 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreePO: Bridging the Gap of Policy Optimization and Efficacy and Inference Efficiency with Heuristic Tree-based Modeling
Aug 24, 2025



Recent advancements in aligning large language models via reinforcement learning have achieved remarkable gains in solving complex reasoning problems, but at the cost of expensive on-policy rollouts and limited exploration of diverse reasoning paths. In this work, we introduce TreePO, involving a self-guided rollout algorithm that views sequence generation as a tree-structured searching process. Composed of dynamic tree sampling policy and fixed-length segment decoding, TreePO leverages local uncertainty to warrant additional branches. By amortizing computation across common prefixes and pruning low-value paths early, TreePO essentially reduces the per-update compute burden while preserving or enhancing exploration diversity. Key contributions include: (1) a segment-wise sampling algorithm that alleviates the KV cache burden through contiguous segments and spawns new branches along with an early-stop mechanism; (2) a tree-based segment-level advantage estimation that considers both global and local proximal policy optimization. and (3) analysis on the effectiveness of probability and quality-driven dynamic divergence and fallback strategy. We empirically validate the performance gain of TreePO on a set reasoning benchmarks and the efficiency saving of GPU hours from 22\% up to 43\% of the sampling design for the trained models, meanwhile showing up to 40\% reduction at trajectory-level and 35\% at token-level sampling compute for the existing models. While offering a free lunch of inference efficiency, TreePO reveals a practical path toward scaling RL-based post-training with fewer samples and less compute. Home page locates at https://m-a-p.ai/TreePO.
HiMat: DiT-based Ultra-High Resolution SVBRDF Generation
Aug 12, 2025



Creating highly detailed SVBRDFs is essential for 3D content creation. The rise of high-resolution text-to-image generative models, based on diffusion transformers (DiT), suggests an opportunity to finetune them for this task. However, retargeting the models to produce multiple aligned SVBRDF maps instead of just RGB images, while achieving high efficiency and ensuring consistency across different maps, remains a challenge. In this paper, we introduce HiMat: a memory- and computation-efficient diffusion-based framework capable of generating native 4K-resolution SVBRDFs. A key challenge we address is maintaining consistency across different maps in a lightweight manner, without relying on training new VAEs or significantly altering the DiT backbone (which would damage its prior capabilities). To tackle this, we introduce the CrossStitch module, a lightweight convolutional module that captures inter-map dependencies through localized operations. Its weights are initialized such that the DiT backbone operation is unchanged before finetuning starts. HiMat enables generation with strong structural coherence and high-frequency details. Results with a large set of text prompts demonstrate the effectiveness of our approach for 4K SVBRDF generation. Further experiments suggest generalization to tasks such as intrinsic decomposition.
WeatherDiffusion: Weather-Guided Diffusion Model for Forward and Inverse Rendering
Aug 09, 2025Forward and inverse rendering have emerged as key techniques for enabling understanding and reconstruction in the context of autonomous driving (AD). However, complex weather and illumination pose great challenges to this task. The emergence of large diffusion models has shown promise in achieving reasonable results through learning from 2D priors, but these models are difficult to control and lack robustness. In this paper, we introduce WeatherDiffusion, a diffusion-based framework for forward and inverse rendering on AD scenes with various weather and lighting conditions. Our method enables authentic estimation of material properties, scene geometry, and lighting, and further supports controllable weather and illumination editing through the use of predicted intrinsic maps guided by text descriptions. We observe that different intrinsic maps should correspond to different regions of the original image. Based on this observation, we propose Intrinsic map-aware attention (MAA) to enable high-quality inverse rendering. Additionally, we introduce a synthetic dataset (\ie WeatherSynthetic) and a real-world dataset (\ie WeatherReal) for forward and inverse rendering on AD scenes with diverse weather and lighting. Extensive experiments show that our WeatherDiffusion outperforms state-of-the-art methods on several benchmarks. Moreover, our method demonstrates significant value in downstream tasks for AD, enhancing the robustness of object detection and image segmentation in challenging weather scenarios.
Sculpting Margin Penalty: Intra-Task Adapter Merging and Classifier Calibration for Few-Shot Class-Incremental Learning
Aug 07, 2025Real-world applications often face data privacy constraints and high acquisition costs, making the assumption of sufficient training data in incremental tasks unrealistic and leading to significant performance degradation in class-incremental learning. Forward-compatible learning, which prospectively prepares for future tasks during base task training, has emerged as a promising solution for Few-Shot Class-Incremental Learning (FSCIL). However, existing methods still struggle to balance base-class discriminability and new-class generalization. Moreover, limited access to original data during incremental tasks often results in ambiguous inter-class decision boundaries. To address these challenges, we propose SMP (Sculpting Margin Penalty), a novel FSCIL method that strategically integrates margin penalties at different stages within the parameter-efficient fine-tuning paradigm. Specifically, we introduce the Margin-aware Intra-task Adapter Merging (MIAM) mechanism for base task learning. MIAM trains two sets of low-rank adapters with distinct classification losses: one with a margin penalty to enhance base-class discriminability, and the other without margin constraints to promote generalization to future new classes. These adapters are then adaptively merged to improve forward compatibility. For incremental tasks, we propose a Margin Penalty-based Classifier Calibration (MPCC) strategy to refine decision boundaries by fine-tuning classifiers on all seen classes' embeddings with a margin penalty. Extensive experiments on CIFAR100, ImageNet-R, and CUB200 demonstrate that SMP achieves state-of-the-art performance in FSCIL while maintaining a better balance between base and new classes.
RPCANet++: Deep Interpretable Robust PCA for Sparse Object Segmentation
Aug 06, 2025



Robust principal component analysis (RPCA) decomposes an observation matrix into low-rank background and sparse object components. This capability has enabled its application in tasks ranging from image restoration to segmentation. However, traditional RPCA models suffer from computational burdens caused by matrix operations, reliance on finely tuned hyperparameters, and rigid priors that limit adaptability in dynamic scenarios. To solve these limitations, we propose RPCANet++, a sparse object segmentation framework that fuses the interpretability of RPCA with efficient deep architectures. Our approach unfolds a relaxed RPCA model into a structured network comprising a Background Approximation Module (BAM), an Object Extraction Module (OEM), and an Image Restoration Module (IRM). To mitigate inter-stage transmission loss in the BAM, we introduce a Memory-Augmented Module (MAM) to enhance background feature preservation, while a Deep Contrast Prior Module (DCPM) leverages saliency cues to expedite object extraction. Extensive experiments on diverse datasets demonstrate that RPCANet++ achieves state-of-the-art performance under various imaging scenarios. We further improve interpretability via visual and numerical low-rankness and sparsity measurements. By combining the theoretical strengths of RPCA with the efficiency of deep networks, our approach sets a new baseline for reliable and interpretable sparse object segmentation. Codes are available at our Project Webpage https://fengyiwu98.github.io/rpcanetx.
HRVVS: A High-resolution Video Vasculature Segmentation Network via Hierarchical Autoregressive Residual Priors
Jul 30, 2025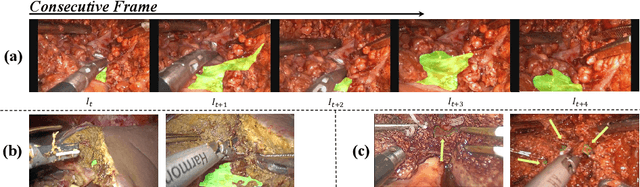
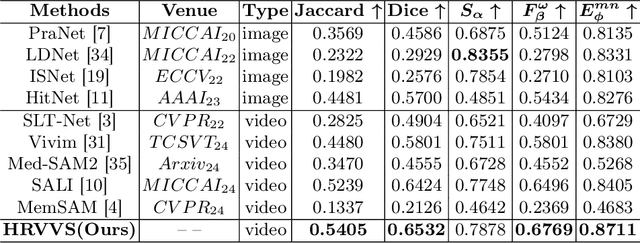
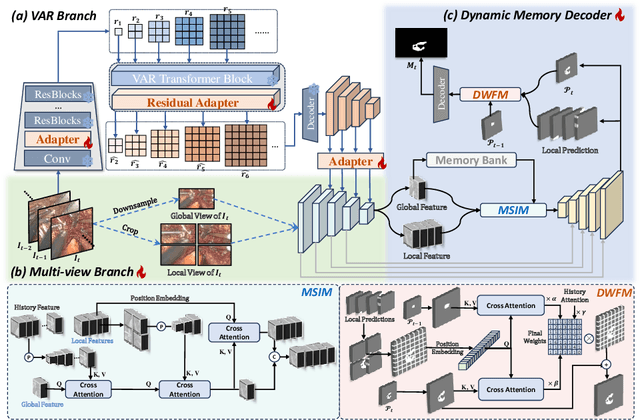
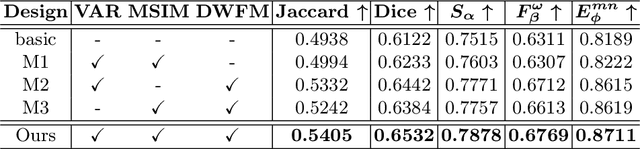
The segmentation of the hepatic vasculature in surgical videos holds substantial clinical significance in the context of hepatectomy procedures. However, owing to the dearth of an appropriate dataset and the inherently complex task characteristics, few researches have been reported in this domain. To address this issue, we first introduce a high quality frame-by-frame annotated hepatic vasculature dataset containing 35 long hepatectomy videos and 11442 high-resolution frames. On this basis, we propose a novel high-resolution video vasculature segmentation network, dubbed as HRVVS. We innovatively embed a pretrained visual autoregressive modeling (VAR) model into different layers of the hierarchical encoder as prior information to reduce the information degradation generated during the downsampling process. In addition, we designed a dynamic memory decoder on a multi-view segmentation network to minimize the transmission of redundant information while preserving more details between frames. Extensive experiments on surgical video datasets demonstrate that our proposed HRVVS significantly outperforms the state-of-the-art methods. The source code and dataset will be publicly available at \href{https://github.com/scott-yjyang/xx}{https://github.com/scott-yjyang/HRVVS}.
IFEvalCode: Controlled Code Generation
Jul 30, 2025Code large language models (Code LLMs) have made significant progress in code generation by translating natural language descriptions into functional code; however, real-world applications often demand stricter adherence to detailed requirements such as coding style, line count, and structural constraints, beyond mere correctness. To address this, the paper introduces forward and backward constraints generation to improve the instruction-following capabilities of Code LLMs in controlled code generation, ensuring outputs align more closely with human-defined guidelines. The authors further present IFEvalCode, a multilingual benchmark comprising 1.6K test samples across seven programming languages (Python, Java, JavaScript, TypeScript, Shell, C++, and C#), with each sample featuring both Chinese and English queries. Unlike existing benchmarks, IFEvalCode decouples evaluation into two metrics: correctness (Corr.) and instruction-following (Instr.), enabling a more nuanced assessment. Experiments on over 40 LLMs reveal that closed-source models outperform open-source ones in controllable code generation and highlight a significant gap between the models' ability to generate correct code versus code that precisely follows instructions.
VGGT-Long: Chunk it, Loop it, Align it -- Pushing VGGT's Limits on Kilometer-scale Long RGB Sequences
Jul 22, 2025Foundation models for 3D vision have recently demonstrated remarkable capabilities in 3D perception. However, extending these models to large-scale RGB stream 3D reconstruction remains challenging due to memory limitations. In this work, we propose VGGT-Long, a simple yet effective system that pushes the limits of monocular 3D reconstruction to kilometer-scale, unbounded outdoor environments. Our approach addresses the scalability bottlenecks of existing models through a chunk-based processing strategy combined with overlapping alignment and lightweight loop closure optimization. Without requiring camera calibration, depth supervision or model retraining, VGGT-Long achieves trajectory and reconstruction performance comparable to traditional methods. We evaluate our method on KITTI, Waymo, and Virtual KITTI datasets. VGGT-Long not only runs successfully on long RGB sequences where foundation models typically fail, but also produces accurate and consistent geometry across various conditions. Our results highlight the potential of leveraging foundation models for scalable monocular 3D scene in real-world settings, especially for autonomous driving scenarios. Code is available at https://github.com/DengKaiCQ/VGGT-Long.
AD-GS: Object-Aware B-Spline Gaussian Splatting for Self-Supervised Autonomous Driving
Jul 16, 2025Modeling and rendering dynamic urban driving scenes is crucial for self-driving simulation. Current high-quality methods typically rely on costly manual object tracklet annotations, while self-supervised approaches fail to capture dynamic object motions accurately and decompose scenes properly, resulting in rendering artifacts. We introduce AD-GS, a novel self-supervised framework for high-quality free-viewpoint rendering of driving scenes from a single log. At its core is a novel learnable motion model that integrates locality-aware B-spline curves with global-aware trigonometric functions, enabling flexible yet precise dynamic object modeling. Rather than requiring comprehensive semantic labeling, AD-GS automatically segments scenes into objects and background with the simplified pseudo 2D segmentation, representing objects using dynamic Gaussians and bidirectional temporal visibility masks. Further, our model incorporates visibility reasoning and physically rigid regularization to enhance robustness. Extensive evaluations demonstrate that our annotation-free model significantly outperforms current state-of-the-art annotation-free methods and is competitive with annotation-dependent approaches.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.