 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSBEED: Convergent Reinforcement Learning with Nonlinear Function Approximation
Jun 05, 2018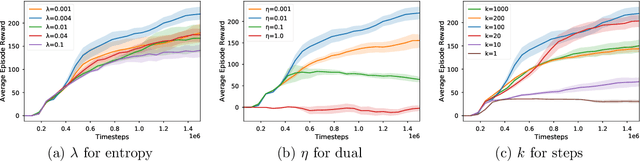
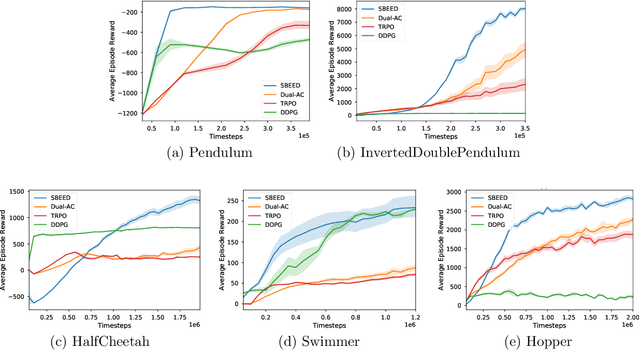
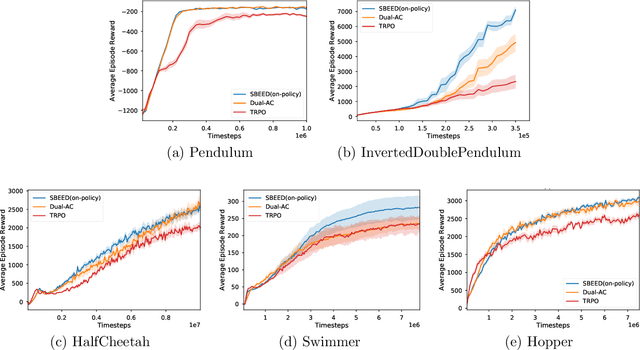
When function approximation is used, solving the Bellman optimality equation with stability guarantees has remained a major open problem in reinforcement learning for decades. The fundamental difficulty is that the Bellman operator may become an expansion in general, resulting in oscillating and even divergent behavior of popular algorithms like Q-learning. In this paper, we revisit the Bellman equation, and reformulate it into a novel primal-dual optimization problem using Nesterov's smoothing technique and the Legendre-Fenchel transformation. We then develop a new algorithm, called Smoothed Bellman Error Embedding, to solve this optimization problem where any differentiable function class may be used. We provide what we believe to be the first convergence guarantee for general nonlinear function approximation, and analyze the algorithm's sample complexity. Empirically, our algorithm compares favorably to state-of-the-art baselines in several benchmark control problems.
A Learning-to-Infer Method for Real-Time Power Grid Topology Identification
Oct 21, 2017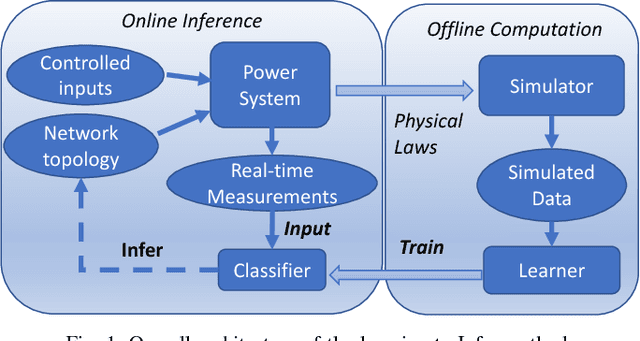
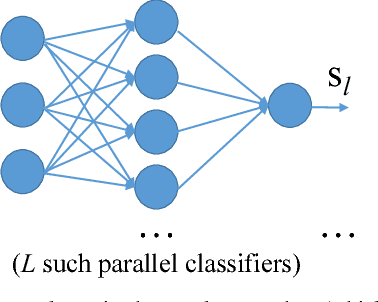
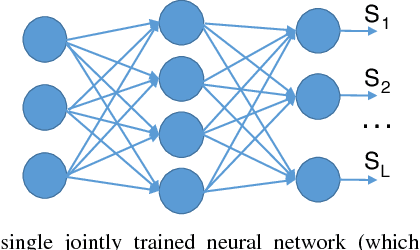
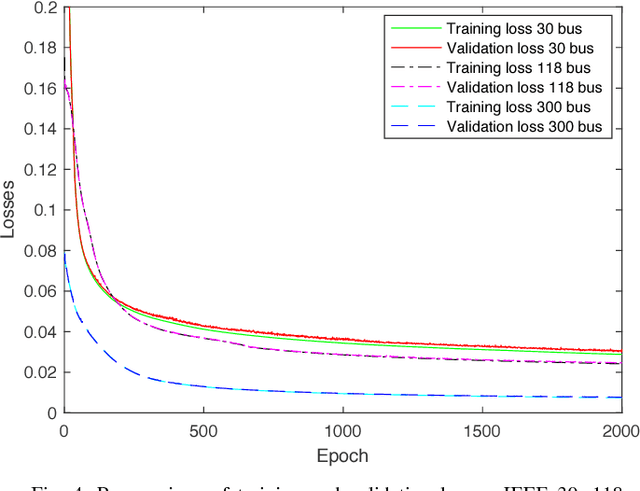
Identifying arbitrary topologies of power networks in real time is a computationally hard problem due to the number of hypotheses that grows exponentially with the network size. A new "Learning-to-Infer" variational inference method is developed for efficient inference of every line status in the network. Optimizing the variational model is transformed to and solved as a discriminative learning problem based on Monte Carlo samples generated with power flow simulations. A major advantage of the developed Learning-to-Infer method is that the labeled data used for training can be generated in an arbitrarily large amount fast and at very little cost. As a result, the power of offline training is fully exploited to learn very complex classifiers for effective real-time topology identification. The proposed methods are evaluated in the IEEE 30, 118 and 300 bus systems. Excellent performance in identifying arbitrary power network topologies in real time is achieved even with relatively simple variational models and a reasonably small amount of data.
Stochastic Variance Reduction Methods for Policy Evaluation
Jun 09, 2017
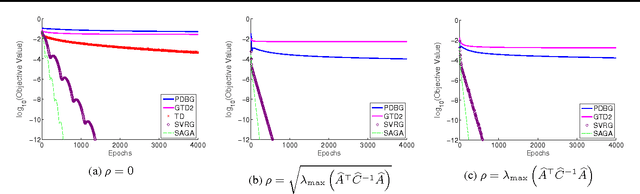
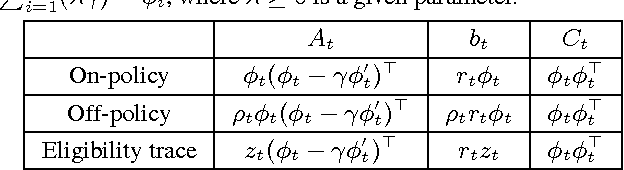
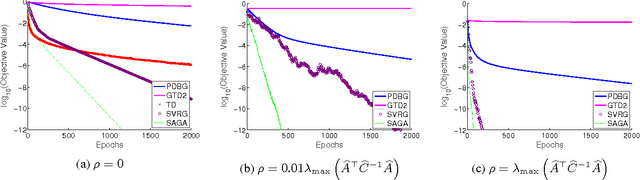
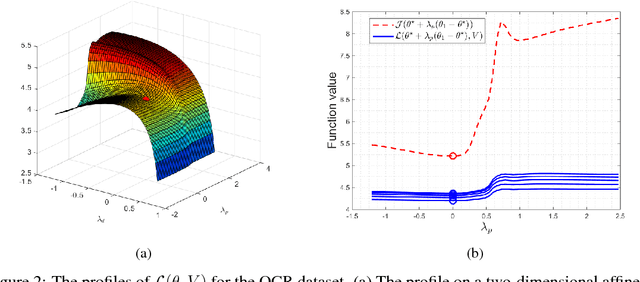
Policy evaluation is a crucial step in many reinforcement-learning procedures, which estimates a value function that predicts states' long-term value under a given policy. In this paper, we focus on policy evaluation with linear function approximation over a fixed dataset. We first transform the empirical policy evaluation problem into a (quadratic) convex-concave saddle point problem, and then present a primal-dual batch gradient method, as well as two stochastic variance reduction methods for solving the problem. These algorithms scale linearly in both sample size and feature dimension. Moreover, they achieve linear convergence even when the saddle-point problem has only strong concavity in the dual variables but no strong convexity in the primal variables. Numerical experiments on benchmark problems demonstrate the effectiveness of our methods.
Unsupervised Sequence Classification using Sequential Output Statistics
May 26, 2017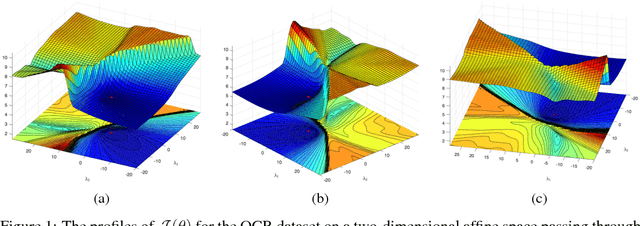

We consider learning a sequence classifier without labeled data by using sequential output statistics. The problem is highly valuable since obtaining labels in training data is often costly, while the sequential output statistics (e.g., language models) could be obtained independently of input data and thus with low or no cost. To address the problem, we propose an unsupervised learning cost function and study its properties. We show that, compared to earlier works, it is less inclined to be stuck in trivial solutions and avoids the need for a strong generative model. Although it is harder to optimize in its functional form, a stochastic primal-dual gradient method is developed to effectively solve the problem. Experiment results on real-world datasets demonstrate that the new unsupervised learning method gives drastically lower errors than other baseline methods. Specifically, it reaches test errors about twice of those obtained by fully supervised learning.
Character-level Deep Conflation for Business Data Analytics
Feb 08, 2017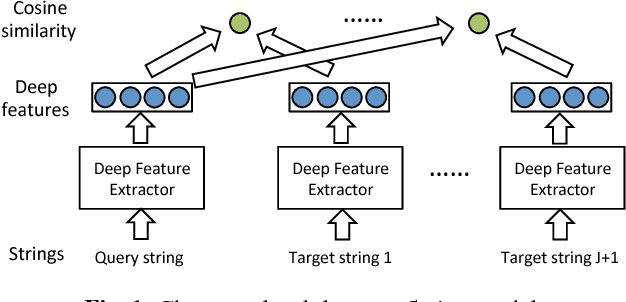
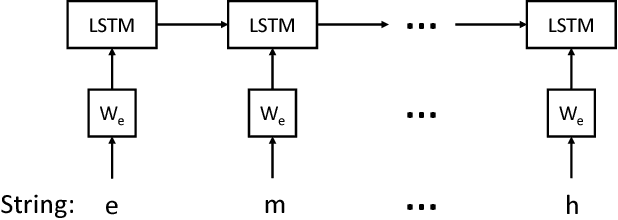
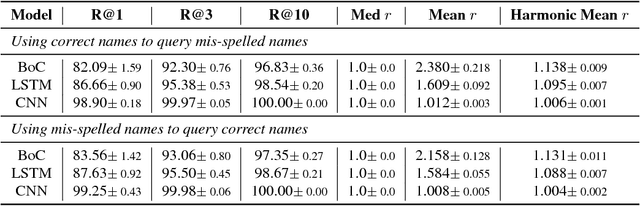
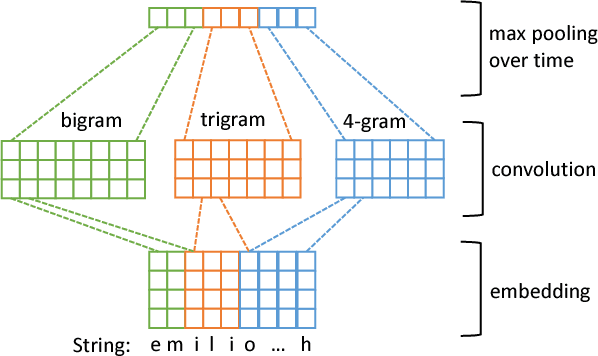
Connecting different text attributes associated with the same entity (conflation) is important in business data analytics since it could help merge two different tables in a database to provide a more comprehensive profile of an entity. However, the conflation task is challenging because two text strings that describe the same entity could be quite different from each other for reasons such as misspelling. It is therefore critical to develop a conflation model that is able to truly understand the semantic meaning of the strings and match them at the semantic level. To this end, we develop a character-level deep conflation model that encodes the input text strings from character level into finite dimension feature vectors, which are then used to compute the cosine similarity between the text strings. The model is trained in an end-to-end manner using back propagation and stochastic gradient descent to maximize the likelihood of the correct association. Specifically, we propose two variants of the deep conflation model, based on long-short-term memory (LSTM) recurrent neural network (RNN) and convolutional neural network (CNN), respectively. Both models perform well on a real-world business analytics dataset and significantly outperform the baseline bag-of-character (BoC) model.
Deep Reinforcement Learning with a Combinatorial Action Space for Predicting Popular Reddit Threads
Sep 17, 2016
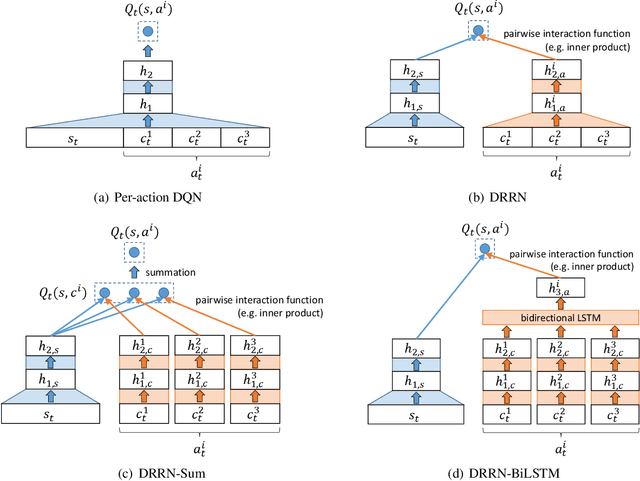
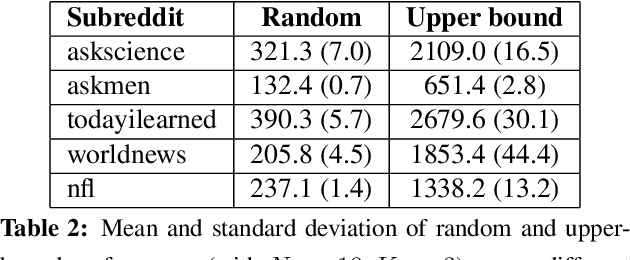
We introduce an online popularity prediction and tracking task as a benchmark task for reinforcement learning with a combinatorial, natural language action space. A specified number of discussion threads predicted to be popular are recommended, chosen from a fixed window of recent comments to track. Novel deep reinforcement learning architectures are studied for effective modeling of the value function associated with actions comprised of interdependent sub-actions. The proposed model, which represents dependence between sub-actions through a bi-directional LSTM, gives the best performance across different experimental configurations and domains, and it also generalizes well with varying numbers of recommendation requests.
Unsupervised Learning of Predictors from Unpaired Input-Output Samples
Jun 15, 2016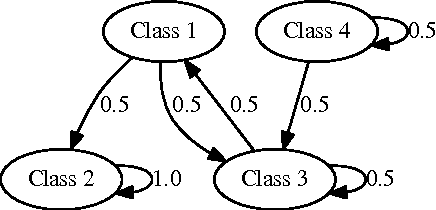
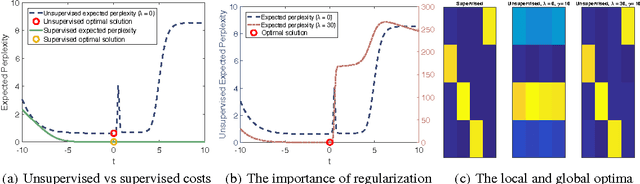
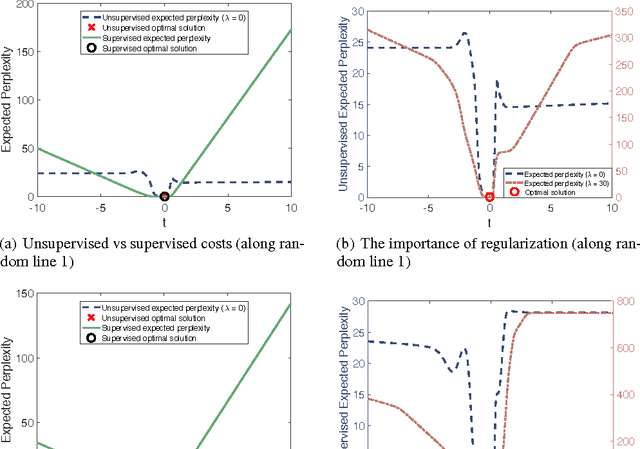
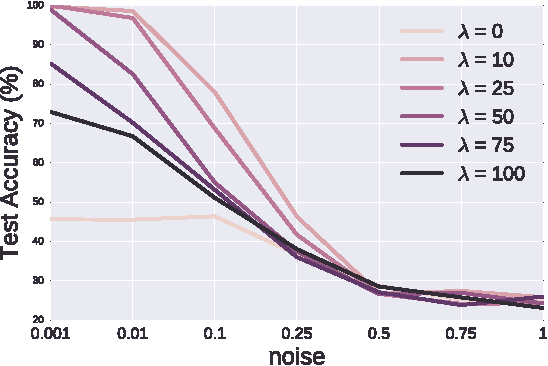
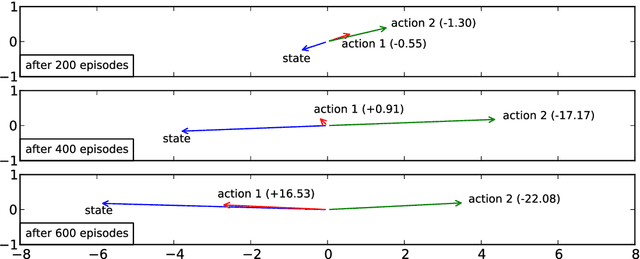
Unsupervised learning is the most challenging problem in machine learning and especially in deep learning. Among many scenarios, we study an unsupervised learning problem of high economic value --- learning to predict without costly pairing of input data and corresponding labels. Part of the difficulty in this problem is a lack of solid evaluation measures. In this paper, we take a practical approach to grounding unsupervised learning by using the same success criterion as for supervised learning in prediction tasks but we do not require the presence of paired input-output training data. In particular, we propose an objective function that aims to make the predicted outputs fit well the structure of the output while preserving the correlation between the input and the predicted output. We experiment with a synthetic structural prediction problem and show that even with simple linear classifiers, the objective function is already highly non-convex. We further demonstrate the nature of this non-convex optimization problem as well as potential solutions. In particular, we show that with regularization via a generative model, learning with the proposed unsupervised objective function converges to an optimal solution.
Deep Reinforcement Learning with a Natural Language Action Space
Jun 08, 2016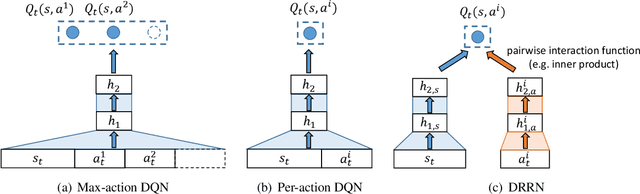
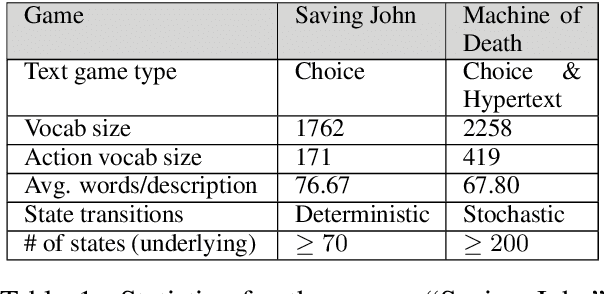
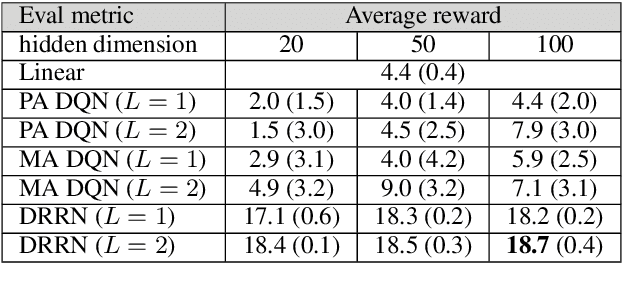
This paper introduces a novel architecture for reinforcement learning with deep neural networks designed to handle state and action spaces characterized by natural language, as found in text-based games. Termed a deep reinforcement relevance network (DRRN), the architecture represents action and state spaces with separate embedding vectors, which are combined with an interaction function to approximate the Q-function in reinforcement learning. We evaluate the DRRN on two popular text games, showing superior performance over other deep Q-learning architectures. Experiments with paraphrased action descriptions show that the model is extracting meaning rather than simply memorizing strings of text.
Deep Sentence Embedding Using Long Short-Term Memory Networks: Analysis and Application to Information Retrieval
Jan 16, 2016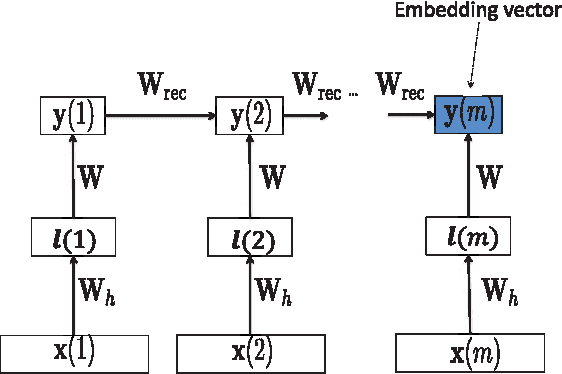
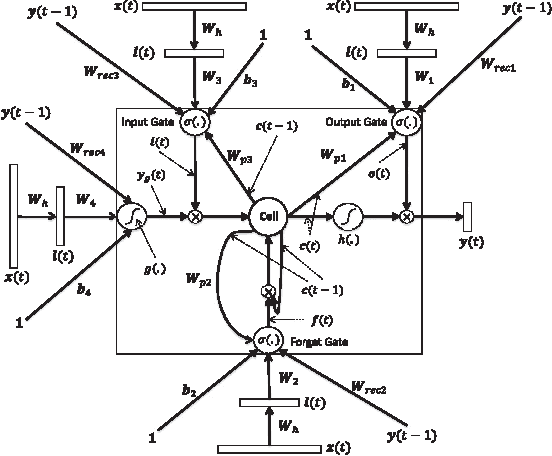
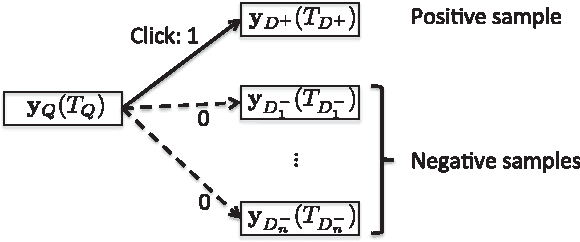
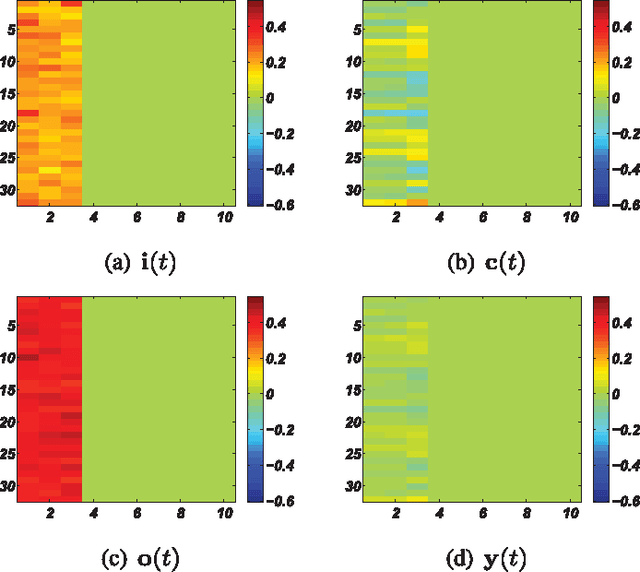
This paper develops a model that addresses sentence embedding, a hot topic in current natural language processing research, using recurrent neural networks with Long Short-Term Memory (LSTM) cells. Due to its ability to capture long term memory, the LSTM-RNN accumulates increasingly richer information as it goes through the sentence, and when it reaches the last word, the hidden layer of the network provides a semantic representation of the whole sentence. In this paper, the LSTM-RNN is trained in a weakly supervised manner on user click-through data logged by a commercial web search engine. Visualization and analysis are performed to understand how the embedding process works. The model is found to automatically attenuate the unimportant words and detects the salient keywords in the sentence. Furthermore, these detected keywords are found to automatically activate different cells of the LSTM-RNN, where words belonging to a similar topic activate the same cell. As a semantic representation of the sentence, the embedding vector can be used in many different applications. These automatic keyword detection and topic allocation abilities enabled by the LSTM-RNN allow the network to perform document retrieval, a difficult language processing task, where the similarity between the query and documents can be measured by the distance between their corresponding sentence embedding vectors computed by the LSTM-RNN. On a web search task, the LSTM-RNN embedding is shown to significantly outperform several existing state of the art methods. We emphasize that the proposed model generates sentence embedding vectors that are specially useful for web document retrieval tasks. A comparison with a well known general sentence embedding method, the Paragraph Vector, is performed. The results show that the proposed method in this paper significantly outperforms it for web document retrieval task.
Recurrent Reinforcement Learning: A Hybrid Approach
Nov 19, 2015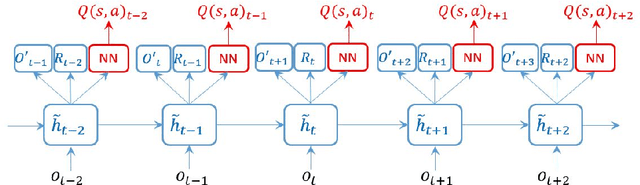
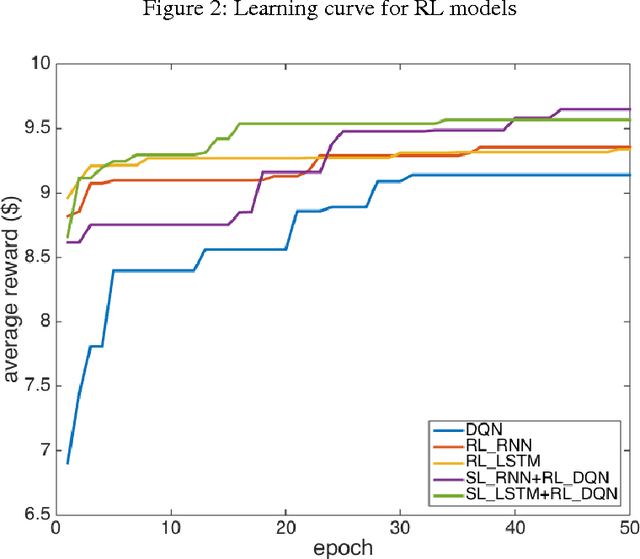
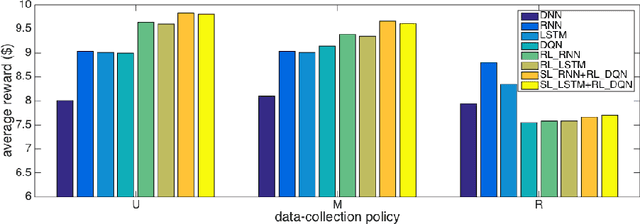
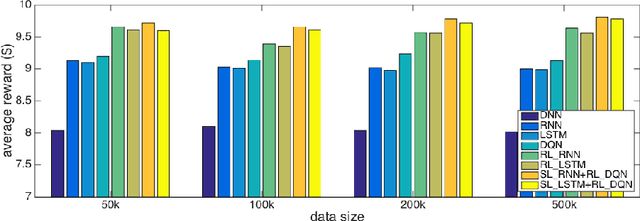
Successful applications of reinforcement learning in real-world problems often require dealing with partially observable states. It is in general very challenging to construct and infer hidden states as they often depend on the agent's entire interaction history and may require substantial domain knowledge. In this work, we investigate a deep-learning approach to learning the representation of states in partially observable tasks, with minimal prior knowledge of the domain. In particular, we propose a new family of hybrid models that combines the strength of both supervised learning (SL) and reinforcement learning (RL), trained in a joint fashion: The SL component can be a recurrent neural networks (RNN) or its long short-term memory (LSTM) version, which is equipped with the desired property of being able to capture long-term dependency on history, thus providing an effective way of learning the representation of hidden states. The RL component is a deep Q-network (DQN) that learns to optimize the control for maximizing long-term rewards. Extensive experiments in a direct mailing campaign problem demonstrate the effectiveness and advantages of the proposed approach, which performs the best among a set of previous state-of-the-art methods.