 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOIG-P: A High-Quality and Large-Scale Chinese Preference Dataset for Alignment with Human Values
Apr 07, 2025Aligning large language models (LLMs) with human preferences has achieved remarkable success. However, existing Chinese preference datasets are limited by small scale, narrow domain coverage, and lack of rigorous data validation. Additionally, the reliance on human annotators for instruction and response labeling significantly constrains the scalability of human preference datasets. To address these challenges, we design an LLM-based Chinese preference dataset annotation pipeline with no human intervention. Specifically, we crawled and carefully filtered 92k high-quality Chinese queries and employed 15 mainstream LLMs to generate and score chosen-rejected response pairs. Based on it, we introduce COIG-P (Chinese Open Instruction Generalist - Preference), a high-quality, large-scale Chinese preference dataset, comprises 1,009k Chinese preference pairs spanning 6 diverse domains: Chat, Code, Math, Logic, Novel, and Role. Building upon COIG-P, to reduce the overhead of using LLMs for scoring, we trained a 8B-sized Chinese Reward Model (CRM) and meticulously constructed a Chinese Reward Benchmark (CRBench). Evaluation results based on AlignBench \citep{liu2024alignbenchbenchmarkingchinesealignment} show that that COIG-P significantly outperforms other Chinese preference datasets, and it brings significant performance improvements ranging from 2% to 12% for the Qwen2/2.5 and Infinity-Instruct-3M-0625 model series, respectively. The results on CRBench demonstrate that our CRM has a strong and robust scoring ability. We apply it to filter chosen-rejected response pairs in a test split of COIG-P, and our experiments show that it is comparable to GPT-4o in identifying low-quality samples while maintaining efficiency and cost-effectiveness. Our codes and data are released in https://github.com/multimodal-art-projection/COIG-P.
Biomedical Question Answering via Multi-Level Summarization on a Local Knowledge Graph
Apr 02, 2025



In Question Answering (QA), Retrieval Augmented Generation (RAG) has revolutionized performance in various domains. However, how to effectively capture multi-document relationships, particularly critical for biomedical tasks, remains an open question. In this work, we propose a novel method that utilizes propositional claims to construct a local knowledge graph from retrieved documents. Summaries are then derived via layerwise summarization from the knowledge graph to contextualize a small language model to perform QA. We achieved comparable or superior performance with our method over RAG baselines on several biomedical QA benchmarks. We also evaluated each individual step of our methodology over a targeted set of metrics, demonstrating its effectiveness.
Test-time Adaptation for Foundation Medical Segmentation Model without Parametric Updates
Apr 02, 2025Foundation medical segmentation models, with MedSAM being the most popular, have achieved promising performance across organs and lesions. However, MedSAM still suffers from compromised performance on specific lesions with intricate structures and appearance, as well as bounding box prompt-induced perturbations. Although current test-time adaptation (TTA) methods for medical image segmentation may tackle this issue, partial (e.g., batch normalization) or whole parametric updates restrict their effectiveness due to limited update signals or catastrophic forgetting in large models. Meanwhile, these approaches ignore the computational complexity during adaptation, which is particularly significant for modern foundation models. To this end, our theoretical analyses reveal that directly refining image embeddings is feasible to approach the same goal as parametric updates under the MedSAM architecture, which enables us to realize high computational efficiency and segmentation performance without the risk of catastrophic forgetting. Under this framework, we propose to encourage maximizing factorized conditional probabilities of the posterior prediction probability using a proposed distribution-approximated latent conditional random field loss combined with an entropy minimization loss. Experiments show that we achieve about 3\% Dice score improvements across three datasets while reducing computational complexity by over 7 times.
Federated Learning for Cross-Domain Data Privacy: A Distributed Approach to Secure Collaboration
Mar 31, 2025This paper proposes a data privacy protection framework based on federated learning, which aims to realize effective cross-domain data collaboration under the premise of ensuring data privacy through distributed learning. Federated learning greatly reduces the risk of privacy breaches by training the model locally on each client and sharing only model parameters rather than raw data. The experiment verifies the high efficiency and privacy protection ability of federated learning under different data sources through the simulation of medical, financial, and user data. The results show that federated learning can not only maintain high model performance in a multi-domain data environment but also ensure effective protection of data privacy. The research in this paper provides a new technical path for cross-domain data collaboration and promotes the application of large-scale data analysis and machine learning while protecting privacy.
AgentDropout: Dynamic Agent Elimination for Token-Efficient and High-Performance LLM-Based Multi-Agent Collaboration
Mar 24, 2025Multi-agent systems (MAS) based on large language models (LLMs) have demonstrated significant potential in collaborative problem-solving. However, they still face substantial challenges of low communication efficiency and suboptimal task performance, making the careful design of the agents' communication topologies particularly important. Inspired by the management theory that roles in an efficient team are often dynamically adjusted, we propose AgentDropout, which identifies redundant agents and communication across different communication rounds by optimizing the adjacency matrices of the communication graphs and eliminates them to enhance both token efficiency and task performance. Compared to state-of-the-art methods, AgentDropout achieves an average reduction of 21.6% in prompt token consumption and 18.4% in completion token consumption, along with a performance improvement of 1.14 on the tasks. Furthermore, the extended experiments demonstrate that AgentDropout achieves notable domain transferability and structure robustness, revealing its reliability and effectiveness. We release our code at https://github.com/wangzx1219/AgentDropout.
Enhancing Zero-Shot Image Recognition in Vision-Language Models through Human-like Concept Guidance
Mar 21, 2025



In zero-shot image recognition tasks, humans demonstrate remarkable flexibility in classifying unseen categories by composing known simpler concepts. However, existing vision-language models (VLMs), despite achieving significant progress through large-scale natural language supervision, often underperform in real-world applications because of sub-optimal prompt engineering and the inability to adapt effectively to target classes. To address these issues, we propose a Concept-guided Human-like Bayesian Reasoning (CHBR) framework. Grounded in Bayes' theorem, CHBR models the concept used in human image recognition as latent variables and formulates this task by summing across potential concepts, weighted by a prior distribution and a likelihood function. To tackle the intractable computation over an infinite concept space, we introduce an importance sampling algorithm that iteratively prompts large language models (LLMs) to generate discriminative concepts, emphasizing inter-class differences. We further propose three heuristic approaches involving Average Likelihood, Confidence Likelihood, and Test Time Augmentation (TTA) Likelihood, which dynamically refine the combination of concepts based on the test image. Extensive evaluations across fifteen datasets demonstrate that CHBR consistently outperforms existing state-of-the-art zero-shot generalization methods.
Binarized Mamba-Transformer for Lightweight Quad Bayer HybridEVS Demosaicing
Mar 20, 2025
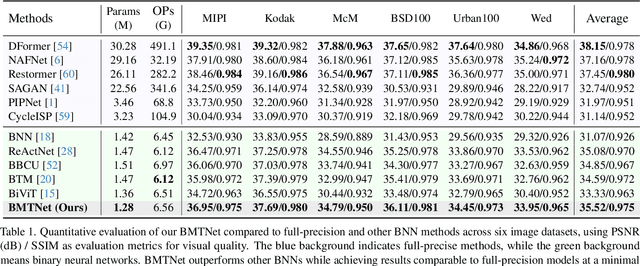
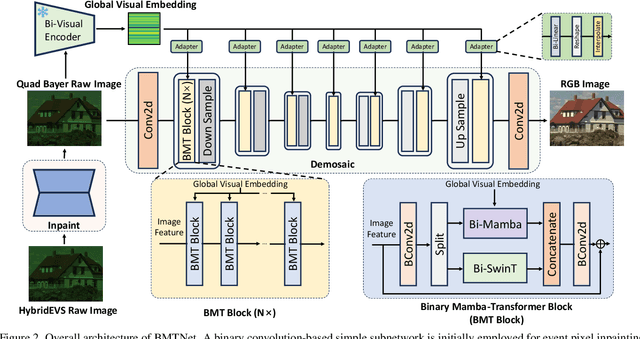

Quad Bayer demosaicing is the central challenge for enabling the widespread application of Hybrid Event-based Vision Sensors (HybridEVS). Although existing learning-based methods that leverage long-range dependency modeling have achieved promising results, their complexity severely limits deployment on mobile devices for real-world applications. To address these limitations, we propose a lightweight Mamba-based binary neural network designed for efficient and high-performing demosaicing of HybridEVS RAW images. First, to effectively capture both global and local dependencies, we introduce a hybrid Binarized Mamba-Transformer architecture that combines the strengths of the Mamba and Swin Transformer architectures. Next, to significantly reduce computational complexity, we propose a binarized Mamba (Bi-Mamba), which binarizes all projections while retaining the core Selective Scan in full precision. Bi-Mamba also incorporates additional global visual information to enhance global context and mitigate precision loss. We conduct quantitative and qualitative experiments to demonstrate the effectiveness of BMTNet in both performance and computational efficiency, providing a lightweight demosaicing solution suited for real-world edge devices. Our codes and models are available at https://github.com/Clausy9/BMTNet.
Context-Aware Rule Mining Using a Dynamic Transformer-Based Framework
Mar 14, 2025This study proposes a dynamic rule data mining algorithm based on an improved Transformer architecture, aiming to improve the accuracy and efficiency of rule mining in a dynamic data environment. With the increase in data volume and complexity, traditional data mining methods are difficult to cope with dynamic data with strong temporal and variable characteristics, so new algorithms are needed to capture the temporal regularity in the data. By improving the Transformer architecture, and introducing a dynamic weight adjustment mechanism and a temporal dependency module, we enable the model to adapt to data changes and mine more accurate rules. Experimental results show that compared with traditional rule mining algorithms, the improved Transformer model has achieved significant improvements in rule mining accuracy, coverage, and stability. The contribution of each module in the algorithm performance is further verified by ablation experiments, proving the importance of temporal dependency and dynamic weight adjustment mechanisms in improving the model effect. In addition, although the improved model has certain challenges in computational efficiency, its advantages in accuracy and coverage enable it to perform well in processing complex dynamic data. Future research will focus on optimizing computational efficiency and combining more deep learning technologies to expand the application scope of the algorithm, especially in practical applications in the fields of finance, medical care, and intelligent recommendation.
RASA: Replace Anyone, Say Anything -- A Training-Free Framework for Audio-Driven and Universal Portrait Video Editing
Mar 14, 2025Portrait video editing focuses on modifying specific attributes of portrait videos, guided by audio or video streams. Previous methods typically either concentrate on lip-region reenactment or require training specialized models to extract keypoints for motion transfer to a new identity. In this paper, we introduce a training-free universal portrait video editing framework that provides a versatile and adaptable editing strategy. This framework supports portrait appearance editing conditioned on the changed first reference frame, as well as lip editing conditioned on varied speech, or a combination of both. It is based on a Unified Animation Control (UAC) mechanism with source inversion latents to edit the entire portrait, including visual-driven shape control, audio-driven speaking control, and inter-frame temporal control. Furthermore, our method can be adapted to different scenarios by adjusting the initial reference frame, enabling detailed editing of portrait videos with specific head rotations and facial expressions. This comprehensive approach ensures a holistic and flexible solution for portrait video editing. The experimental results show that our model can achieve more accurate and synchronized lip movements for the lip editing task, as well as more flexible motion transfer for the appearance editing task. Demo is available at https://alice01010101.github.io/RASA/.
LMM-R1: Empowering 3B LMMs with Strong Reasoning Abilities Through Two-Stage Rule-Based RL
Mar 11, 2025Enhancing reasoning in Large Multimodal Models (LMMs) faces unique challenges from the complex interplay between visual perception and logical reasoning, particularly in compact 3B-parameter architectures where architectural constraints limit reasoning capacity and modality alignment. While rule-based reinforcement learning (RL) excels in text-only domains, its multimodal extension confronts two critical barriers: (1) data limitations due to ambiguous answers and scarce complex reasoning examples, and (2) degraded foundational reasoning induced by multimodal pretraining. To address these challenges, we propose \textbf{LMM-R1}, a two-stage framework adapting rule-based RL for multimodal reasoning through \textbf{Foundational Reasoning Enhancement (FRE)} followed by \textbf{Multimodal Generalization Training (MGT)}. The FRE stage first strengthens reasoning abilities using text-only data with rule-based RL, then the MGT stage generalizes these reasoning capabilities to multimodal domains. Experiments on Qwen2.5-VL-Instruct-3B demonstrate that LMM-R1 achieves 4.83\% and 4.5\% average improvements over baselines in multimodal and text-only benchmarks, respectively, with a 3.63\% gain in complex Football Game tasks. These results validate that text-based reasoning enhancement enables effective multimodal generalization, offering a data-efficient paradigm that bypasses costly high-quality multimodal training data.