 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction with Visual Primitives
May 21, 2026Vision-Language-Action (VLA) models have emerged as a promising paradigm for generalist robotic manipulation. A common design in current architectures maps language instructions and visual observations to actions in a single forward pass. While conceptually simple, this formulation entangles instruction comprehension, spatial scene understanding, and motor control within a single learning objective. As a result, the action expert must implicitly relearn cognitive and perceptual capabilities already present in the pretrained VLM, which can limit both learning efficiency and generalization. We introduce AVP (Action with Visual Primitives), an end-to-end architecture that implements this visual-primitive-centric interface: the VLM infers the next-stage target and emits visual-primitive tokens that condition a flow-matching action expert, with supervision derived from end-effector kinematics. Real-robot experiments on general pick-and-place tasks show that AVP improves the success rate by 27.61% over pi_0.5 and outperforms other recent methods, with consistent gains in data efficiency, spatial-compositional generalization, and object-level transfer.
Interference-Aware Multi-Task Unlearning
May 18, 2026Machine unlearning aims to remove the contribution of designated training data from a trained model while preserving performance on the remaining data. Existing work mainly focuses on single-task settings, whereas modern models often operate in multi-task setups with shared backbones, where removing supervision for one task or instance can unintentionally affect others. We introduce multi-task unlearning with two settings: full-task unlearning, which removes a target instance from all tasks, and partial-task unlearning, which removes supervision only from selected tasks. We show that shared parameters couple the forget and retain sets, causing task-level interference on non-target tasks and instance-level interference on other instances. To address this issue, we propose an interference-aware framework that combines task-aware gradient projection, which constrains updates within task-specific subspaces, with instance-level gradient orthogonalization, which reduces conflicts between forget and retain signals. Experiments on two multi-task computer vision benchmarks across five tasks show that our method achieves effective unlearning while maintaining strong generalization, reducing UIS compared with the strongest baseline by 30.3% in full-task unlearning and 52.9% in partial-task unlearning.
ReLE: A Scalable System and Structured Benchmark for Diagnosing Capability Anisotropy in Chinese LLMs
Jan 24, 2026Large Language Models (LLMs) have achieved rapid progress in Chinese language understanding, yet accurately evaluating their capabilities remains challenged by benchmark saturation and prohibitive computational costs. While static leaderboards provide snapshot rankings, they often mask the structural trade-offs between capabilities. In this work, we present ReLE (Robust Efficient Live Evaluation), a scalable system designed to diagnose Capability Anisotropy, the non-uniformity of model performance across domains. Using ReLE, we evaluate 304 models (189 commercial, 115 open-source) across a Domain $\times$ Capability orthogonal matrix comprising 207,843 samples. We introduce two methodological contributions to address current evaluation pitfalls: (1) A Symbolic-Grounded Hybrid Scoring Mechanism that eliminates embedding-based false positives in reasoning tasks; (2) A Dynamic Variance-Aware Scheduler based on Neyman allocation with noise correction, which reduces compute costs by 70\% compared to full-pass evaluations while maintaining a ranking correlation of $ρ=0.96$. Our analysis reveals that aggregate rankings are highly sensitive to weighting schemes: models exhibit a Rank Stability Amplitude (RSA) of 11.4 in ReLE versus $\sim$5.0 in traditional benchmarks, confirming that modern models are highly specialized rather than generally superior. We position ReLE not as a replacement for comprehensive static benchmarks, but as a high-frequency diagnostic monitor for the evolving model landscape.
Learning What to Write: Write-Gated KV for Efficient Long-Context Inference
Dec 22, 2025



Long-context LLM inference is bottlenecked by the quadratic attention complexity and linear KV cache growth. Prior approaches mitigate this via post-hoc selection or eviction but overlook the root inefficiency: indiscriminate writing to persistent memory. In this paper, we formalize KV cache management as a causal system of three primitives: KV Admission, Selection, and Eviction. We instantiate KV Admission via Write-Gated KV, a lightweight mechanism that learns to predict token utility before it enters the cache. By filtering out low-utility states early to maintain a compact global cache alongside a sliding local cache, Write-Gated KV reduces memory usage by 46-57% and delivers 3.03-3.45$\times$ prefill and 1.89-2.56$\times$ decode speedups on Llama model with negligible accuracy loss, all while remaining compatible with FlashAttention and paged-KV systems. These results demonstrate that learning what to write, is a principled and practical recipe for efficient long-context inference. Code is available at https://github.com/EMCLab-Sinica/WG-KV .
Embodied Tree of Thoughts: Deliberate Manipulation Planning with Embodied World Model
Dec 09, 2025World models have emerged as a pivotal component in robot manipulation planning, enabling agents to predict future environmental states and reason about the consequences of actions before execution. While video-generation models are increasingly adopted, they often lack rigorous physical grounding, leading to hallucinations and a failure to maintain consistency in long-horizon physical constraints. To address these limitations, we propose Embodied Tree of Thoughts (EToT), a novel Real2Sim2Real planning framework that leverages a physics-based interactive digital twin as an embodied world model. EToT formulates manipulation planning as a tree search expanded through two synergistic mechanisms: (1) Priori Branching, which generates diverse candidate execution paths based on semantic and spatial analysis; and (2) Reflective Branching, which utilizes VLMs to diagnose execution failures within the simulator and iteratively refine the planning tree with corrective actions. By grounding high-level reasoning in a physics simulator, our framework ensures that generated plans adhere to rigid-body dynamics and collision constraints. We validate EToT on a suite of short- and long-horizon manipulation tasks, where it consistently outperforms baselines by effectively predicting physical dynamics and adapting to potential failures. Website at https://embodied-tree-of-thoughts.github.io .
Dual Adversarial Alignment for Realistic Support-Query Shift Few-shot Learning
Sep 05, 2023Support-query shift few-shot learning aims to classify unseen examples (query set) to labeled data (support set) based on the learned embedding in a low-dimensional space under a distribution shift between the support set and the query set. However, in real-world scenarios the shifts are usually unknown and varied, making it difficult to estimate in advance. Therefore, in this paper, we propose a novel but more difficult challenge, RSQS, focusing on Realistic Support-Query Shift few-shot learning. The key feature of RSQS is that the individual samples in a meta-task are subjected to multiple distribution shifts in each meta-task. In addition, we propose a unified adversarial feature alignment method called DUal adversarial ALignment framework (DuaL) to relieve RSQS from two aspects, i.e., inter-domain bias and intra-domain variance. On the one hand, for the inter-domain bias, we corrupt the original data in advance and use the synthesized perturbed inputs to train the repairer network by minimizing distance in the feature level. On the other hand, for intra-domain variance, we proposed a generator network to synthesize hard, i.e., less similar, examples from the support set in a self-supervised manner and introduce regularized optimal transportation to derive a smooth optimal transportation plan. Lastly, a benchmark of RSQS is built with several state-of-the-art baselines among three datasets (CIFAR100, mini-ImageNet, and Tiered-Imagenet). Experiment results show that DuaL significantly outperforms the state-of-the-art methods in our benchmark.
Filter Pruning via Filters Similarity in Consecutive Layers
Apr 26, 2023



Filter pruning is widely adopted to compress and accelerate the Convolutional Neural Networks (CNNs), but most previous works ignore the relationship between filters and channels in different layers. Processing each layer independently fails to utilize the collaborative relationship across layers. In this paper, we intuitively propose a novel pruning method by explicitly leveraging the Filters Similarity in Consecutive Layers (FSCL). FSCL compresses models by pruning filters whose corresponding features are more worthless in the model. The extensive experiments demonstrate the effectiveness of FSCL, and it yields remarkable improvement over state-of-the-art on accuracy, FLOPs and parameter reduction on several benchmark models and datasets.
STAGE: Span Tagging and Greedy Inference Scheme for Aspect Sentiment Triplet Extraction
Nov 29, 2022



Aspect Sentiment Triplet Extraction (ASTE) has become an emerging task in sentiment analysis research, aiming to extract triplets of the aspect term, its corresponding opinion term, and its associated sentiment polarity from a given sentence. Recently, many neural networks based models with different tagging schemes have been proposed, but almost all of them have their limitations: heavily relying on 1) prior assumption that each word is only associated with a single role (e.g., aspect term, or opinion term, etc. ) and 2) word-level interactions and treating each opinion/aspect as a set of independent words. Hence, they perform poorly on the complex ASTE task, such as a word associated with multiple roles or an aspect/opinion term with multiple words. Hence, we propose a novel approach, Span TAgging and Greedy infErence (STAGE), to extract sentiment triplets in span-level, where each span may consist of multiple words and play different roles simultaneously. To this end, this paper formulates the ASTE task as a multi-class span classification problem. Specifically, STAGE generates more accurate aspect sentiment triplet extractions via exploring span-level information and constraints, which consists of two components, namely, span tagging scheme and greedy inference strategy. The former tag all possible candidate spans based on a newly-defined tagging set. The latter retrieves the aspect/opinion term with the maximum length from the candidate sentiment snippet to output sentiment triplets. Furthermore, we propose a simple but effective model based on the STAGE, which outperforms the state-of-the-arts by a large margin on four widely-used datasets. Moreover, our STAGE can be easily generalized to other pair/triplet extraction tasks, which also demonstrates the superiority of the proposed scheme STAGE.
HCL-TAT: A Hybrid Contrastive Learning Method for Few-shot Event Detection with Task-Adaptive Threshold
Oct 17, 2022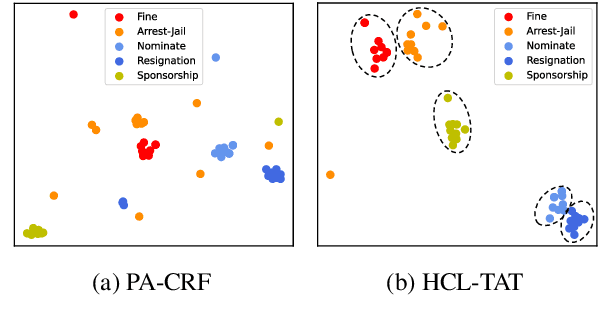
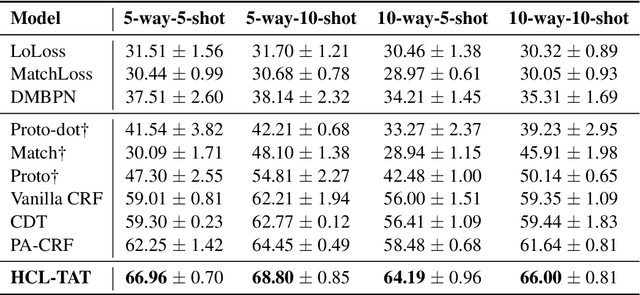
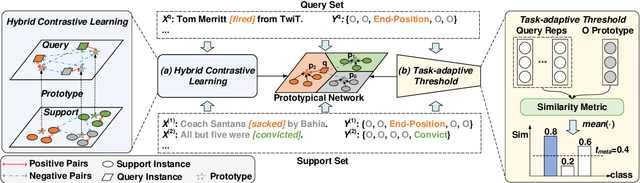
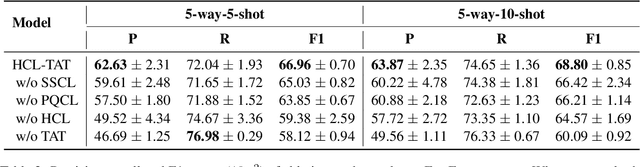
Conventional event detection models under supervised learning settings suffer from the inability of transfer to newly-emerged event types owing to lack of sufficient annotations. A commonly-adapted solution is to follow a identify-then-classify manner, which first identifies the triggers and then converts the classification task via a few-shot learning paradigm. However, these methods still fall far short of expectations due to: (i) insufficient learning of discriminative representations in low-resource scenarios, and (ii) trigger misidentification caused by the overlap of the learned representations of triggers and non-triggers. To address the problems, in this paper, we propose a novel Hybrid Contrastive Learning method with a Task-Adaptive Threshold (abbreviated as HCLTAT), which enables discriminative representation learning with a two-view contrastive loss (support-support and prototype-query), and devises a easily-adapted threshold to alleviate misidentification of triggers. Extensive experiments on the benchmark dataset FewEvent demonstrate the superiority of our method to achieve better results compared to the state-of-the-arts. All the code and data of this paper will be available for online public access.
Multi-level Contrastive Learning Framework for Sequential Recommendation
Aug 27, 2022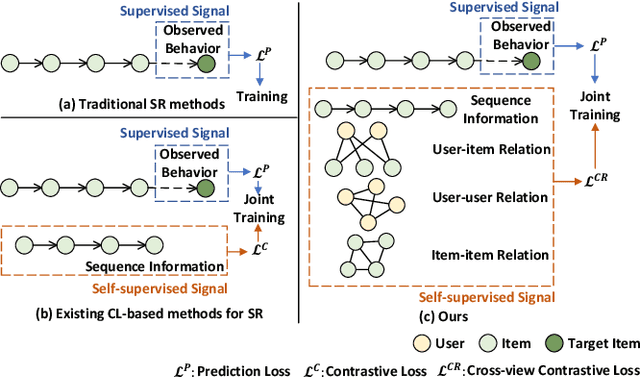
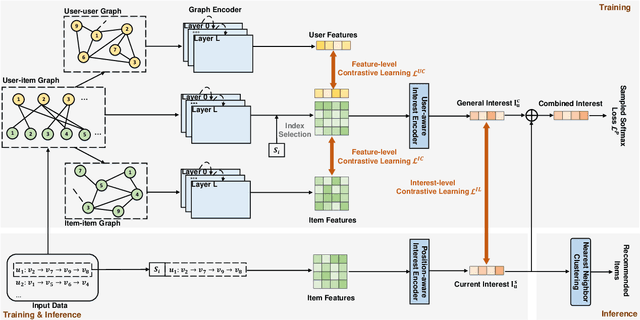
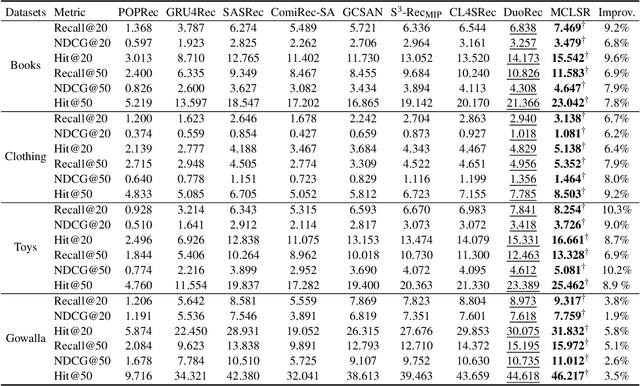
Sequential recommendation (SR) aims to predict the subsequent behaviors of users by understanding their successive historical behaviors. Recently, some methods for SR are devoted to alleviating the data sparsity problem (i.e., limited supervised signals for training), which take account of contrastive learning to incorporate self-supervised signals into SR. Despite their achievements, it is far from enough to learn informative user/item embeddings due to the inadequacy modeling of complex collaborative information and co-action information, such as user-item relation, user-user relation, and item-item relation. In this paper, we study the problem of SR and propose a novel multi-level contrastive learning framework for sequential recommendation, named MCLSR. Different from the previous contrastive learning-based methods for SR, MCLSR learns the representations of users and items through a cross-view contrastive learning paradigm from four specific views at two different levels (i.e., interest- and feature-level). Specifically, the interest-level contrastive mechanism jointly learns the collaborative information with the sequential transition patterns, and the feature-level contrastive mechanism re-observes the relation between users and items via capturing the co-action information (i.e., co-occurrence). Extensive experiments on four real-world datasets show that the proposed MCLSR outperforms the state-of-the-art methods consistently.