 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRVVS: A High-resolution Video Vasculature Segmentation Network via Hierarchical Autoregressive Residual Priors
Paper and Code
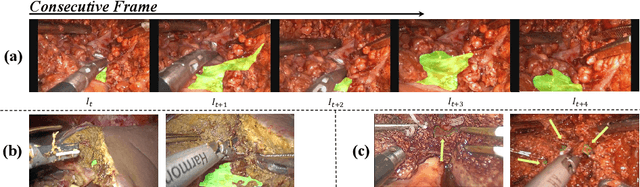
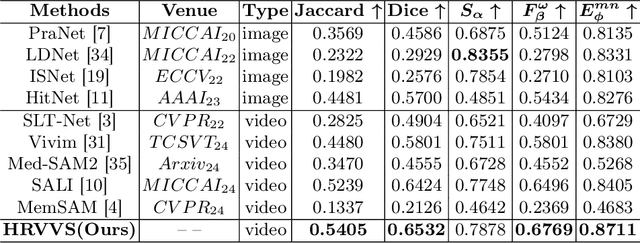
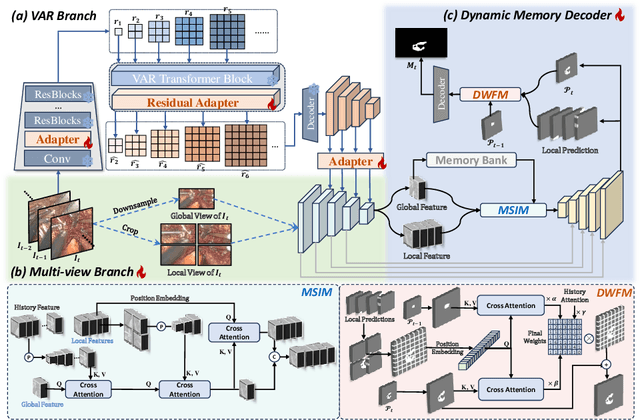
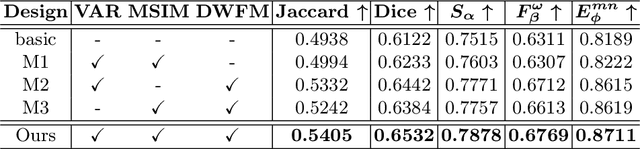
The segmentation of the hepatic vasculature in surgical videos holds substantial clinical significance in the context of hepatectomy procedures. However, owing to the dearth of an appropriate dataset and the inherently complex task characteristics, few researches have been reported in this domain. To address this issue, we first introduce a high quality frame-by-frame annotated hepatic vasculature dataset containing 35 long hepatectomy videos and 11442 high-resolution frames. On this basis, we propose a novel high-resolution video vasculature segmentation network, dubbed as HRVVS. We innovatively embed a pretrained visual autoregressive modeling (VAR) model into different layers of the hierarchical encoder as prior information to reduce the information degradation generated during the downsampling process. In addition, we designed a dynamic memory decoder on a multi-view segmentation network to minimize the transmission of redundant information while preserving more details between frames. Extensive experiments on surgical video datasets demonstrate that our proposed HRVVS significantly outperforms the state-of-the-art methods. The source code and dataset will be publicly available at \href{https://github.com/scott-yjyang/xx}{https://github.com/scott-yjyang/HRVVS}.