 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoMatGen: PBR Materials through Joint Generative Modeling
Mar 17, 2026We present a method for generating physically-based materials for 3D shapes based on a video diffusion transformer architecture. Our method is conditioned on input geometry and a text description, and jointly models multiple material properties (base color, roughness, metallicity, height map) to form physically plausible materials. We further introduce a custom variational auto-encoder which encodes multiple material modalities into a compact latent space, which enables joint generation of multiple modalities without increasing the number of tokens. Our pipeline generates high-quality materials for 3D shapes given a text prompt, compatible with common content creation tools.
VideoNeuMat: Neural Material Extraction from Generative Video Models
Feb 06, 2026Creating photorealistic materials for 3D rendering requires exceptional artistic skill. Generative models for materials could help, but are currently limited by the lack of high-quality training data. While recent video generative models effortlessly produce realistic material appearances, this knowledge remains entangled with geometry and lighting. We present VideoNeuMat, a two-stage pipeline that extracts reusable neural material assets from video diffusion models. First, we finetune a large video model (Wan 2.1 14B) to generate material sample videos under controlled camera and lighting trajectories, effectively creating a "virtual gonioreflectometer" that preserves the model's material realism while learning a structured measurement pattern. Second, we reconstruct compact neural materials from these videos through a Large Reconstruction Model (LRM) finetuned from a smaller Wan 1.3B video backbone. From 17 generated video frames, our LRM performs single-pass inference to predict neural material parameters that generalize to novel viewing and lighting conditions. The resulting materials exhibit realism and diversity far exceeding the limited synthetic training data, demonstrating that material knowledge can be successfully transferred from internet-scale video models into standalone, reusable neural 3D assets.
HiMat: DiT-based Ultra-High Resolution SVBRDF Generation
Aug 12, 2025



Creating highly detailed SVBRDFs is essential for 3D content creation. The rise of high-resolution text-to-image generative models, based on diffusion transformers (DiT), suggests an opportunity to finetune them for this task. However, retargeting the models to produce multiple aligned SVBRDF maps instead of just RGB images, while achieving high efficiency and ensuring consistency across different maps, remains a challenge. In this paper, we introduce HiMat: a memory- and computation-efficient diffusion-based framework capable of generating native 4K-resolution SVBRDFs. A key challenge we address is maintaining consistency across different maps in a lightweight manner, without relying on training new VAEs or significantly altering the DiT backbone (which would damage its prior capabilities). To tackle this, we introduce the CrossStitch module, a lightweight convolutional module that captures inter-map dependencies through localized operations. Its weights are initialized such that the DiT backbone operation is unchanged before finetuning starts. HiMat enables generation with strong structural coherence and high-frequency details. Results with a large set of text prompts demonstrate the effectiveness of our approach for 4K SVBRDF generation. Further experiments suggest generalization to tasks such as intrinsic decomposition.
Buffer Anytime: Zero-Shot Video Depth and Normal from Image Priors
Nov 26, 2024We present Buffer Anytime, a framework for estimation of depth and normal maps (which we call geometric buffers) from video that eliminates the need for paired video--depth and video--normal training data. Instead of relying on large-scale annotated video datasets, we demonstrate high-quality video buffer estimation by leveraging single-image priors with temporal consistency constraints. Our zero-shot training strategy combines state-of-the-art image estimation models based on optical flow smoothness through a hybrid loss function, implemented via a lightweight temporal attention architecture. Applied to leading image models like Depth Anything V2 and Marigold-E2E-FT, our approach significantly improves temporal consistency while maintaining accuracy. Experiments show that our method not only outperforms image-based approaches but also achieves results comparable to state-of-the-art video models trained on large-scale paired video datasets, despite using no such paired video data.
RelitLRM: Generative Relightable Radiance for Large Reconstruction Models
Oct 10, 2024



We propose RelitLRM, a Large Reconstruction Model (LRM) for generating high-quality Gaussian splatting representations of 3D objects under novel illuminations from sparse (4-8) posed images captured under unknown static lighting. Unlike prior inverse rendering methods requiring dense captures and slow optimization, often causing artifacts like incorrect highlights or shadow baking, RelitLRM adopts a feed-forward transformer-based model with a novel combination of a geometry reconstructor and a relightable appearance generator based on diffusion. The model is trained end-to-end on synthetic multi-view renderings of objects under varying known illuminations. This architecture design enables to effectively decompose geometry and appearance, resolve the ambiguity between material and lighting, and capture the multi-modal distribution of shadows and specularity in the relit appearance. We show our sparse-view feed-forward RelitLRM offers competitive relighting results to state-of-the-art dense-view optimization-based baselines while being significantly faster. Our project page is available at: https://relit-lrm.github.io/.
TexSliders: Diffusion-Based Texture Editing in CLIP Space
May 01, 2024



Generative models have enabled intuitive image creation and manipulation using natural language. In particular, diffusion models have recently shown remarkable results for natural image editing. In this work, we propose to apply diffusion techniques to edit textures, a specific class of images that are an essential part of 3D content creation pipelines. We analyze existing editing methods and show that they are not directly applicable to textures, since their common underlying approach, manipulating attention maps, is unsuitable for the texture domain. To address this, we propose a novel approach that instead manipulates CLIP image embeddings to condition the diffusion generation. We define editing directions using simple text prompts (e.g., "aged wood" to "new wood") and map these to CLIP image embedding space using a texture prior, with a sampling-based approach that gives us identity-preserving directions in CLIP space. To further improve identity preservation, we project these directions to a CLIP subspace that minimizes identity variations resulting from entangled texture attributes. Our editing pipeline facilitates the creation of arbitrary sliders using natural language prompts only, with no ground-truth annotated data necessary.
A Bayesian Inference Framework for Procedural Material Parameter Estimation
Dec 05, 2019

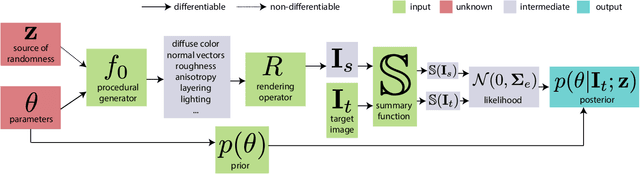

Procedural material models have been gaining traction in many applications thanks to their flexibility, compactness, and easy editability. In this paper, we explore the inverse rendering problem of procedural material parameter estimation from photographs using a Bayesian framework. We use \emph{summary functions} for comparing unregistered images of a material under known lighting, and we explore both hand-designed and neural summary functions. In addition to estimating the parameters by optimization, we introduce a Bayesian inference approach using Hamiltonian Monte Carlo to sample the space of plausible material parameters, providing additional insight into the structure of the solution space. To demonstrate the effectiveness of our techniques, we fit procedural models of a range of materials---wall plaster, leather, wood, anisotropic brushed metals and metallic paints---to both synthetic and real target images.