 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Contrastive Training for Visual Representation Learning
Apr 26, 2021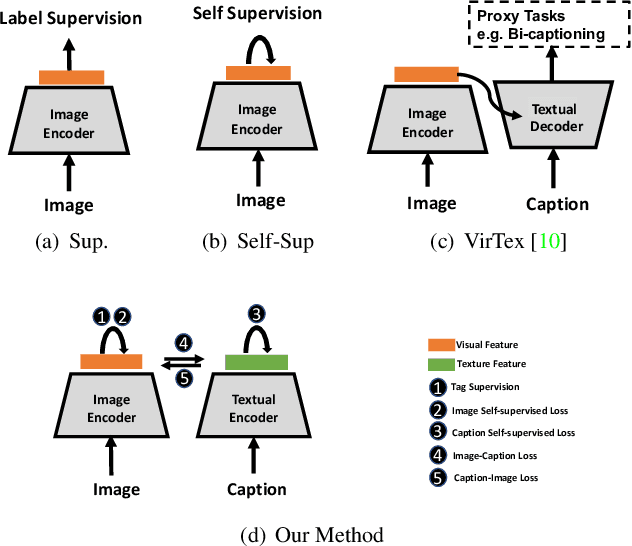
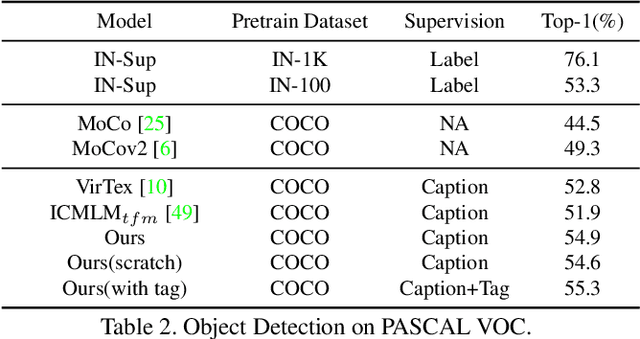
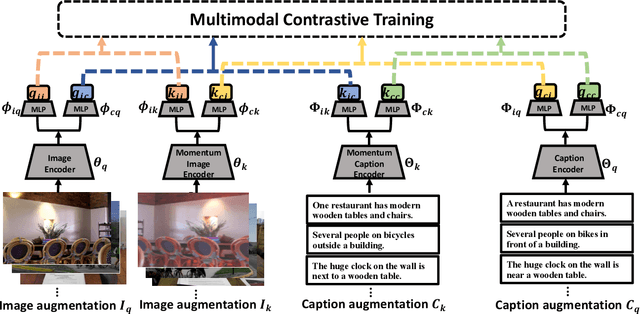
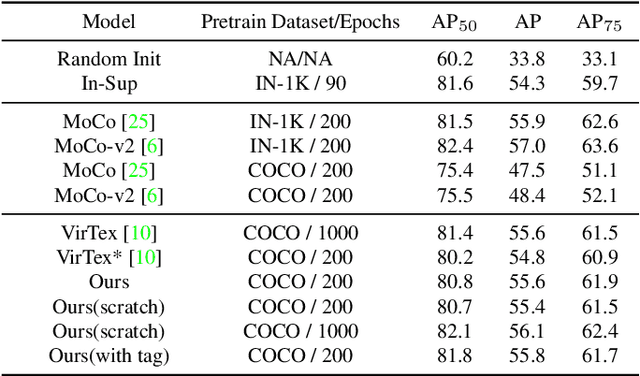
We develop an approach to learning visual representations that embraces multimodal data, driven by a combination of intra- and inter-modal similarity preservation objectives. Unlike existing visual pre-training methods, which solve a proxy prediction task in a single domain, our method exploits intrinsic data properties within each modality and semantic information from cross-modal correlation simultaneously, hence improving the quality of learned visual representations. By including multimodal training in a unified framework with different types of contrastive losses, our method can learn more powerful and generic visual features. We first train our model on COCO and evaluate the learned visual representations on various downstream tasks including image classification, object detection, and instance segmentation. For example, the visual representations pre-trained on COCO by our method achieve state-of-the-art top-1 validation accuracy of $55.3\%$ on ImageNet classification, under the common transfer protocol. We also evaluate our method on the large-scale Stock images dataset and show its effectiveness on multi-label image tagging, and cross-modal retrieval tasks.
Learning to Recover 3D Scene Shape from a Single Image
Dec 17, 2020
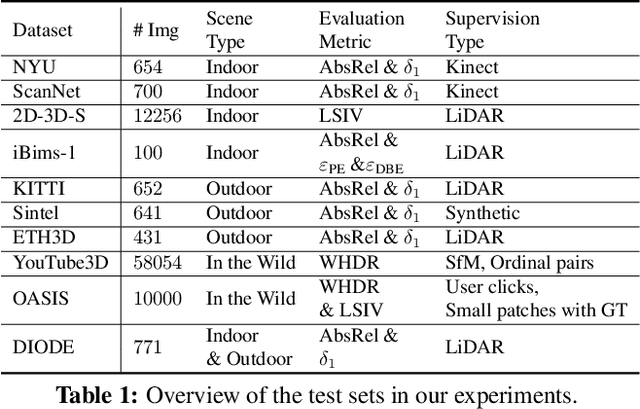
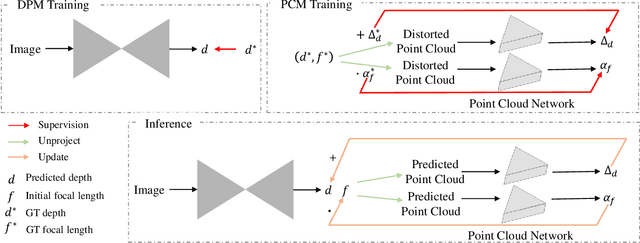
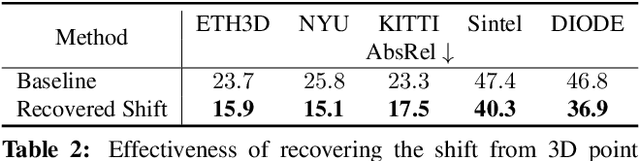
Despite significant progress in monocular depth estimation in the wild, recent state-of-the-art methods cannot be used to recover accurate 3D scene shape due to an unknown depth shift induced by shift-invariant reconstruction losses used in mixed-data depth prediction training, and possible unknown camera focal length. We investigate this problem in detail, and propose a two-stage framework that first predicts depth up to an unknown scale and shift from a single monocular image, and then use 3D point cloud encoders to predict the missing depth shift and focal length that allow us to recover a realistic 3D scene shape. In addition, we propose an image-level normalized regression loss and a normal-based geometry loss to enhance depth prediction models trained on mixed datasets. We test our depth model on nine unseen datasets and achieve state-of-the-art performance on zero-shot dataset generalization. Code is available at: https://git.io/Depth
Semantic Layout Manipulation with High-Resolution Sparse Attention
Dec 14, 2020
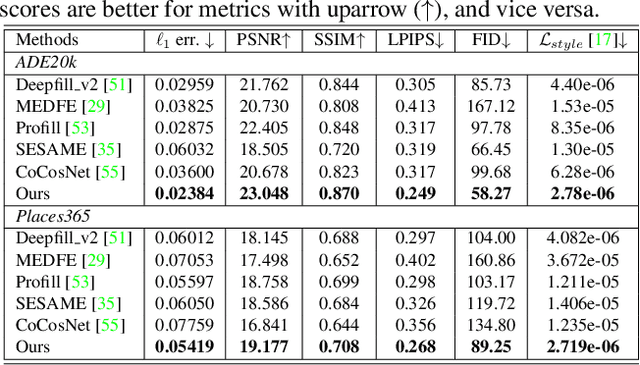
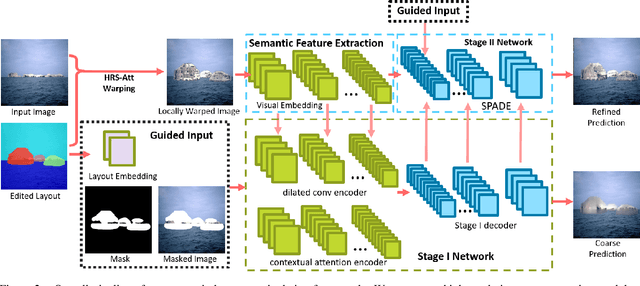
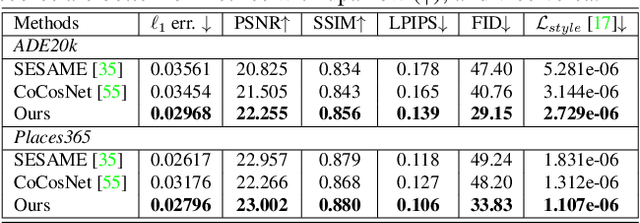
We tackle the problem of semantic image layout manipulation, which aims to manipulate an input image by editing its semantic label map. A core problem of this task is how to transfer visual details from the input images to the new semantic layout while making the resulting image visually realistic. Recent work on learning cross-domain correspondence has shown promising results for global layout transfer with dense attention-based warping. However, this method tends to lose texture details due to the lack of smoothness and resolution in the correspondence and warped images. To adapt this paradigm for the layout manipulation task, we propose a high-resolution sparse attention module that effectively transfers visual details to new layouts at a resolution up to 512x512. To further improve visual quality, we introduce a novel generator architecture consisting of a semantic encoder and a two-stage decoder for coarse-to-fine synthesis. Experiments on the ADE20k and Places365 datasets demonstrate that our proposed approach achieves substantial improvements over the existing inpainting and layout manipulation methods.
Meticulous Object Segmentation
Dec 13, 2020Compared with common image segmentation tasks targeted at low-resolution images, higher resolution detailed image segmentation receives much less attention. In this paper, we propose and study a task named Meticulous Object Segmentation (MOS), which is focused on segmenting well-defined foreground objects with elaborate shapes in high resolution images (e.g. 2k - 4k). To this end, we propose the MeticulousNet which leverages a dedicated decoder to capture the object boundary details. Specifically, we design a Hierarchical Point-wise Refining (HierPR) block to better delineate object boundaries, and reformulate the decoding process as a recursive coarse to fine refinement of the object mask. To evaluate segmentation quality near object boundaries, we propose the Meticulosity Quality (MQ) score considering both the mask coverage and boundary precision. In addition, we collect a MOS benchmark dataset including 600 high quality images with complex objects. We provide comprehensive empirical evidence showing that MeticulousNet can reveal pixel-accurate segmentation boundaries and is superior to state-of-the-art methods for high resolution object segmentation tasks.
Mask Guided Matting via Progressive Refinement Network
Dec 12, 2020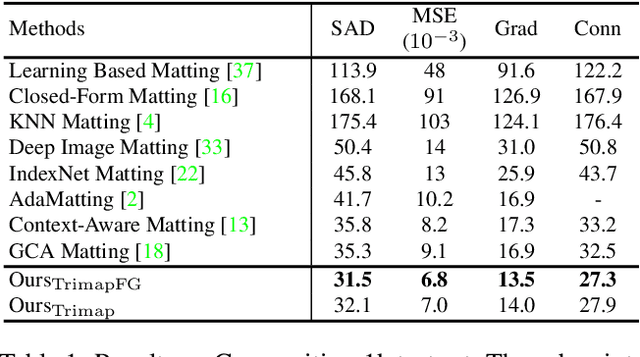
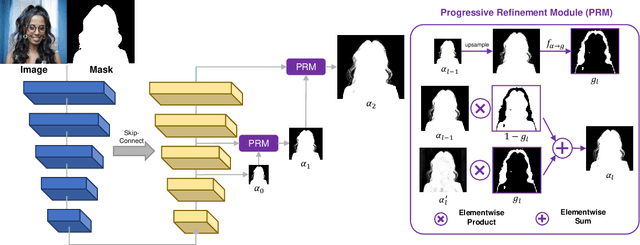
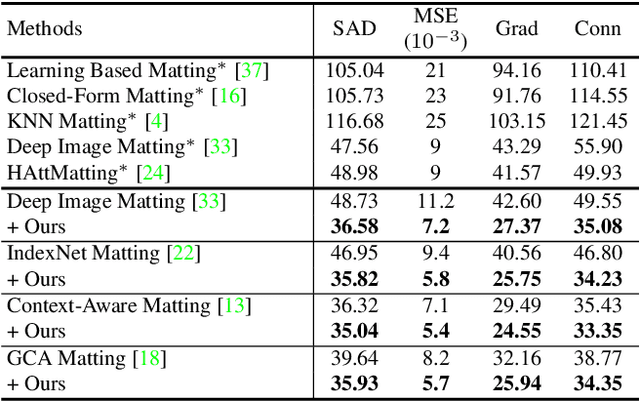

We propose Mask Guided (MG) Matting, a robust matting framework that takes a general coarse mask as guidance. MG Matting leverages a network (PRN) design which encourages the matting model to provide self-guidance to progressively refine the uncertain regions through the decoding process. A series of guidance mask perturbation operations are also introduced in the training to further enhance its robustness to external guidance. We show that PRN can generalize to unseen types of guidance masks such as trimap and low-quality alpha matte, making it suitable for various application pipelines. In addition, we revisit the foreground color prediction problem for matting and propose a surprisingly simple improvement to address the dataset issue. Evaluation on real and synthetic benchmarks shows that MG Matting achieves state-of-the-art performance using various types of guidance inputs. Code and models will be available at https://github.com/yucornetto/MGMatting
Deep Image Compositing
Nov 04, 2020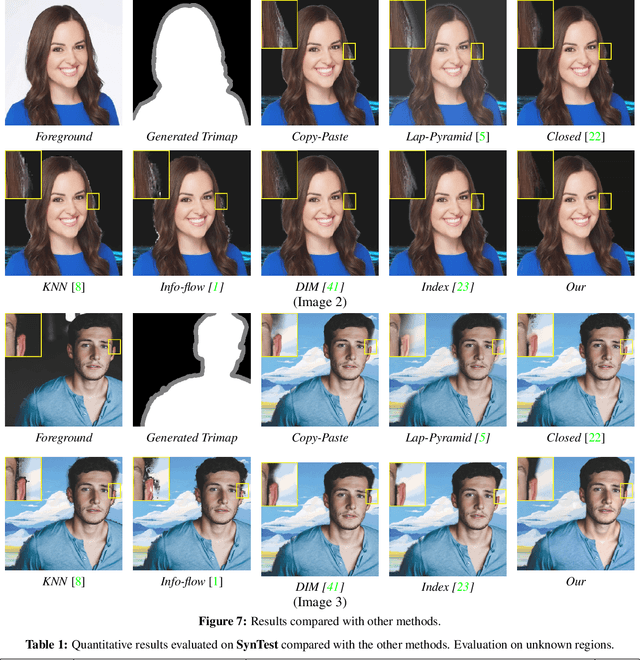

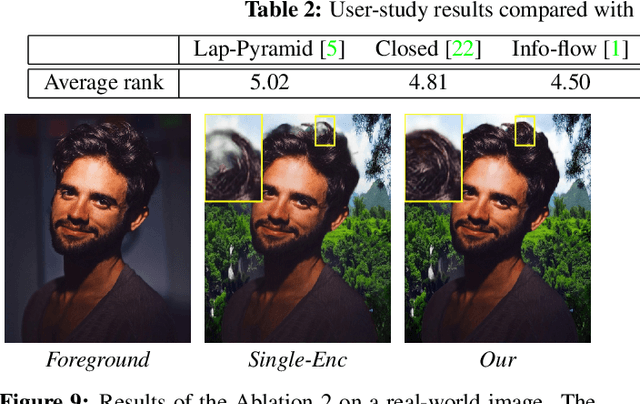
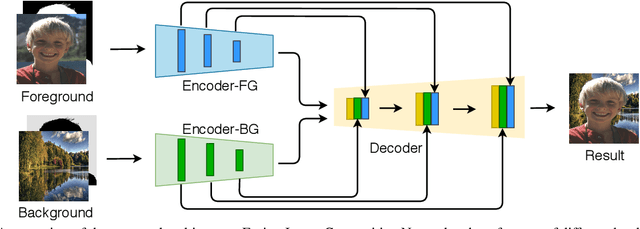
Image compositing is a task of combining regions from different images to compose a new image. A common use case is background replacement of portrait images. To obtain high quality composites, professionals typically manually perform multiple editing steps such as segmentation, matting and foreground color decontamination, which is very time consuming even with sophisticated photo editing tools. In this paper, we propose a new method which can automatically generate high-quality image compositing without any user input. Our method can be trained end-to-end to optimize exploitation of contextual and color information of both foreground and background images, where the compositing quality is considered in the optimization. Specifically, inspired by Laplacian pyramid blending, a dense-connected multi-stream fusion network is proposed to effectively fuse the information from the foreground and background images at different scales. In addition, we introduce a self-taught strategy to progressively train from easy to complex cases to mitigate the lack of training data. Experiments show that the proposed method can automatically generate high-quality composites and outperforms existing methods both qualitatively and quantitatively.
Attribute-conditioned Layout GAN for Automatic Graphic Design
Sep 11, 2020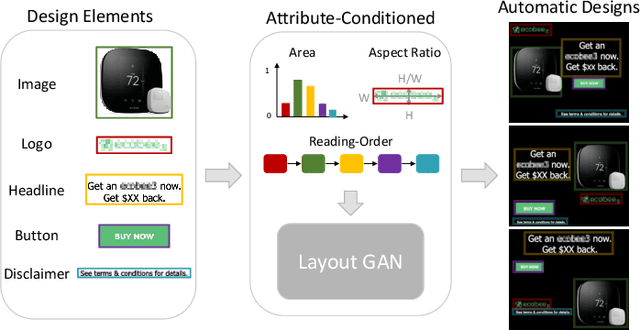
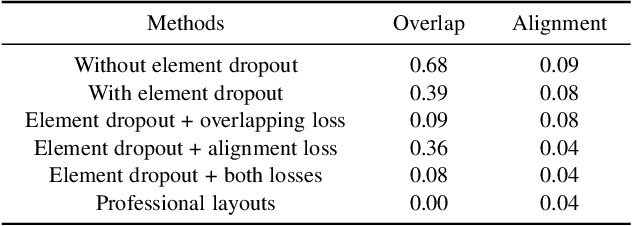
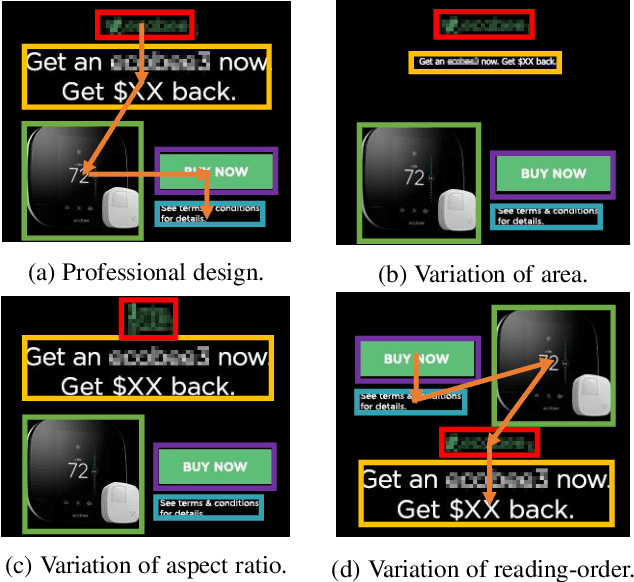
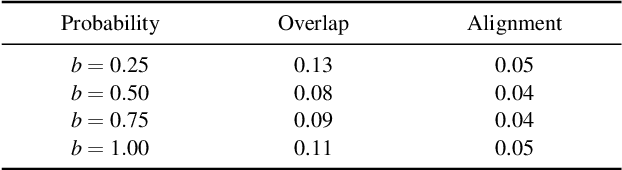
Modeling layout is an important first step for graphic design. Recently, methods for generating graphic layouts have progressed, particularly with Generative Adversarial Networks (GANs). However, the problem of specifying the locations and sizes of design elements usually involves constraints with respect to element attributes, such as area, aspect ratio and reading-order. Automating attribute conditional graphic layouts remains a complex and unsolved problem. In this paper, we introduce Attribute-conditioned Layout GAN to incorporate the attributes of design elements for graphic layout generation by forcing both the generator and the discriminator to meet attribute conditions. Due to the complexity of graphic designs, we further propose an element dropout method to make the discriminator look at partial lists of elements and learn their local patterns. In addition, we introduce various loss designs following different design principles for layout optimization. We demonstrate that the proposed method can synthesize graphic layouts conditioned on different element attributes. It can also adjust well-designed layouts to new sizes while retaining elements' original reading-orders. The effectiveness of our method is validated through a user study.
Adversarial Knowledge Transfer from Unlabeled Data
Aug 13, 2020
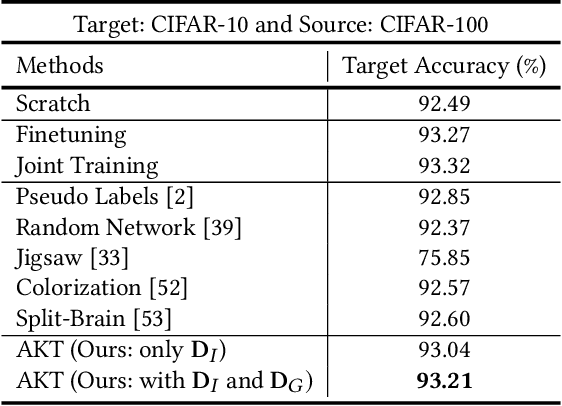
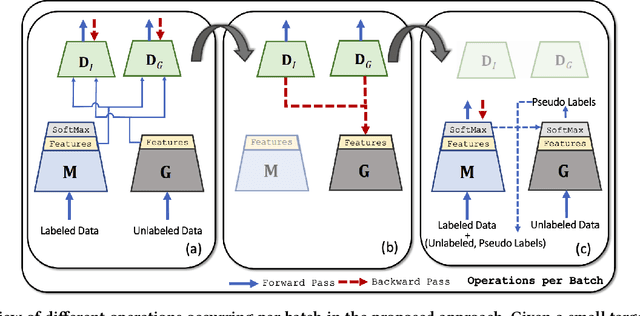
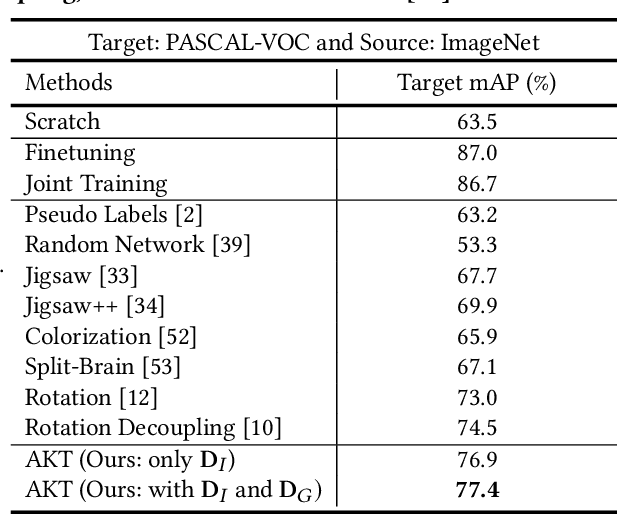
While machine learning approaches to visual recognition offer great promise, most of the existing methods rely heavily on the availability of large quantities of labeled training data. However, in the vast majority of real-world settings, manually collecting such large labeled datasets is infeasible due to the cost of labeling data or the paucity of data in a given domain. In this paper, we present a novel Adversarial Knowledge Transfer (AKT) framework for transferring knowledge from internet-scale unlabeled data to improve the performance of a classifier on a given visual recognition task. The proposed adversarial learning framework aligns the feature space of the unlabeled source data with the labeled target data such that the target classifier can be used to predict pseudo labels on the source data. An important novel aspect of our method is that the unlabeled source data can be of different classes from those of the labeled target data, and there is no need to define a separate pretext task, unlike some existing approaches. Extensive experiments well demonstrate that models learned using our approach hold a lot of promise across a variety of visual recognition tasks on multiple standard datasets.
Shape Adaptor: A Learnable Resizing Module
Aug 10, 2020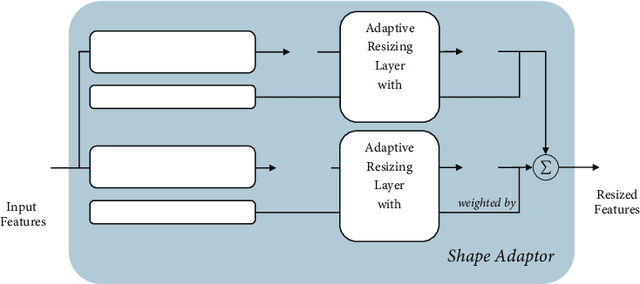
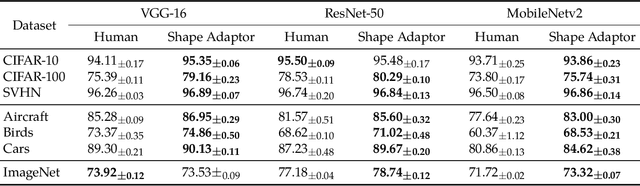
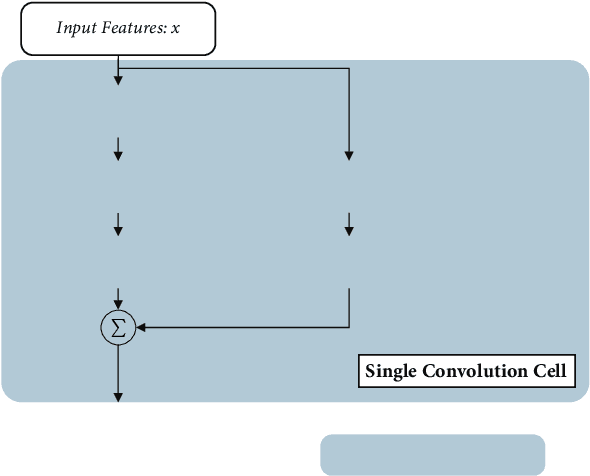

We present a novel resizing module for neural networks: shape adaptor, a drop-in enhancement built on top of traditional resizing layers, such as pooling, bilinear sampling, and strided convolution. Whilst traditional resizing layers have fixed and deterministic reshaping factors, our module allows for a learnable reshaping factor. Our implementation enables shape adaptors to be trained end-to-end without any additional supervision, through which network architectures can be optimised for each individual task, in a fully automated way. We performed experiments across seven image classification datasets, and results show that by simply using a set of our shape adaptors instead of the original resizing layers, performance increases consistently over human-designed networks, across all datasets. Additionally, we show the effectiveness of shape adaptors on two other applications: network compression and transfer learning. The source code is available at: https://github.com/lorenmt/shape-adaptor.
Open-Edit: Open-Domain Image Manipulation with Open-Vocabulary Instructions
Aug 04, 2020
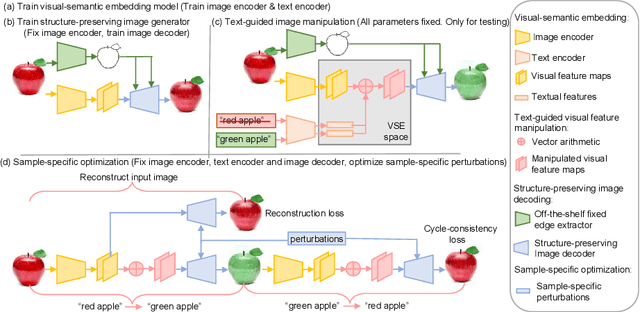


We propose a novel algorithm, named Open-Edit, which is the first attempt on open-domain image manipulation with open-vocabulary instructions. It is a challenging task considering the large variation of image domains and the lack of training supervision. Our approach takes advantage of the unified visual-semantic embedding space pretrained on a general image-caption dataset, and manipulates the embedded visual features by applying text-guided vector arithmetic on the image feature maps. A structure-preserving image decoder then generates the manipulated images from the manipulated feature maps. We further propose an on-the-fly sample-specific optimization approach with cycle-consistency constraints to regularize the manipulated images and force them to preserve details of the source images. Our approach shows promising results in manipulating open-vocabulary color, texture, and high-level attributes for various scenarios of open-domain images.