 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Grid Rendering Networks for 3D Object Detection in Point Clouds
Jul 04, 2020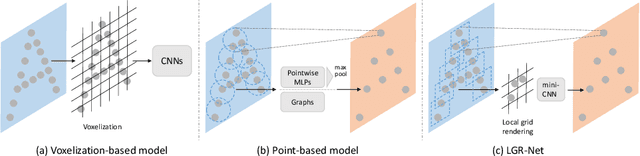
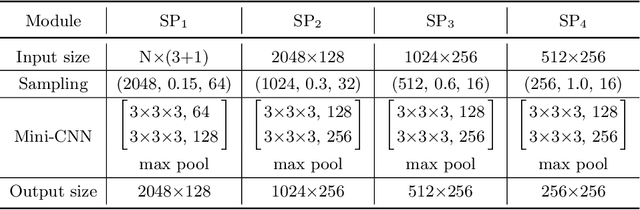
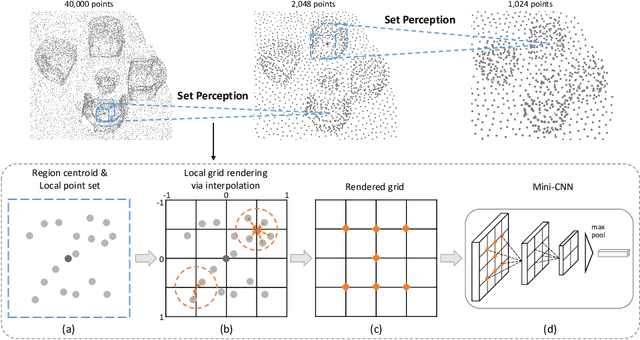
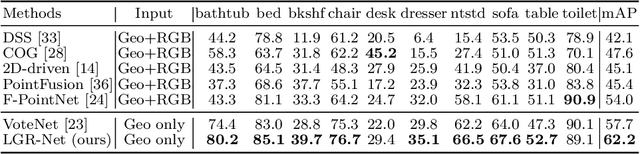
The performance of 3D object detection models over point clouds highly depends on their capability of modeling local geometric patterns. Conventional point-based models exploit local patterns through a symmetric function (e.g. max pooling) or based on graphs, which easily leads to loss of fine-grained geometric structures. Regarding capturing spatial patterns, CNNs are powerful but it would be computationally costly to directly apply convolutions on point data after voxelizing the entire point clouds to a dense regular 3D grid. In this work, we aim to improve performance of point-based models by enhancing their pattern learning ability through leveraging CNNs while preserving computational efficiency. We propose a novel and principled Local Grid Rendering (LGR) operation to render the small neighborhood of a subset of input points into a low-resolution 3D grid independently, which allows small-size CNNs to accurately model local patterns and avoids convolutions over a dense grid to save computation cost. With the LGR operation, we introduce a new generic backbone called LGR-Net for point cloud feature extraction with simple design and high efficiency. We validate LGR-Net for 3D object detection on the challenging ScanNet and SUN RGB-D datasets. It advances state-of-the-art results significantly by 5.5 and 4.5 mAP, respectively, with only slight increased computation overhead.
Inference Stage Optimization for Cross-scenario 3D Human Pose Estimation
Jul 04, 2020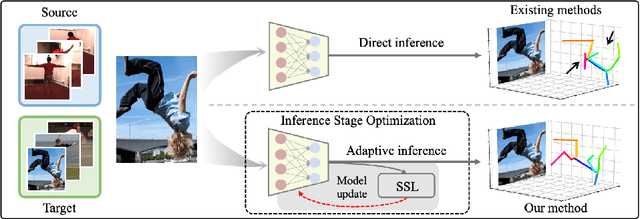
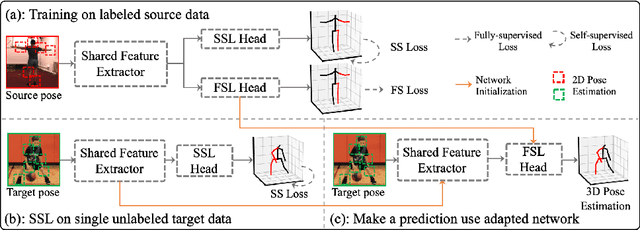
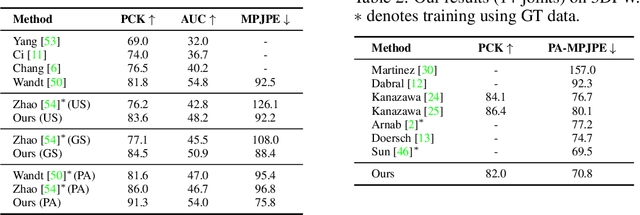
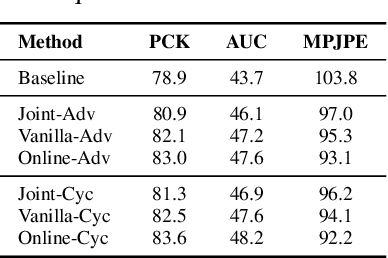
Existing 3D human pose estimation models suffer performance drop when applying to new scenarios with unseen poses due to their limited generalizability. In this work, we propose a novel framework, Inference Stage Optimization (ISO), for improving the generalizability of 3D pose models when source and target data come from different pose distributions. Our main insight is that the target data, even though not labeled, carry valuable priors about their underlying distribution. To exploit such information, the proposed ISO performs geometry-aware self-supervised learning (SSL) on each single target instance and updates the 3D pose model before making prediction. In this way, the model can mine distributional knowledge about the target scenario and quickly adapt to it with enhanced generalization performance. In addition, to handle sequential target data, we propose an online mode for implementing our ISO framework via streaming the SSL, which substantially enhances its effectiveness. We systematically analyze why and how our ISO framework works on diverse benchmarks under cross-scenario setup. Remarkably, it yields new state-of-the-art of 83.6% 3D PCK on MPI-INF-3DHP, improving upon the previous best result by 9.7%. Code will be released.
Overcoming Classifier Imbalance for Long-tail Object Detection with Balanced Group Softmax
Jun 18, 2020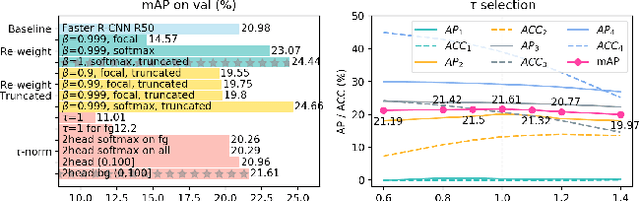
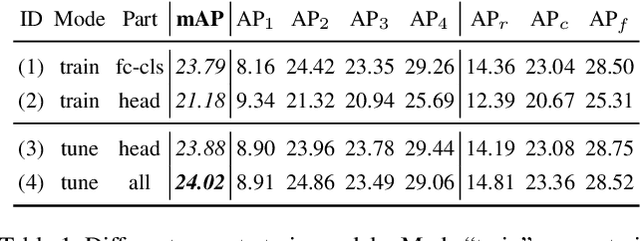
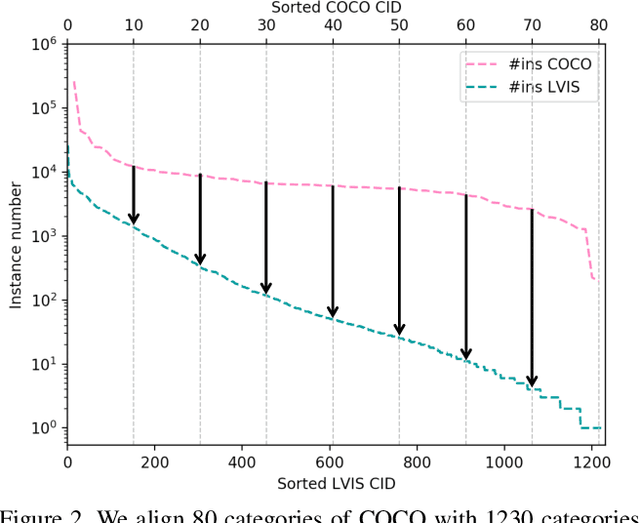
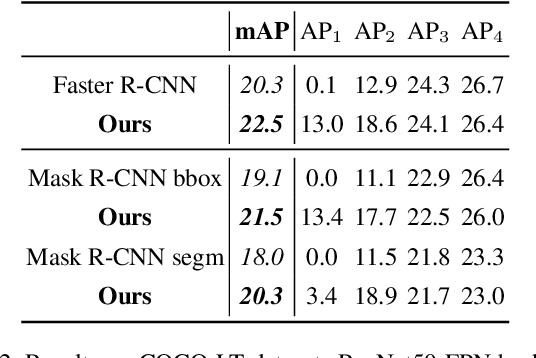
Solving long-tail large vocabulary object detection with deep learning based models is a challenging and demanding task, which is however under-explored.In this work, we provide the first systematic analysis on the underperformance of state-of-the-art models in front of long-tail distribution. We find existing detection methods are unable to model few-shot classes when the dataset is extremely skewed, which can result in classifier imbalance in terms of parameter magnitude. Directly adapting long-tail classification models to detection frameworks can not solve this problem due to the intrinsic difference between detection and classification.In this work, we propose a novel balanced group softmax (BAGS) module for balancing the classifiers within the detection frameworks through group-wise training. It implicitly modulates the training process for the head and tail classes and ensures they are both sufficiently trained, without requiring any extra sampling for the instances from the tail classes.Extensive experiments on the very recent long-tail large vocabulary object recognition benchmark LVIS show that our proposed BAGS significantly improves the performance of detectors with various backbones and frameworks on both object detection and instance segmentation. It beats all state-of-the-art methods transferred from long-tail image classification and establishes new state-of-the-art.Code is available at https://github.com/FishYuLi/BalancedGroupSoftmax.
Multi-Miner: Object-Adaptive Region Mining for Weakly-Supervised Semantic Segmentation
Jun 14, 2020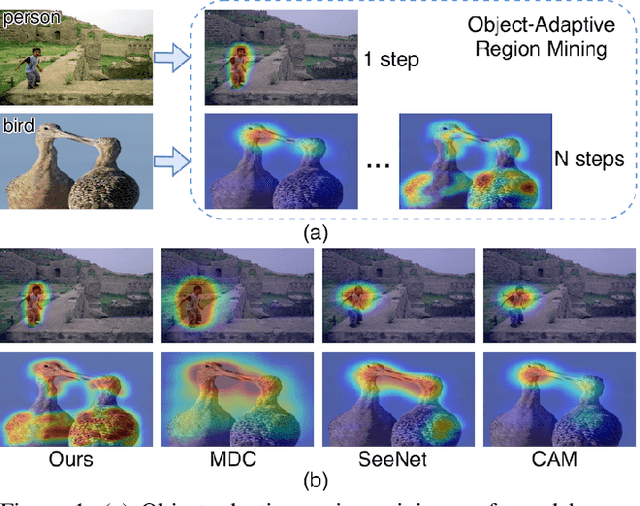
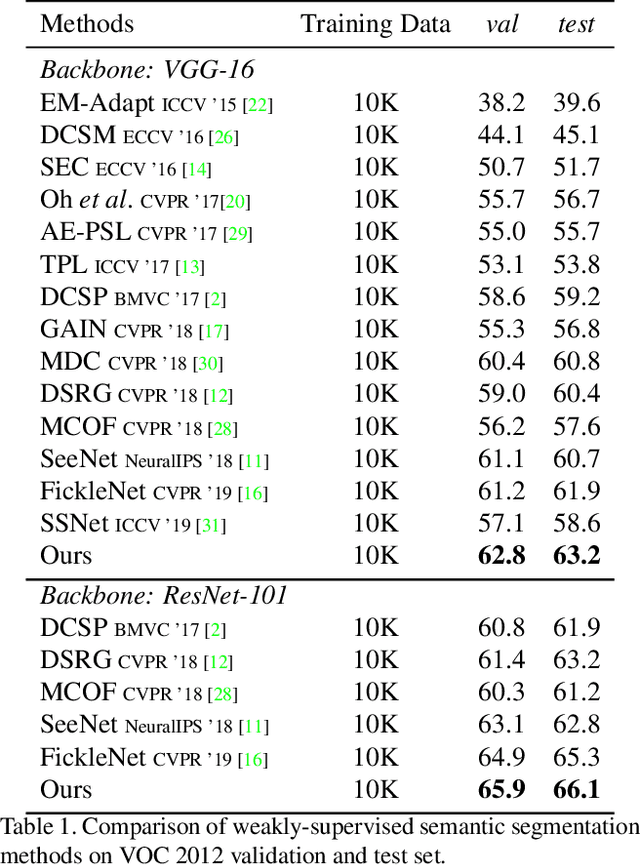
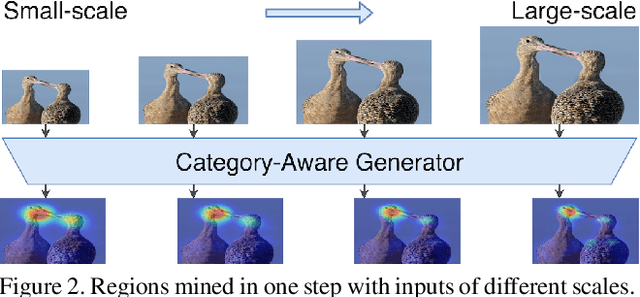

Object region mining is a critical step for weakly-supervised semantic segmentation. Most recent methods mine the object regions by expanding the seed regions localized by class activation maps. They generally do not consider the sizes of objects and apply a monotonous procedure to mining all the object regions. Thus their mined regions are often insufficient in number and scale for large objects, and on the other hand easily contaminated by surrounding backgrounds for small objects. In this paper, we propose a novel multi-miner framework to perform a region mining process that adapts to diverse object sizes and is thus able to mine more integral and finer object regions. Specifically, our multi-miner leverages a parallel modulator to check whether there are remaining object regions for each single object, and guide a category-aware generator to mine the regions of each object independently. In this way, the multi-miner adaptively takes more steps for large objects and fewer steps for small objects. Experiment results demonstrate that the multi-miner offers better region mining results and helps achieve better segmentation performance than state-of-the-art weakly-supervised semantic segmentation methods.
Effective Training Strategies for Deep Graph Neural Networks
Jun 12, 2020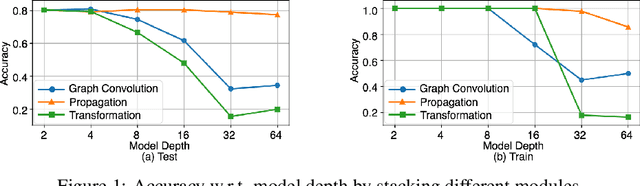
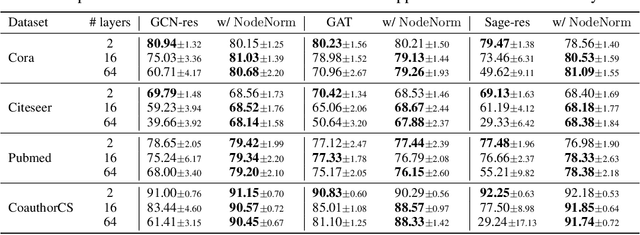
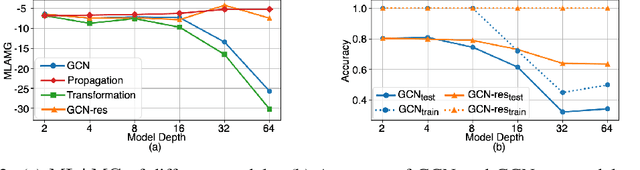
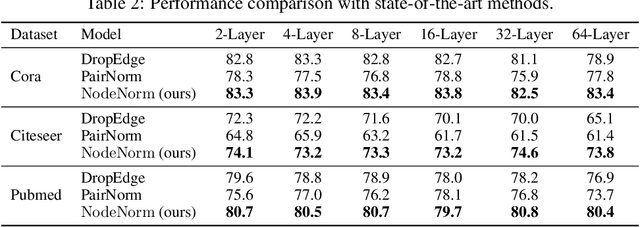
Graph Neural Networks (GNNs) tend to suffer performance degradation as model depth increases, which is usually attributed in previous works to the oversmoothing problem. However, we find that although oversmoothing is a contributing factor, the main reasons for this phenomenon are training difficulty and overfitting, which we study by experimentally investigating Graph Convolutional Networks (GCNs), a representative GNN architecture. We find that training difficulty is caused by gradient vanishing and can be solved by adding residual connections. More importantly, overfitting is the major obstacle for deep GCNs and cannot be effectively solved by existing regularization techniques. Deep GCNs also suffer training instability, which slows down the training process. To address overfitting and training instability, we propose Node Normalization (NodeNorm), which normalizes each node using its own statistics in model training. The proposed NodeNorm regularizes deep GCNs by discouraging feature-wise correlation of hidden embeddings and increasing model smoothness with respect to input node features, and thus effectively reduces overfitting. Additionally, it stabilizes the training process and hence speeds up the training. Extensive experiments demonstrate that our NodeNorm method generalizes well to other GNN architectures, enabling deep GNNs to compete with and even outperform shallow ones. Code is publicly available.
Boosting Few-Shot Learning With Adaptive Margin Loss
May 28, 2020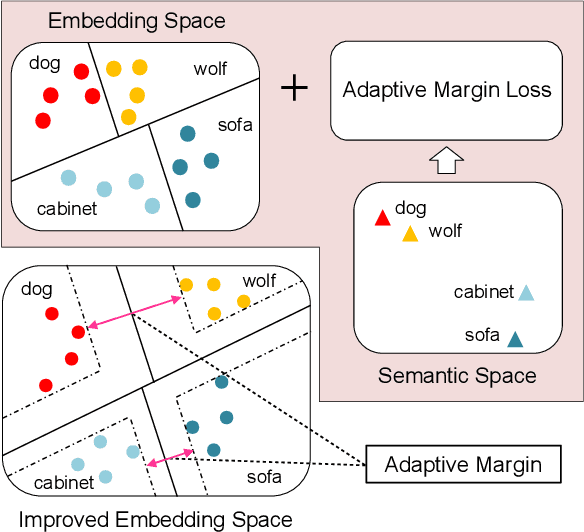
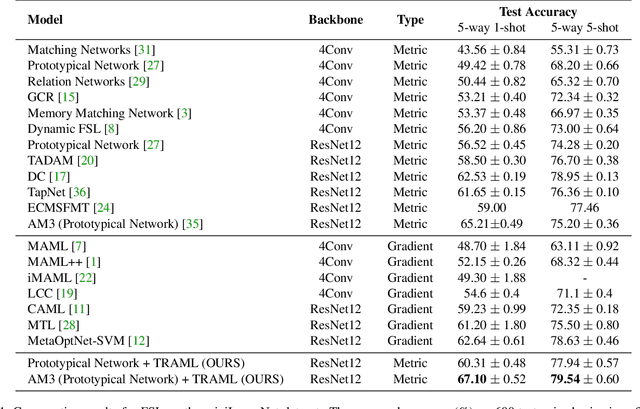
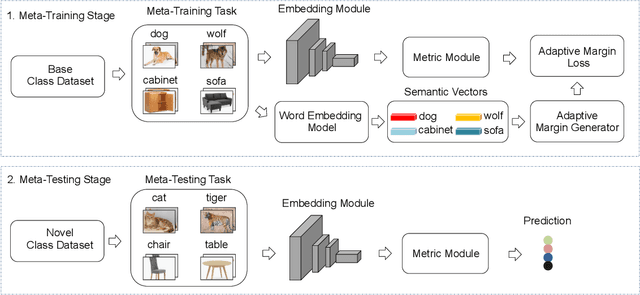
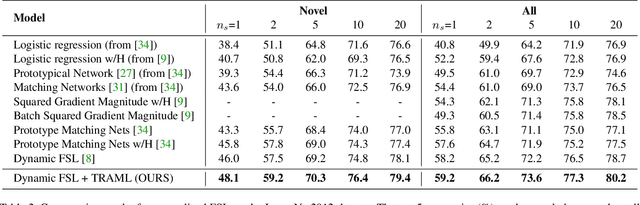
Few-shot learning (FSL) has attracted increasing attention in recent years but remains challenging, due to the intrinsic difficulty in learning to generalize from a few examples. This paper proposes an adaptive margin principle to improve the generalization ability of metric-based meta-learning approaches for few-shot learning problems. Specifically, we first develop a class-relevant additive margin loss, where semantic similarity between each pair of classes is considered to separate samples in the feature embedding space from similar classes. Further, we incorporate the semantic context among all classes in a sampled training task and develop a task-relevant additive margin loss to better distinguish samples from different classes. Our adaptive margin method can be easily extended to a more realistic generalized FSL setting. Extensive experiments demonstrate that the proposed method can boost the performance of current metric-based meta-learning approaches, under both the standard FSL and generalized FSL settings.
RAIN: Robust and Accurate Classification Networks with Randomization and Enhancement
Apr 24, 2020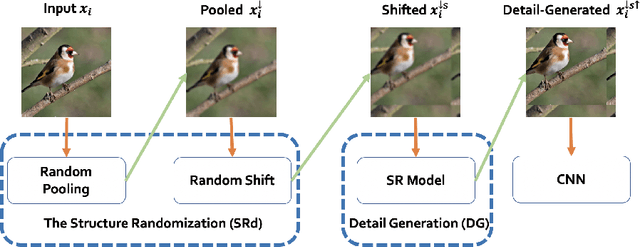
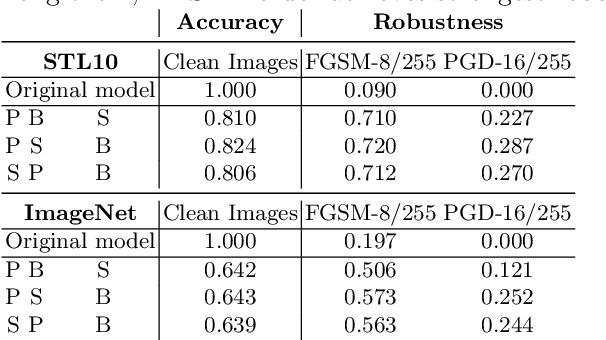

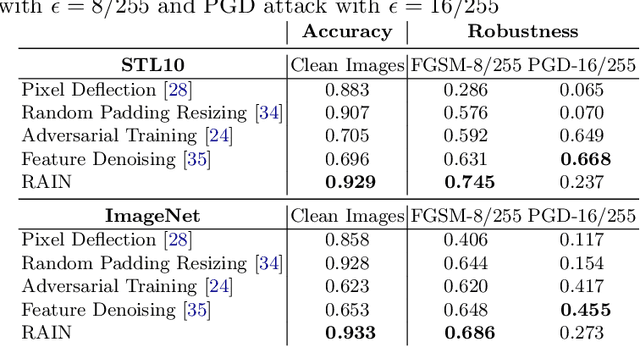
Along with the extensive applications of CNN models for classification, there has been a growing requirement for their robustness against adversarial examples. In recent years, many adversarial defense methods have been introduced, but most of them have to sacrifice classification accuracy on clean samples to achieve better robustness of CNNs. In this paper, we propose a novel framework to improve robustness and meanwhile retain the accuracy of given classification CNN models, termed as RAIN, which consists of two conjugate modules: structured randomization (SRd) and detail generation (DG). Specifically, the SRd module randomly downsamples and shifts the input, which can destroy the structure of adversarial perturbations so as to improve the model robustness. However, such operations also incur accuracy drop inevitably. Through our empirical study, the resultant image of the SRd module suffers loss of high-frequency details that are crucial for model accuracy. To remedy the accuracy drop, RAIN couples a deep super-resolution model as the DG module for recovering rich details in the resultant image. We evaluate RAIN on STL10 and the ImageNet datasets, and experiment results well demonstrate its great robustness against adversarial examples as well as comparable classification accuracy to non-robustified counterparts on clean samples. Our framework is simple, effective and substantially extends the application of adversarial defense techniques to realistic scenarios where clean and adversarial samples are mixed.
PANDA: Prototypical Unsupervised Domain Adaptation
Apr 12, 2020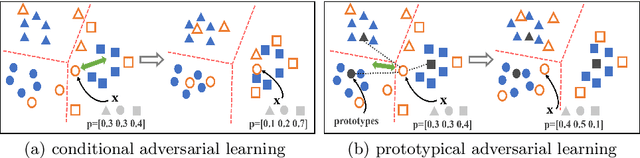
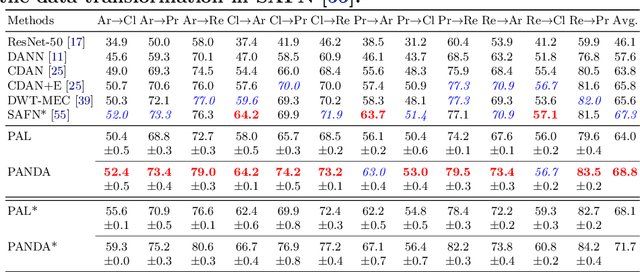
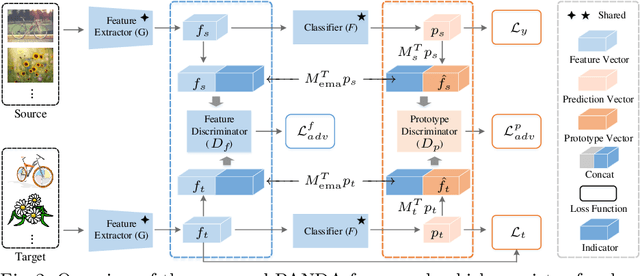
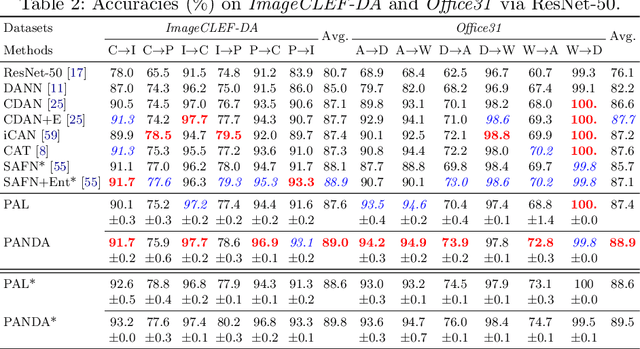
Previous adversarial domain alignment methods for unsupervised domain adaptation (UDA) pursue conditional domain alignment via intermediate pseudo labels. However, these pseudo labels are generated by independent instances without considering the global data structure and tend to be noisy, making them unreliable for adversarial domain adaptation. Compared with pseudo labels, prototypes are more reliable to represent the data structure resistant to the domain shift since they are summarized over all the relevant instances. In this work, we attempt to calibrate the noisy pseudo labels with prototypes. Specifically, we first obtain a reliable prototypical representation for each instance by multiplying the soft instance predictions with the global prototypes. Based on the prototypical representation, we propose a novel Prototypical Adversarial Learning (PAL) scheme and exploit it to align both feature representations and intermediate prototypes across domains. Besides, with the intermediate prototypes as a proxy, we further minimize the intra-class variance in the target domain to adaptively improve the pseudo labels. Integrating the three objectives, we develop an unified framework termed PrototypicAl uNsupervised Domain Adaptation (PANDA) for UDA. Experiments show that PANDA achieves state-of-the-art or competitive results on multiple UDA benchmarks including both object recognition and semantic segmentation tasks.
Strip Pooling: Rethinking Spatial Pooling for Scene Parsing
Mar 30, 2020
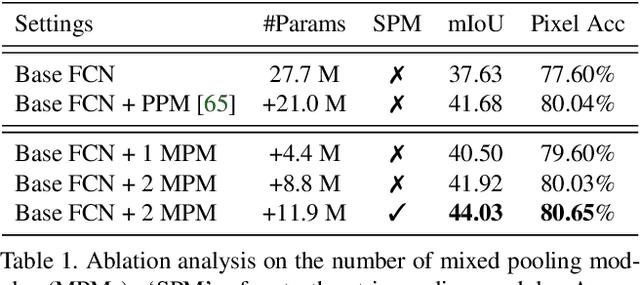
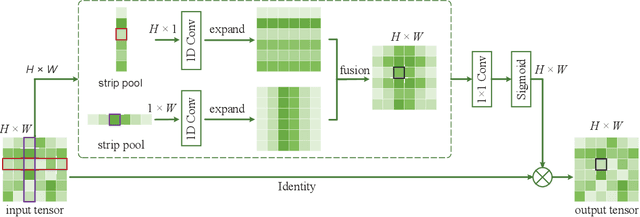
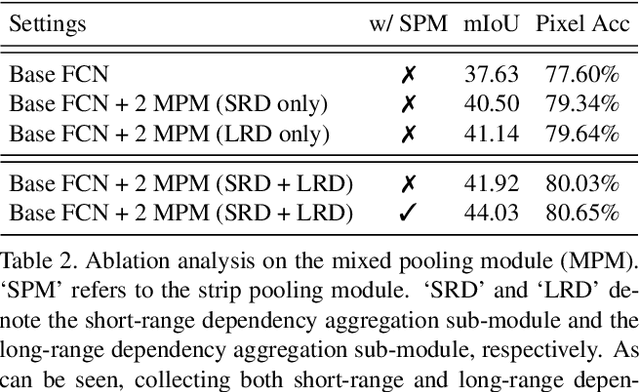
Spatial pooling has been proven highly effective in capturing long-range contextual information for pixel-wise prediction tasks, such as scene parsing. In this paper, beyond conventional spatial pooling that usually has a regular shape of NxN, we rethink the formulation of spatial pooling by introducing a new pooling strategy, called strip pooling, which considers a long but narrow kernel, i.e., 1xN or Nx1. Based on strip pooling, we further investigate spatial pooling architecture design by 1) introducing a new strip pooling module that enables backbone networks to efficiently model long-range dependencies, 2) presenting a novel building block with diverse spatial pooling as a core, and 3) systematically comparing the performance of the proposed strip pooling and conventional spatial pooling techniques. Both novel pooling-based designs are lightweight and can serve as an efficient plug-and-play module in existing scene parsing networks. Extensive experiments on popular benchmarks (e.g., ADE20K and Cityscapes) demonstrate that our simple approach establishes new state-of-the-art results. Code is made available at https://github.com/Andrew-Qibin/SPNet.
A Balanced and Uncertainty-aware Approach for Partial Domain Adaptation
Mar 05, 2020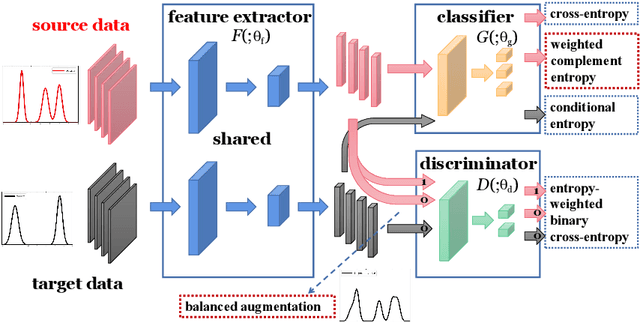
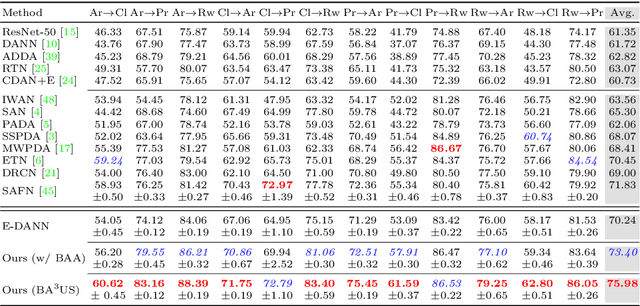
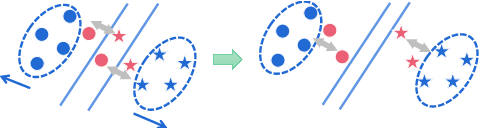
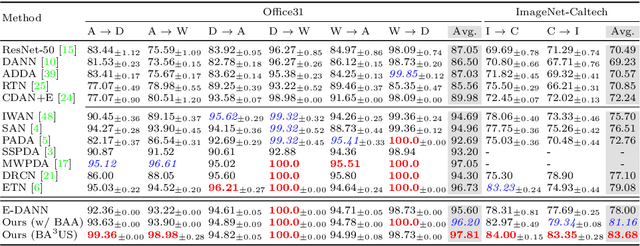
This work addresses the unsupervised domain adaptation problem, especially for the partial scenario where the class labels in the target domain are only a subset of those in the source domain. Such a partial transfer setting sounds realistic but challenging while existing methods always suffer from two key problems, i.e., negative transfer and uncertainty propagation. In this paper, we build on domain adversarial learning and propose a novel domain adaptation method BA$^3$US with two new techniques termed Balanced Adversarial Alignment (BAA) and Adaptive Uncertainty Suppression (AUS), respectively. On one hand, negative transfer results in that target samples are misclassified to the classes only present in the source domain. To address this issue, BAA aims to pursue the balance between label distributions across domains in a quite simple manner. Specifically, it randomly leverages a few source samples to augment the smaller target domain during domain alignment so that classes in different domains are symmetric. On the other hand, a source sample is denoted as uncertain if there is an incorrect class that has a relatively high prediction score. Such uncertainty is easily propagated to the unlabeled target data around it during alignment, which severely deteriorates the adaptation performance. Thus, AUS emphasizes uncertain samples and exploits an adaptive weighted complement entropy objective to expect that incorrect classes have the uniform and low prediction scores. Experimental results on multiple benchmarks demonstrate that BA$^3$US surpasses state-of-the-arts for partial domain adaptation tasks.