 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Adaptive Prompt Distillation for Few-Shot Visual Question Answering
Jun 07, 2025Large Multimodal Models (LMMs) often rely on in-context learning (ICL) to perform new tasks with minimal supervision. However, ICL performance, especially in smaller LMMs, is inconsistent and does not always improve monotonically with increasing examples. We hypothesize that this occurs due to the LMM being overwhelmed by additional information present in the image embeddings, which is not required for the downstream task. To address this, we propose a meta-learning approach that provides an alternative for inducing few-shot capabilities in LMMs, using a fixed set of soft prompts that are distilled from task-relevant image features and can be adapted at test time using a few examples. To facilitate this distillation, we introduce an attention-mapper module that can be easily integrated with the popular LLaVA v1.5 architecture and is jointly learned with soft prompts, enabling task adaptation in LMMs under low-data regimes with just a few gradient steps. Evaluation on the VL-ICL Bench shows that our method consistently outperforms ICL and related prompt-tuning approaches, even under image perturbations, improving task induction and reasoning across visual question answering tasks.
LLM Task Interference: An Initial Study on the Impact of Task-Switch in Conversational History
Feb 28, 2024



With the recent emergence of powerful instruction-tuned large language models (LLMs), various helpful conversational Artificial Intelligence (AI) systems have been deployed across many applications. When prompted by users, these AI systems successfully perform a wide range of tasks as part of a conversation. To provide some sort of memory and context, such approaches typically condition their output on the entire conversational history. Although this sensitivity to the conversational history can often lead to improved performance on subsequent tasks, we find that performance can in fact also be negatively impacted, if there is a task-switch. To the best of our knowledge, our work makes the first attempt to formalize the study of such vulnerabilities and interference of tasks in conversational LLMs caused by task-switches in the conversational history. Our experiments across 5 datasets with 15 task switches using popular LLMs reveal that many of the task-switches can lead to significant performance degradation.
ModEFormer: Modality-Preserving Embedding for Audio-Video Synchronization using Transformers
Mar 21, 2023Lack of audio-video synchronization is a common problem during television broadcasts and video conferencing, leading to an unsatisfactory viewing experience. A widely accepted paradigm is to create an error detection mechanism that identifies the cases when audio is leading or lagging. We propose ModEFormer, which independently extracts audio and video embeddings using modality-specific transformers. Different from the other transformer-based approaches, ModEFormer preserves the modality of the input streams which allows us to use a larger batch size with more negative audio samples for contrastive learning. Further, we propose a trade-off between the number of negative samples and number of unique samples in a batch to significantly exceed the performance of previous methods. Experimental results show that ModEFormer achieves state-of-the-art performance, 94.5% for LRS2 and 90.9% for LRS3. Finally, we demonstrate how ModEFormer can be used for offset detection for test clips.
GAMA: Generative Adversarial Multi-Object Scene Attacks
Sep 20, 2022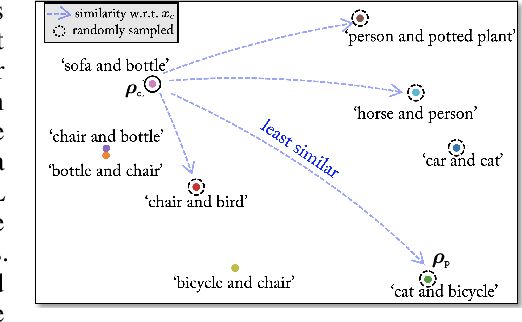

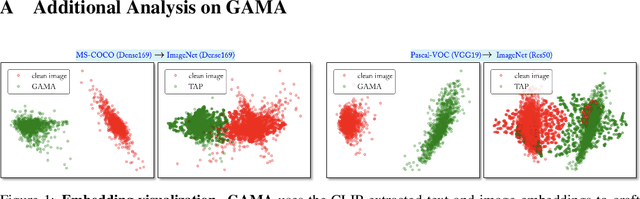
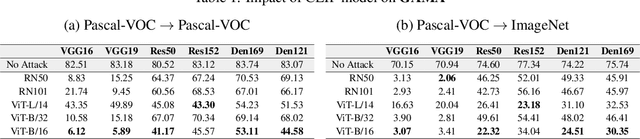
The majority of methods for crafting adversarial attacks have focused on scenes with a single dominant object (e.g., images from ImageNet). On the other hand, natural scenes include multiple dominant objects that are semantically related. Thus, it is crucial to explore designing attack strategies that look beyond learning on single-object scenes or attack single-object victim classifiers. Due to their inherent property of strong transferability of perturbations to unknown models, this paper presents the first approach of using generative models for adversarial attacks on multi-object scenes. In order to represent the relationships between different objects in the input scene, we leverage upon the open-sourced pre-trained vision-language model CLIP (Contrastive Language-Image Pre-training), with the motivation to exploit the encoded semantics in the language space along with the visual space. We call this attack approach Generative Adversarial Multi-object scene Attacks (GAMA). GAMA demonstrates the utility of the CLIP model as an attacker's tool to train formidable perturbation generators for multi-object scenes. Using the joint image-text features to train the generator, we show that GAMA can craft potent transferable perturbations in order to fool victim classifiers in various attack settings. For example, GAMA triggers ~16% more misclassification than state-of-the-art generative approaches in black-box settings where both the classifier architecture and data distribution of the attacker are different from the victim. Our code will be made publicly available soon.
UltraMNIST Classification: A Benchmark to Train CNNs for Very Large Images
Jun 25, 2022
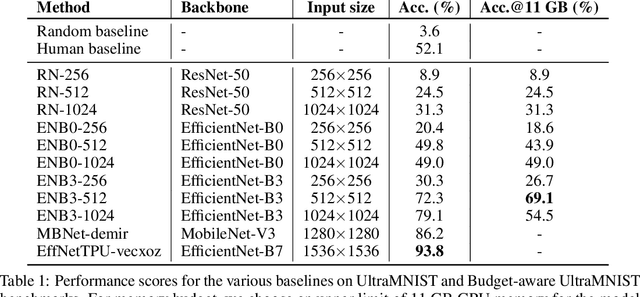

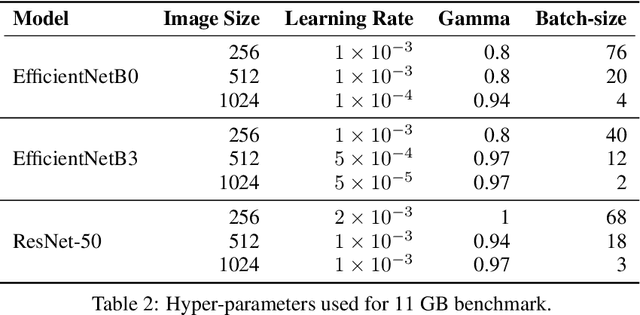
Convolutional neural network (CNN) approaches available in the current literature are designed to work primarily with low-resolution images. When applied on very large images, challenges related to GPU memory, smaller receptive field than needed for semantic correspondence and the need to incorporate multi-scale features arise. The resolution of input images can be reduced, however, with significant loss of critical information. Based on the outlined issues, we introduce a novel research problem of training CNN models for very large images, and present 'UltraMNIST dataset', a simple yet representative benchmark dataset for this task. UltraMNIST has been designed using the popular MNIST digits with additional levels of complexity added to replicate well the challenges of real-world problems. We present two variants of the problem: 'UltraMNIST classification' and 'Budget-aware UltraMNIST classification'. The standard UltraMNIST classification benchmark is intended to facilitate the development of novel CNN training methods that make the effective use of the best available GPU resources. The budget-aware variant is intended to promote development of methods that work under constrained GPU memory. For the development of competitive solutions, we present several baseline models for the standard benchmark and its budget-aware variant. We study the effect of reducing resolution on the performance and present results for baseline models involving pretrained backbones from among the popular state-of-the-art models. Finally, with the presented benchmark dataset and the baselines, we hope to pave the ground for a new generation of CNN methods suitable for handling large images in an efficient and resource-light manner.
Poisson2Sparse: Self-Supervised Poisson Denoising From a Single Image
Jun 04, 2022

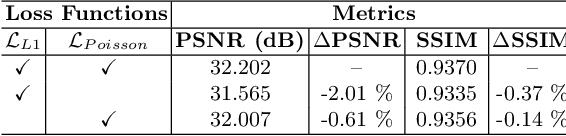
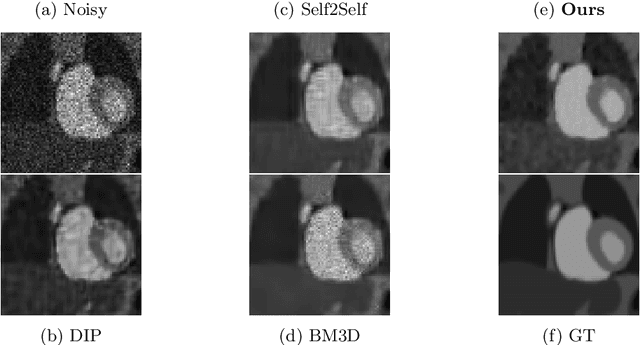
Image enhancement approaches often assume that the noise is signal independent, and approximate the degradation model as zero-mean additive Gaussian noise. However, this assumption does not hold for biomedical imaging systems where sensor-based sources of noise are proportional to signal strengths, and the noise is better represented as a Poisson process. In this work, we explore a sparsity and dictionary learning-based approach and present a novel self-supervised learning method for single-image denoising where the noise is approximated as a Poisson process, requiring no clean ground-truth data. Specifically, we approximate traditional iterative optimization algorithms for image denoising with a recurrent neural network which enforces sparsity with respect to the weights of the network. Since the sparse representations are based on the underlying image, it is able to suppress the spurious components (noise) in the image patches, thereby introducing implicit regularization for denoising task through the network structure. Experiments on two bio-imaging datasets demonstrate that our method outperforms the state-of-the-art approaches in terms of PSNR and SSIM. Our qualitative results demonstrate that, in addition to higher performance on standard quantitative metrics, we are able to recover much more subtle details than other compared approaches.
A-ACT: Action Anticipation through Cycle Transformations
Apr 02, 2022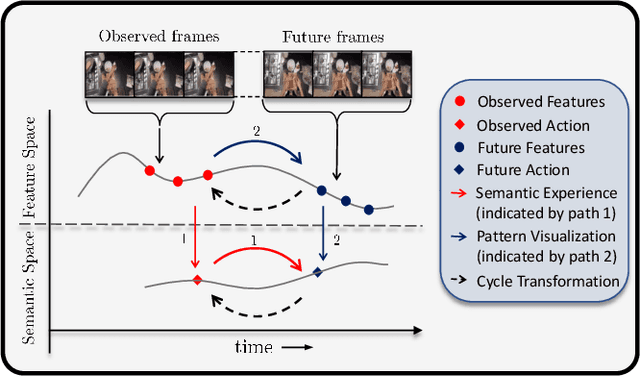
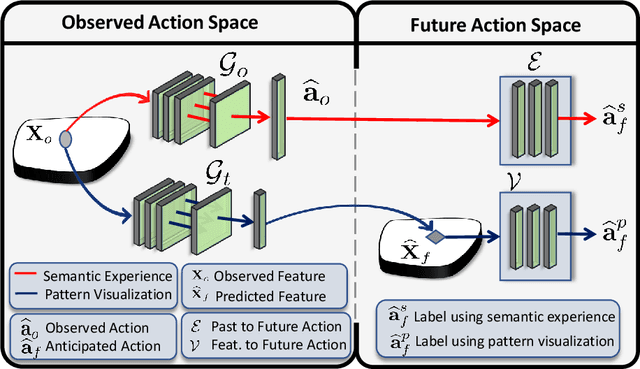
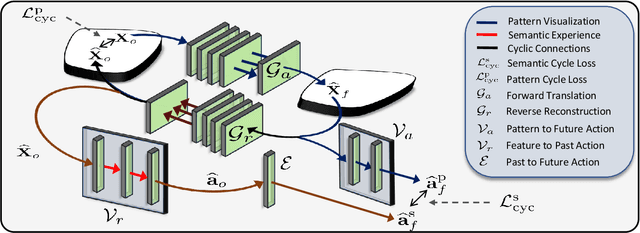
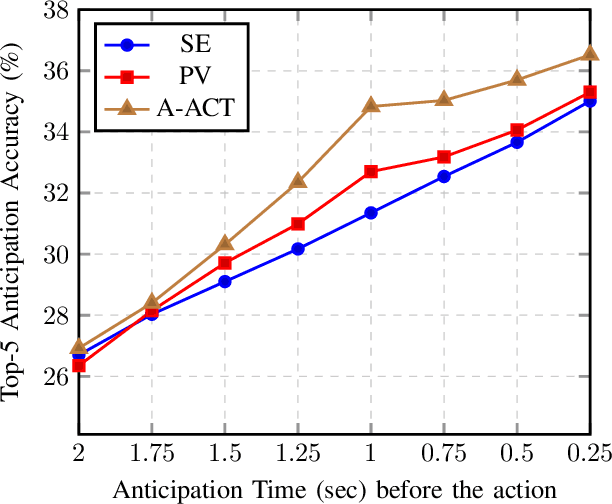
While action anticipation has garnered a lot of research interest recently, most of the works focus on anticipating future action directly through observed visual cues only. In this work, we take a step back to analyze how the human capability to anticipate the future can be transferred to machine learning algorithms. To incorporate this ability in intelligent systems a question worth pondering upon is how exactly do we anticipate? Is it by anticipating future actions from past experiences? Or is it by simulating possible scenarios based on cues from the present? A recent study on human psychology explains that, in anticipating an occurrence, the human brain counts on both systems. In this work, we study the impact of each system for the task of action anticipation and introduce a paradigm to integrate them in a learning framework. We believe that intelligent systems designed by leveraging the psychological anticipation models will do a more nuanced job at the task of human action prediction. Furthermore, we introduce cyclic transformation in the temporal dimension in feature and semantic label space to instill the human ability of reasoning of past actions based on the predicted future. Experiments on Epic-Kitchen, Breakfast, and 50Salads dataset demonstrate that the action anticipation model learned using a combination of the two systems along with the cycle transformation performs favorably against various state-of-the-art approaches.
Classification of histopathology images using ConvNets to detect Lupus Nephritis
Dec 14, 2021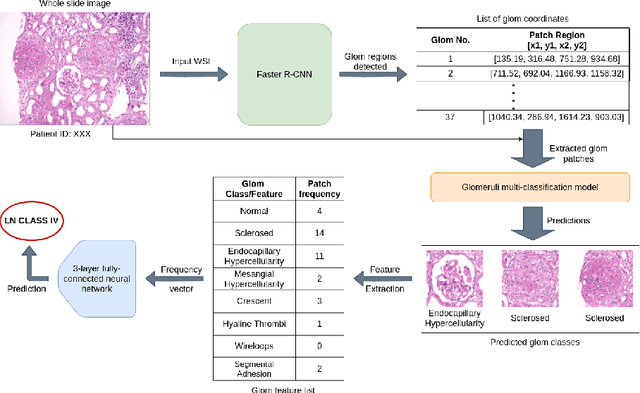
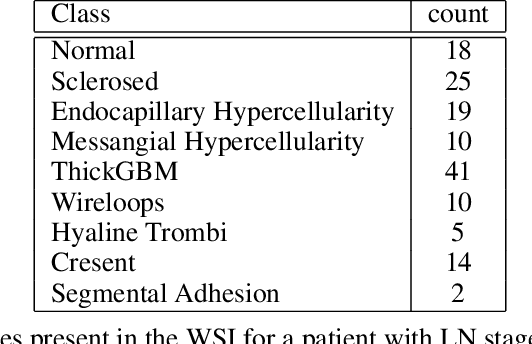
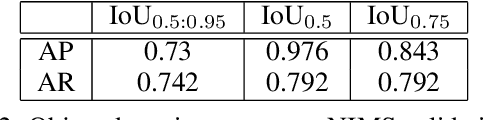
Systemic lupus erythematosus (SLE) is an autoimmune disease in which the immune system of the patient starts attacking healthy tissues of the body. Lupus Nephritis (LN) refers to the inflammation of kidney tissues resulting in renal failure due to these attacks. The International Society of Nephrology/Renal Pathology Society (ISN/RPS) has released a classification system based on various patterns observed during renal injury in SLE. Traditional methods require meticulous pathological assessment of the renal biopsy and are time-consuming. Recently, computational techniques have helped to alleviate this issue by using virtual microscopy or Whole Slide Imaging (WSI). With the use of deep learning and modern computer vision techniques, we propose a pipeline that is able to automate the process of 1) detection of various glomeruli patterns present in these whole slide images and 2) classification of each image using the extracted glomeruli features.
APObind: A Dataset of Ligand Unbound Protein Conformations for Machine Learning Applications in De Novo Drug Design
Aug 25, 2021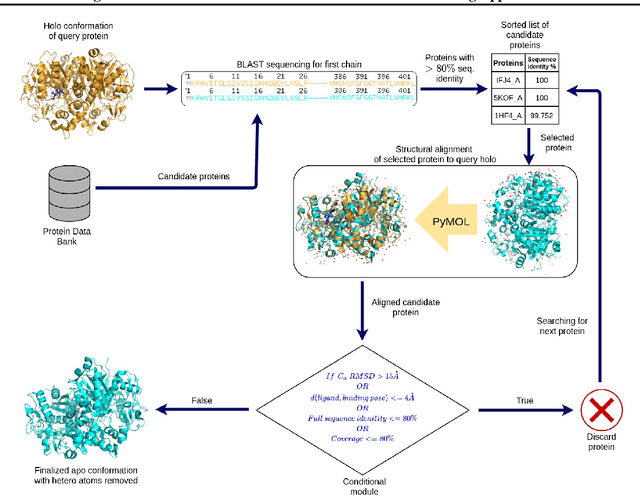

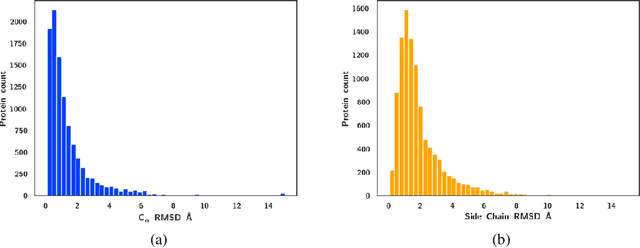
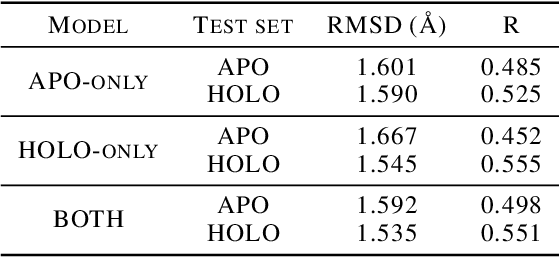
Protein-ligand complex structures have been utilised to design benchmark machine learning methods that perform important tasks related to drug design such as receptor binding site detection, small molecule docking and binding affinity prediction. However, these methods are usually trained on only ligand bound (or holo) conformations of the protein and therefore are not guaranteed to perform well when the protein structure is in its native unbound conformation (or apo), which is usually the conformation available for a newly identified receptor. A primary reason for this is that the local structure of the binding site usually changes upon ligand binding. To facilitate solutions for this problem, we propose a dataset called APObind that aims to provide apo conformations of proteins present in the PDBbind dataset, a popular dataset used in drug design. Furthermore, we explore the performance of methods specific to three use cases on this dataset, through which, the importance of validating them on the APObind dataset is demonstrated.
Ada-VSR: Adaptive Video Super-Resolution with Meta-Learning
Aug 05, 2021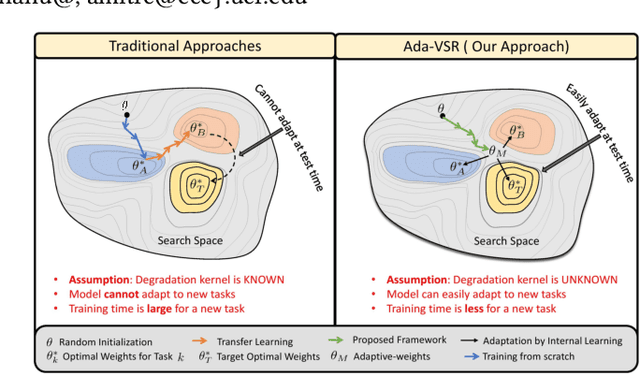
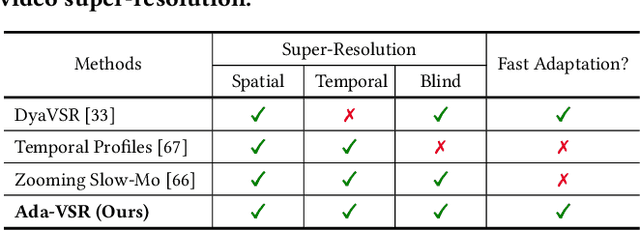
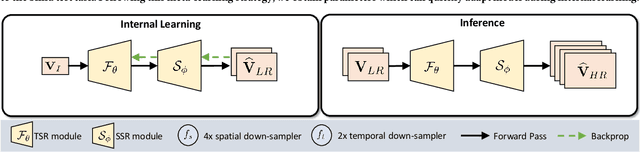
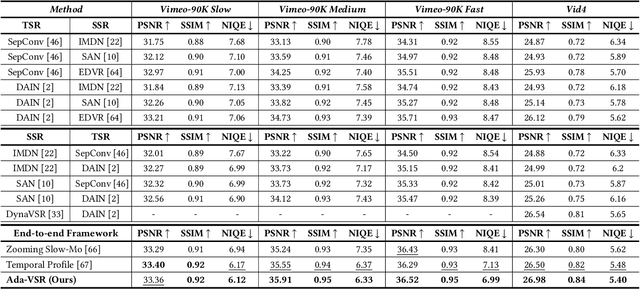
Most of the existing works in supervised spatio-temporal video super-resolution (STVSR) heavily rely on a large-scale external dataset consisting of paired low-resolution low-frame rate (LR-LFR)and high-resolution high-frame-rate (HR-HFR) videos. Despite their remarkable performance, these methods make a prior assumption that the low-resolution video is obtained by down-scaling the high-resolution video using a known degradation kernel, which does not hold in practical settings. Another problem with these methods is that they cannot exploit instance-specific internal information of video at testing time. Recently, deep internal learning approaches have gained attention due to their ability to utilize the instance-specific statistics of a video. However, these methods have a large inference time as they require thousands of gradient updates to learn the intrinsic structure of the data. In this work, we presentAdaptiveVideoSuper-Resolution (Ada-VSR) which leverages external, as well as internal, information through meta-transfer learning and internal learning, respectively. Specifically, meta-learning is employed to obtain adaptive parameters, using a large-scale external dataset, that can adapt quickly to the novel condition (degradation model) of the given test video during the internal learning task, thereby exploiting external and internal information of a video for super-resolution. The model trained using our approach can quickly adapt to a specific video condition with only a few gradient updates, which reduces the inference time significantly. Extensive experiments on standard datasets demonstrate that our method performs favorably against various state-of-the-art approaches.