 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXDen-1K: A Density Field Dataset of Real-World Objects
Dec 11, 2025A deep understanding of the physical world is a central goal for embodied AI and realistic simulation. While current models excel at capturing an object's surface geometry and appearance, they largely neglect its internal physical properties. This omission is critical, as properties like volumetric density are fundamental for predicting an object's center of mass, stability, and interaction dynamics in applications ranging from robotic manipulation to physical simulation. The primary bottleneck has been the absence of large-scale, real-world data. To bridge this gap, we introduce XDen-1K, the first large-scale, multi-modal dataset designed for real-world physical property estimation, with a particular focus on volumetric density. The core of this dataset consists of 1,000 real-world objects across 148 categories, for which we provide comprehensive multi-modal data, including a high-resolution 3D geometric model with part-level annotations and a corresponding set of real-world biplanar X-ray scans. Building upon this data, we introduce a novel optimization framework that recovers a high-fidelity volumetric density field of each object from its sparse X-ray views. To demonstrate its practical value, we add X-ray images as a conditioning signal to an existing segmentation network and perform volumetric segmentation. Furthermore, we conduct experiments on downstream robotics tasks. The results show that leveraging the dataset can effectively improve the accuracy of center-of-mass estimation and the success rate of robotic manipulation. We believe XDen-1K will serve as a foundational resource and a challenging new benchmark, catalyzing future research in physically grounded visual inference and embodied AI.
Embodied Tree of Thoughts: Deliberate Manipulation Planning with Embodied World Model
Dec 09, 2025World models have emerged as a pivotal component in robot manipulation planning, enabling agents to predict future environmental states and reason about the consequences of actions before execution. While video-generation models are increasingly adopted, they often lack rigorous physical grounding, leading to hallucinations and a failure to maintain consistency in long-horizon physical constraints. To address these limitations, we propose Embodied Tree of Thoughts (EToT), a novel Real2Sim2Real planning framework that leverages a physics-based interactive digital twin as an embodied world model. EToT formulates manipulation planning as a tree search expanded through two synergistic mechanisms: (1) Priori Branching, which generates diverse candidate execution paths based on semantic and spatial analysis; and (2) Reflective Branching, which utilizes VLMs to diagnose execution failures within the simulator and iteratively refine the planning tree with corrective actions. By grounding high-level reasoning in a physics simulator, our framework ensures that generated plans adhere to rigid-body dynamics and collision constraints. We validate EToT on a suite of short- and long-horizon manipulation tasks, where it consistently outperforms baselines by effectively predicting physical dynamics and adapting to potential failures. Website at https://embodied-tree-of-thoughts.github.io .
One Policy but Many Worlds: A Scalable Unified Policy for Versatile Humanoid Locomotion
May 24, 2025



Humanoid locomotion faces a critical scalability challenge: traditional reinforcement learning (RL) methods require task-specific rewards and struggle to leverage growing datasets, even as more training terrains are introduced. We propose DreamPolicy, a unified framework that enables a single policy to master diverse terrains and generalize zero-shot to unseen scenarios by systematically integrating offline data and diffusion-driven motion synthesis. At its core, DreamPolicy introduces Humanoid Motion Imagery (HMI) - future state predictions synthesized through an autoregressive terrain-aware diffusion planner curated by aggregating rollouts from specialized policies across various distinct terrains. Unlike human motion datasets requiring laborious retargeting, our data directly captures humanoid kinematics, enabling the diffusion planner to synthesize "dreamed" trajectories that encode terrain-specific physical constraints. These trajectories act as dynamic objectives for our HMI-conditioned policy, bypassing manual reward engineering and enabling cross-terrain generalization. DreamPolicy addresses the scalability limitations of prior methods: while traditional RL fails to exploit growing datasets, our framework scales seamlessly with more offline data. As the dataset expands, the diffusion prior learns richer locomotion skills, which the policy leverages to master new terrains without retraining. Experiments demonstrate that DreamPolicy achieves average 90% success rates in training environments and an average of 20% higher success on unseen terrains than the prevalent method. It also generalizes to perturbed and composite scenarios where prior approaches collapse. By unifying offline data, diffusion-based trajectory synthesis, and policy optimization, DreamPolicy overcomes the "one task, one policy" bottleneck, establishing a paradigm for scalable, data-driven humanoid control.
ExFace: Expressive Facial Control for Humanoid Robots with Diffusion Transformers and Bootstrap Training
Apr 20, 2025



This paper presents a novel Expressive Facial Control (ExFace) method based on Diffusion Transformers, which achieves precise mapping from human facial blendshapes to bionic robot motor control. By incorporating an innovative model bootstrap training strategy, our approach not only generates high-quality facial expressions but also significantly improves accuracy and smoothness. Experimental results demonstrate that the proposed method outperforms previous methods in terms of accuracy, frame per second (FPS), and response time. Furthermore, we develop the ExFace dataset driven by human facial data. ExFace shows excellent real-time performance and natural expression rendering in applications such as robot performances and human-robot interactions, offering a new solution for bionic robot interaction.
SoFar: Language-Grounded Orientation Bridges Spatial Reasoning and Object Manipulation
Feb 18, 2025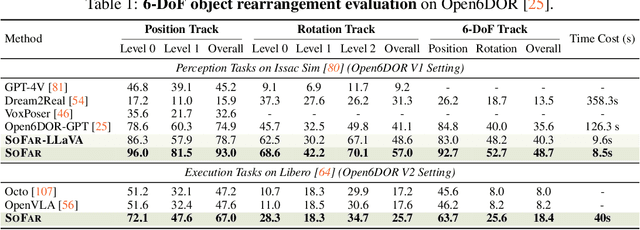

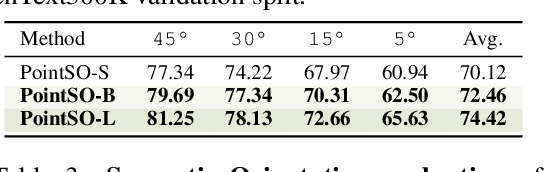
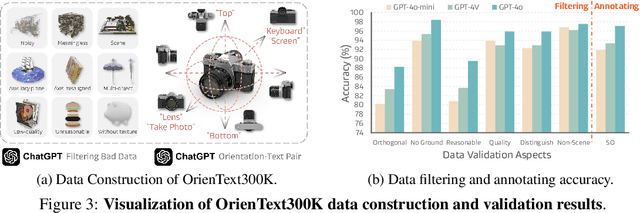
Spatial intelligence is a critical component of embodied AI, promoting robots to understand and interact with their environments. While recent advances have enhanced the ability of VLMs to perceive object locations and positional relationships, they still lack the capability to precisely understand object orientations-a key requirement for tasks involving fine-grained manipulations. Addressing this limitation not only requires geometric reasoning but also an expressive and intuitive way to represent orientation. In this context, we propose that natural language offers a more flexible representation space than canonical frames, making it particularly suitable for instruction-following robotic systems. In this paper, we introduce the concept of semantic orientation, which defines object orientations using natural language in a reference-frame-free manner (e.g., the ''plug-in'' direction of a USB or the ''handle'' direction of a knife). To support this, we construct OrienText300K, a large-scale dataset of 3D models annotated with semantic orientations that link geometric understanding to functional semantics. By integrating semantic orientation into a VLM system, we enable robots to generate manipulation actions with both positional and orientational constraints. Extensive experiments in simulation and real world demonstrate that our approach significantly enhances robotic manipulation capabilities, e.g., 48.7% accuracy on Open6DOR and 74.9% accuracy on SIMPLER.
CAST: Component-Aligned 3D Scene Reconstruction from an RGB Image
Feb 18, 2025Recovering high-quality 3D scenes from a single RGB image is a challenging task in computer graphics. Current methods often struggle with domain-specific limitations or low-quality object generation. To address these, we propose CAST (Component-Aligned 3D Scene Reconstruction from a Single RGB Image), a novel method for 3D scene reconstruction and recovery. CAST starts by extracting object-level 2D segmentation and relative depth information from the input image, followed by using a GPT-based model to analyze inter-object spatial relationships. This enables the understanding of how objects relate to each other within the scene, ensuring more coherent reconstruction. CAST then employs an occlusion-aware large-scale 3D generation model to independently generate each object's full geometry, using MAE and point cloud conditioning to mitigate the effects of occlusions and partial object information, ensuring accurate alignment with the source image's geometry and texture. To align each object with the scene, the alignment generation model computes the necessary transformations, allowing the generated meshes to be accurately placed and integrated into the scene's point cloud. Finally, CAST incorporates a physics-aware correction step that leverages a fine-grained relation graph to generate a constraint graph. This graph guides the optimization of object poses, ensuring physical consistency and spatial coherence. By utilizing Signed Distance Fields (SDF), the model effectively addresses issues such as occlusions, object penetration, and floating objects, ensuring that the generated scene accurately reflects real-world physical interactions. CAST can be leveraged in robotics, enabling efficient real-to-simulation workflows and providing realistic, scalable simulation environments for robotic systems.
AffordDP: Generalizable Diffusion Policy with Transferable Affordance
Dec 04, 2024



Diffusion-based policies have shown impressive performance in robotic manipulation tasks while struggling with out-of-domain distributions. Recent efforts attempted to enhance generalization by improving the visual feature encoding for diffusion policy. However, their generalization is typically limited to the same category with similar appearances. Our key insight is that leveraging affordances--manipulation priors that define "where" and "how" an agent interacts with an object--can substantially enhance generalization to entirely unseen object instances and categories. We introduce the Diffusion Policy with transferable Affordance (AffordDP), designed for generalizable manipulation across novel categories. AffordDP models affordances through 3D contact points and post-contact trajectories, capturing the essential static and dynamic information for complex tasks. The transferable affordance from in-domain data to unseen objects is achieved by estimating a 6D transformation matrix using foundational vision models and point cloud registration techniques. More importantly, we incorporate affordance guidance during diffusion sampling that can refine action sequence generation. This guidance directs the generated action to gradually move towards the desired manipulation for unseen objects while keeping the generated action within the manifold of action space. Experimental results from both simulated and real-world environments demonstrate that AffordDP consistently outperforms previous diffusion-based methods, successfully generalizing to unseen instances and categories where others fail.
3D-Adapter: Geometry-Consistent Multi-View Diffusion for High-Quality 3D Generation
Oct 24, 2024



Multi-view image diffusion models have significantly advanced open-domain 3D object generation. However, most existing models rely on 2D network architectures that lack inherent 3D biases, resulting in compromised geometric consistency. To address this challenge, we introduce 3D-Adapter, a plug-in module designed to infuse 3D geometry awareness into pretrained image diffusion models. Central to our approach is the idea of 3D feedback augmentation: for each denoising step in the sampling loop, 3D-Adapter decodes intermediate multi-view features into a coherent 3D representation, then re-encodes the rendered RGBD views to augment the pretrained base model through feature addition. We study two variants of 3D-Adapter: a fast feed-forward version based on Gaussian splatting and a versatile training-free version utilizing neural fields and meshes. Our extensive experiments demonstrate that 3D-Adapter not only greatly enhances the geometry quality of text-to-multi-view models such as Instant3D and Zero123++, but also enables high-quality 3D generation using the plain text-to-image Stable Diffusion. Furthermore, we showcase the broad application potential of 3D-Adapter by presenting high quality results in text-to-3D, image-to-3D, text-to-texture, and text-to-avatar tasks.
Point-SAM: Promptable 3D Segmentation Model for Point Clouds
Jun 25, 2024The development of 2D foundation models for image segmentation has been significantly advanced by the Segment Anything Model (SAM). However, achieving similar success in 3D models remains a challenge due to issues such as non-unified data formats, lightweight models, and the scarcity of labeled data with diverse masks. To this end, we propose a 3D promptable segmentation model (Point-SAM) focusing on point clouds. Our approach utilizes a transformer-based method, extending SAM to the 3D domain. We leverage part-level and object-level annotations and introduce a data engine to generate pseudo labels from SAM, thereby distilling 2D knowledge into our 3D model. Our model outperforms state-of-the-art models on several indoor and outdoor benchmarks and demonstrates a variety of applications, such as 3D annotation. Codes and demo can be found at https://github.com/zyc00/Point-SAM.
Evaluating Real-World Robot Manipulation Policies in Simulation
May 09, 2024



The field of robotics has made significant advances towards generalist robot manipulation policies. However, real-world evaluation of such policies is not scalable and faces reproducibility challenges, which are likely to worsen as policies broaden the spectrum of tasks they can perform. We identify control and visual disparities between real and simulated environments as key challenges for reliable simulated evaluation and propose approaches for mitigating these gaps without needing to craft full-fidelity digital twins of real-world environments. We then employ these approaches to create SIMPLER, a collection of simulated environments for manipulation policy evaluation on common real robot setups. Through paired sim-and-real evaluations of manipulation policies, we demonstrate strong correlation between policy performance in SIMPLER environments and in the real world. Additionally, we find that SIMPLER evaluations accurately reflect real-world policy behavior modes such as sensitivity to various distribution shifts. We open-source all SIMPLER environments along with our workflow for creating new environments at https://simpler-env.github.io to facilitate research on general-purpose manipulation policies and simulated evaluation frameworks.