view RGB videos of outdoor scenes but also corresponding pointclouds. In order to obtain accurate human poses, we propose an algorithm based on multi-modal data input to generate ground truth annotation. This benefits from robust pointcloud detection and tracking, which solves the problem of inaccurate human localization and matching ambiguity that may exist in previous multi-view RGB videos in outdoor multi-person scenes, and generates reliable ground truth annotations. Evaluation of multiple different modalities algorithms has shown that this database is challenging and suitable for future research. Furthermore, we propose a 3D human pose estimation algorithm based on multi-modal data input, which demonstrates the advantages of multi-modal data input for 3D human pose estimation. Code and data will be released on https://github.com/soullessrobot/Human-M3-Dataset.
EduChat: A Large-Scale Language Model-based Chatbot System for Intelligent Education
Aug 05, 2023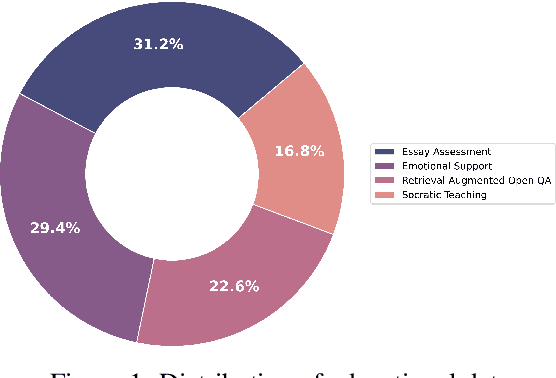



EduChat (https://www.educhat.top/) is a large-scale language model (LLM)-based chatbot system in the education domain. Its goal is to support personalized, fair, and compassionate intelligent education, serving teachers, students, and parents. Guided by theories from psychology and education, it further strengthens educational functions such as open question answering, essay assessment, Socratic teaching, and emotional support based on the existing basic LLMs. Particularly, we learn domain-specific knowledge by pre-training on the educational corpus and stimulate various skills with tool use by fine-tuning on designed system prompts and instructions. Currently, EduChat is available online as an open-source project, with its code, data, and model parameters available on platforms (e.g., GitHub https://github.com/icalk-nlp/EduChat, Hugging Face https://huggingface.co/ecnu-icalk ). We also prepare a demonstration of its capabilities online (https://vimeo.com/851004454). This initiative aims to promote research and applications of LLMs for intelligent education.
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Jul 31, 2023Despite the advancements of open-source large language models (LLMs) and their variants, e.g., LLaMA and Vicuna, they remain significantly limited in performing higher-level tasks, such as following human instructions to use external tools (APIs). This is because current instruction tuning largely focuses on basic language tasks instead of the tool-use domain. This is in contrast to state-of-the-art (SOTA) LLMs, e.g., ChatGPT, which have demonstrated excellent tool-use capabilities but are unfortunately closed source. To facilitate tool-use capabilities within open-source LLMs, we introduce ToolLLM, a general tool-use framework of data construction, model training and evaluation. We first present ToolBench, an instruction-tuning dataset for tool use, which is created automatically using ChatGPT. Specifically, we collect 16,464 real-world RESTful APIs spanning 49 categories from RapidAPI Hub, then prompt ChatGPT to generate diverse human instructions involving these APIs, covering both single-tool and multi-tool scenarios. Finally, we use ChatGPT to search for a valid solution path (chain of API calls) for each instruction. To make the searching process more efficient, we develop a novel depth-first search-based decision tree (DFSDT), enabling LLMs to evaluate multiple reasoning traces and expand the search space. We show that DFSDT significantly enhances the planning and reasoning capabilities of LLMs. For efficient tool-use assessment, we develop an automatic evaluator: ToolEval. We fine-tune LLaMA on ToolBench and obtain ToolLLaMA. Our ToolEval reveals that ToolLLaMA demonstrates a remarkable ability to execute complex instructions and generalize to unseen APIs, and exhibits comparable performance to ChatGPT. To make the pipeline more practical, we devise a neural API retriever to recommend appropriate APIs for each instruction, negating the need for manual API selection.
Towards Codable Text Watermarking for Large Language Models
Jul 29, 2023As large language models (LLMs) generate texts with increasing fluency and realism, there is a growing need to identify the source of texts to prevent the abuse of LLMs. Text watermarking techniques have proven reliable in distinguishing whether a text is generated by LLMs by injecting hidden patterns into the generated texts. However, we argue that existing watermarking methods for LLMs are encoding-inefficient (only contain one bit of information - whether it is generated from an LLM or not) and cannot flexibly meet the diverse information encoding needs (such as encoding model version, generation time, user id, etc.) in different LLMs application scenarios. In this work, we conduct the first systematic study on the topic of Codable Text Watermarking for LLMs (CTWL) that allows text watermarks to carry more customizable information. First of all, we study the taxonomy of LLM watermarking technology and give a mathematical formulation for CTWL. Additionally, we provide a comprehensive evaluation system for CTWL: (1) watermarking success rate, (2) robustness against various corruptions, (3) coding rate of payload information, (4) encoding and decoding efficiency, (5) impacts on the quality of the generated text. To meet the requirements of these non-Pareto-improving metrics, we devise a CTWL method named Balance-Marking, based on the motivation of ensuring that available and unavailable vocabularies for encoding information have approximately equivalent probabilities. Compared to the random vocabulary partitioning extended from the existing work, a probability-balanced vocabulary partition can significantly improve the quality of the generated text. Extensive experimental results have shown that our method outperforms a direct baseline under comprehensive evaluation.
Take-A-Photo: 3D-to-2D Generative Pre-training of Point Cloud Models
Jul 27, 2023



With the overwhelming trend of mask image modeling led by MAE, generative pre-training has shown a remarkable potential to boost the performance of fundamental models in 2D vision. However, in 3D vision, the over-reliance on Transformer-based backbones and the unordered nature of point clouds have restricted the further development of generative pre-training. In this paper, we propose a novel 3D-to-2D generative pre-training method that is adaptable to any point cloud model. We propose to generate view images from different instructed poses via the cross-attention mechanism as the pre-training scheme. Generating view images has more precise supervision than its point cloud counterpart, thus assisting 3D backbones to have a finer comprehension of the geometrical structure and stereoscopic relations of the point cloud. Experimental results have proved the superiority of our proposed 3D-to-2D generative pre-training over previous pre-training methods. Our method is also effective in boosting the performance of architecture-oriented approaches, achieving state-of-the-art performance when fine-tuning on ScanObjectNN classification and ShapeNetPart segmentation tasks. Code is available at https://github.com/wangzy22/TAP.
TIM: Teaching Large Language Models to Translate with Comparison
Jul 10, 2023



Open-sourced large language models (LLMs) have demonstrated remarkable efficacy in various tasks with instruction tuning. However, these models can sometimes struggle with tasks that require more specialized knowledge such as translation. One possible reason for such deficiency is that instruction tuning aims to generate fluent and coherent text that continues from a given instruction without being constrained by any task-specific requirements. Moreover, it can be more challenging for tuning smaller LLMs with lower-quality training data. To address this issue, we propose a novel framework using examples in comparison to teach LLMs to learn translation. Our approach involves presenting the model with examples of correct and incorrect translations and using a preference loss to guide the model's learning. We evaluate our method on WMT2022 test sets and show that it outperforms existing methods. Our findings offer a new perspective on fine-tuning LLMs for translation tasks and provide a promising solution for generating high-quality translations. Please refer to Github for more details: https://github.com/lemon0830/TIM.
Soft Language Clustering for Multilingual Model Pre-training
Jun 13, 2023



Multilingual pre-trained language models have demonstrated impressive (zero-shot) cross-lingual transfer abilities, however, their performance is hindered when the target language has distant typology from source languages or when pre-training data is limited in size. In this paper, we propose XLM-P, which contextually retrieves prompts as flexible guidance for encoding instances conditionally. Our XLM-P enables (1) lightweight modeling of language-invariant and language-specific knowledge across languages, and (2) easy integration with other multilingual pre-training methods. On the tasks of XTREME including text classification, sequence labeling, question answering, and sentence retrieval, both base- and large-size language models pre-trained with our proposed method exhibit consistent performance improvement. Furthermore, it provides substantial advantages for low-resource languages in unsupervised sentence retrieval and for target languages that differ greatly from the source language in cross-lingual transfer.
Towards Accurate Data-free Quantization for Diffusion Models
Jun 07, 2023



In this paper, we propose an accurate data-free post-training quantization framework of diffusion models (ADP-DM) for efficient image generation. Conventional data-free quantization methods learn shared quantization functions for tensor discretization regardless of the generation timesteps, while the activation distribution differs significantly across various timesteps. The calibration images are acquired in random timesteps which fail to provide sufficient information for generalizable quantization function learning. Both issues cause sizable quantization errors with obvious image generation performance degradation. On the contrary, we design group-wise quantization functions for activation discretization in different timesteps and sample the optimal timestep for informative calibration image generation, so that our quantized diffusion model can reduce the discretization errors with negligible computational overhead. Specifically, we partition the timesteps according to the importance weights of quantization functions in different groups, which are optimized by differentiable search algorithms. We also select the optimal timestep for calibration image generation by structural risk minimizing principle in order to enhance the generalization ability in the deployment of quantized diffusion model. Extensive experimental results show that our method outperforms the state-of-the-art post-training quantization of diffusion model by a sizable margin with similar computational cost.