 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Precise Video Language with Human-AI Oversight
Apr 22, 2026Video-language models (VLMs) learn to reason about the dynamic visual world through natural language. We introduce a suite of open datasets, benchmarks, and recipes for scalable oversight that enable precise video captioning. First, we define a structured specification for describing subjects, scenes, motion, spatial, and camera dynamics, grounded by hundreds of carefully defined visual primitives developed with professional video creators such as filmmakers. Next, to curate high-quality captions, we introduce CHAI (Critique-based Human-AI Oversight), a framework where trained experts critique and revise model-generated pre-captions into improved post-captions. This division of labor improves annotation accuracy and efficiency by offloading text generation to models, allowing humans to better focus on verification. Additionally, these critiques and preferences between pre- and post-captions provide rich supervision for improving open-source models (Qwen3-VL) on caption generation, reward modeling, and critique generation through SFT, DPO, and inference-time scaling. Our ablations show that critique quality in precision, recall, and constructiveness, ensured by our oversight framework, directly governs downstream performance. With modest expert supervision, the resulting model outperforms closed-source models such as Gemini-3.1-Pro. Finally, we apply our approach to re-caption large-scale professional videos (e.g., films, commercials, games) and fine-tune video generation models such as Wan to better follow detailed prompts of up to 400 words, achieving finer control over cinematography including camera motion, angle, lens, focus, point of view, and framing. Our results show that precise specification and human-AI oversight are key to professional-level video understanding and generation. Data and code are available on our project page: https://linzhiqiu.github.io/papers/chai/
An Intelligent Assistant for Converting City Requirements to Formal Specification
Jun 14, 2022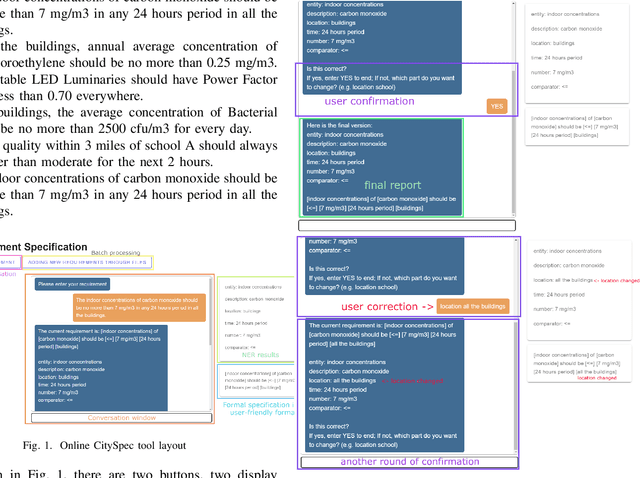

As more and more monitoring systems have been deployed to smart cities, there comes a higher demand for converting new human-specified requirements to machine-understandable formal specifications automatically. However, these human-specific requirements are often written in English and bring missing, inaccurate, or ambiguous information. In this paper, we present CitySpec, an intelligent assistant system for requirement specification in smart cities. CitySpec not only helps overcome the language differences brought by English requirements and formal specifications, but also offers solutions to those missing, inaccurate, or ambiguous information. The goal of this paper is to demonstrate how CitySpec works. Specifically, we present three demos: (1) interactive completion of requirements in CitySpec; (2) human-in-the-loop correction while CitySepc encounters exceptions; (3) online learning in CitySpec.
CitySpec: An Intelligent Assistant System for Requirement Specification in Smart Cities
Jun 07, 2022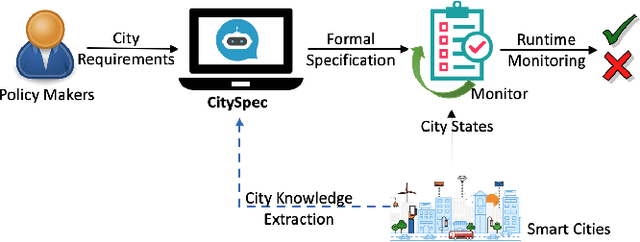
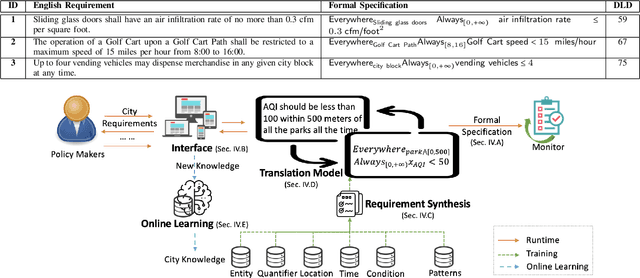
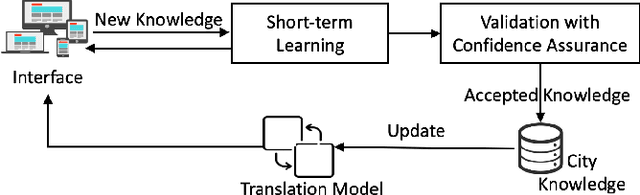
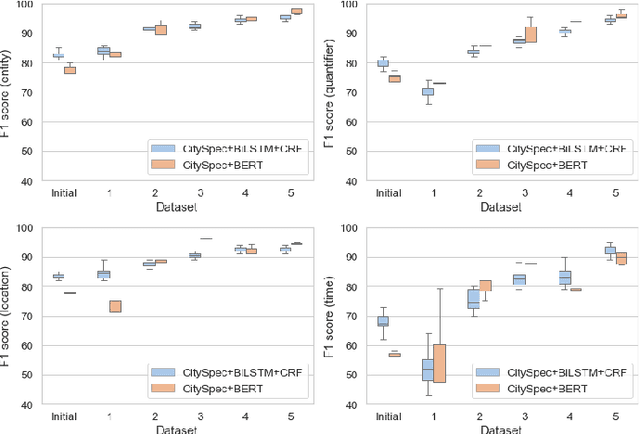
An increasing number of monitoring systems have been developed in smart cities to ensure that real-time operations of a city satisfy safety and performance requirements. However, many existing city requirements are written in English with missing, inaccurate, or ambiguous information. There is a high demand for assisting city policy makers in converting human-specified requirements to machine-understandable formal specifications for monitoring systems. To tackle this limitation, we build CitySpec, the first intelligent assistant system for requirement specification in smart cities. To create CitySpec, we first collect over 1,500 real-world city requirements across different domains from over 100 cities and extract city-specific knowledge to generate a dataset of city vocabulary with 3,061 words. We also build a translation model and enhance it through requirement synthesis and develop a novel online learning framework with validation under uncertainty. The evaluation results on real-world city requirements show that CitySpec increases the sentence-level accuracy of requirement specification from 59.02% to 86.64%, and has strong adaptability to a new city and a new domain (e.g., F1 score for requirements in Seattle increases from 77.6% to 93.75% with online learning).