 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiajun Zhang
Sequence Generation: From Both Sides to the Middle
Jun 23, 2019
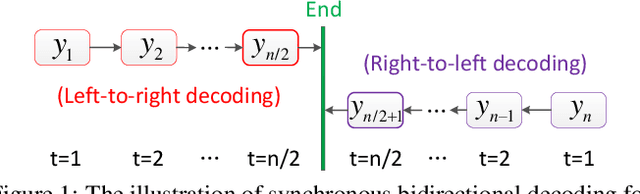
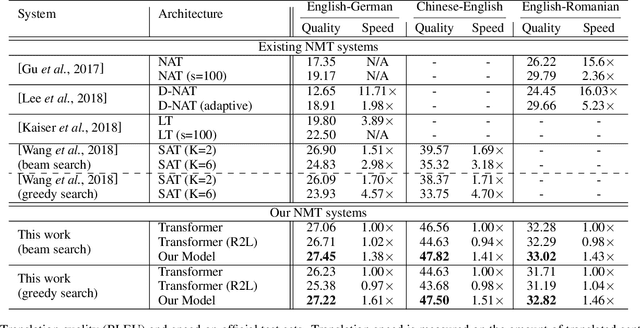
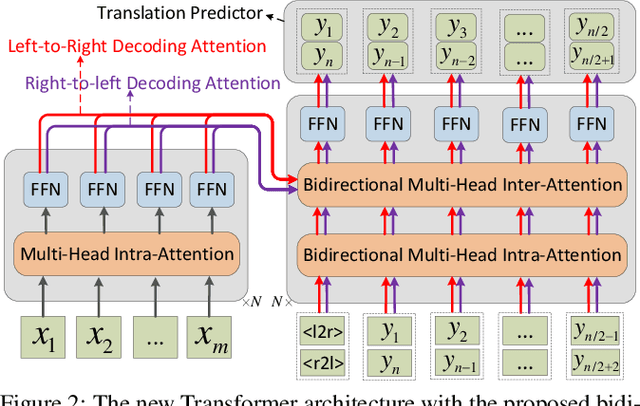

The encoder-decoder framework has achieved promising process for many sequence generation tasks, such as neural machine translation and text summarization. Such a framework usually generates a sequence token by token from left to right, hence (1) this autoregressive decoding procedure is time-consuming when the output sentence becomes longer, and (2) it lacks the guidance of future context which is crucial to avoid under translation. To alleviate these issues, we propose a synchronous bidirectional sequence generation (SBSG) model which predicts its outputs from both sides to the middle simultaneously. In the SBSG model, we enable the left-to-right (L2R) and right-to-left (R2L) generation to help and interact with each other by leveraging interactive bidirectional attention network. Experiments on neural machine translation (En-De, Ch-En, and En-Ro) and text summarization tasks show that the proposed model significantly speeds up decoding while improving the generation quality compared to the autoregressive Transformer.
Incremental Learning from Scratch for Task-Oriented Dialogue Systems
Jun 12, 2019

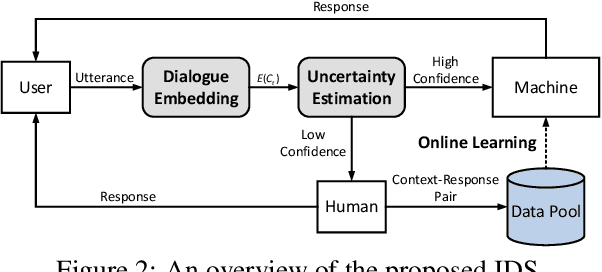
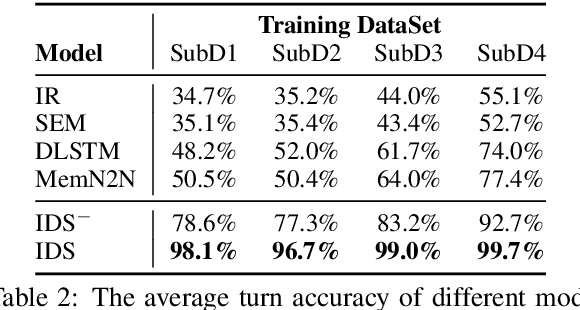
Clarifying user needs is essential for existing task-oriented dialogue systems. However, in real-world applications, developers can never guarantee that all possible user demands are taken into account in the design phase. Consequently, existing systems will break down when encountering unconsidered user needs. To address this problem, we propose a novel incremental learning framework to design task-oriented dialogue systems, or for short Incremental Dialogue System (IDS), without pre-defining the exhaustive list of user needs. Specifically, we introduce an uncertainty estimation module to evaluate the confidence of giving correct responses. If there is high confidence, IDS will provide responses to users. Otherwise, humans will be involved in the dialogue process, and IDS can learn from human intervention through an online learning module. To evaluate our method, we propose a new dataset which simulates unanticipated user needs in the deployment stage. Experiments show that IDS is robust to unconsidered user actions, and can update itself online by smartly selecting only the most effective training data, and hence attains better performance with less annotation cost.
Memory Consolidation for Contextual Spoken Language Understanding with Dialogue Logistic Inference
Jun 05, 2019
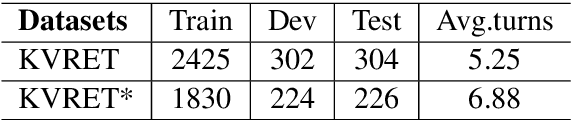
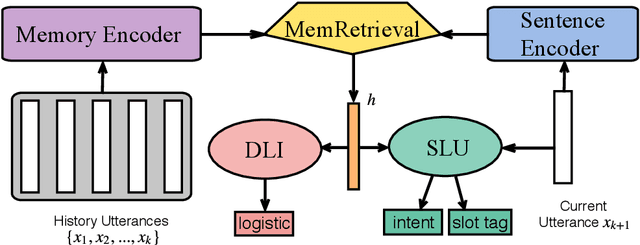
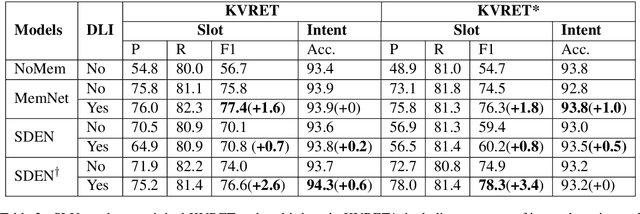
Dialogue contexts are proven helpful in the spoken language understanding (SLU) system and they are typically encoded with explicit memory representations. However, most of the previous models learn the context memory with only one objective to maximizing the SLU performance, leaving the context memory under-exploited. In this paper, we propose a new dialogue logistic inference (DLI) task to consolidate the context memory jointly with SLU in the multi-task framework. DLI is defined as sorting a shuffled dialogue session into its original logical order and shares the same memory encoder and retrieval mechanism as the SLU model. Our experimental results show that various popular contextual SLU models can benefit from our approach, and improvements are quite impressive, especially in slot filling.
Synchronous Bidirectional Neural Machine Translation
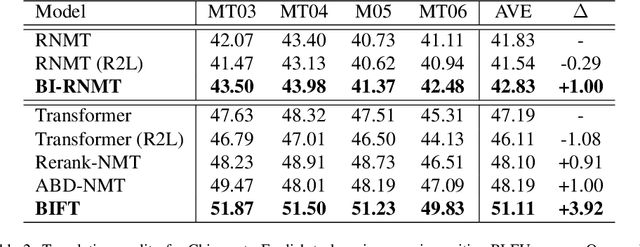
May 13, 2019Existing approaches to neural machine translation (NMT) generate the target language sequence token by token from left to right. However, this kind of unidirectional decoding framework cannot make full use of the target-side future contexts which can be produced in a right-to-left decoding direction, and thus suffers from the issue of unbalanced outputs. In this paper, we introduce a synchronous bidirectional neural machine translation (SB-NMT) that predicts its outputs using left-to-right and right-to-left decoding simultaneously and interactively, in order to leverage both of the history and future information at the same time. Specifically, we first propose a new algorithm that enables synchronous bidirectional decoding in a single model. Then, we present an interactive decoding model in which left-to-right (right-to-left) generation does not only depend on its previously generated outputs, but also relies on future contexts predicted by right-to-left (left-to-right) decoding. We extensively evaluate the proposed SB-NMT model on large-scale NIST Chinese-English, WMT14 English-German, and WMT18 Russian-English translation tasks. Experimental results demonstrate that our model achieves significant improvements over the strong Transformer model by 3.92, 1.49 and 1.04 BLEU points respectively, and obtains the state-of-the-art performance on Chinese-English and English-German translation tasks.
End-to-End Speech Translation with Knowledge Distillation
Apr 17, 2019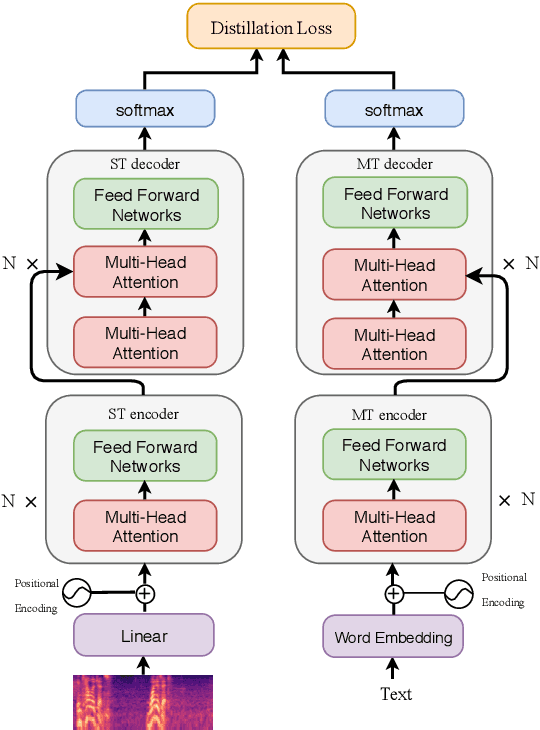
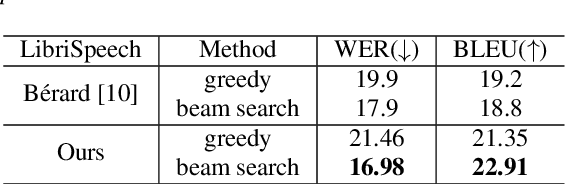
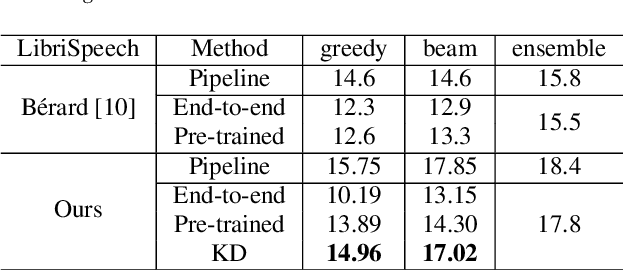
End-to-end speech translation (ST), which directly translates from source language speech into target language text, has attracted intensive attentions in recent years. Compared to conventional pipeline systems, end-to-end ST models have advantages of lower latency, smaller model size and less error propagation. However, the combination of speech recognition and text translation in one model is more difficult than each of these two tasks. In this paper, we propose a knowledge distillation approach to improve ST model by transferring the knowledge from text translation model. Specifically, we first train a text translation model, regarded as a teacher model, and then ST model is trained to learn output probabilities from teacher model through knowledge distillation. Experiments on English- French Augmented LibriSpeech and English-Chinese TED corpus show that end-to-end ST is possible to implement on both similar and dissimilar language pairs. In addition, with the instruction of teacher model, end-to-end ST model can gain significant improvements by over 3.5 BLEU points.
Synchronous Bidirectional Inference for Neural Sequence Generation
Feb 24, 2019
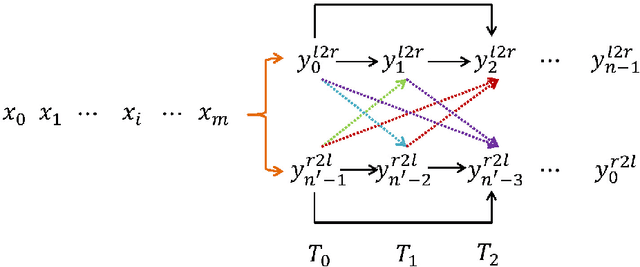
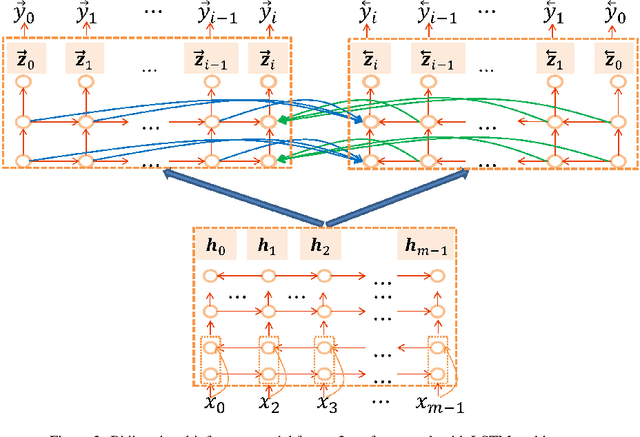
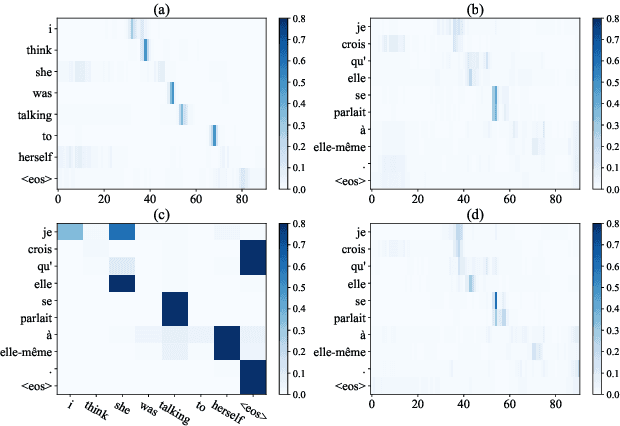
In sequence to sequence generation tasks (e.g. machine translation and abstractive summarization), inference is generally performed in a left-to-right manner to produce the result token by token. The neural approaches, such as LSTM and self-attention networks, are now able to make full use of all the predicted history hypotheses from left side during inference, but cannot meanwhile access any future (right side) information and usually generate unbalanced outputs in which left parts are much more accurate than right ones. In this work, we propose a synchronous bidirectional inference model to generate outputs using both left-to-right and right-to-left decoding simultaneously and interactively. First, we introduce a novel beam search algorithm that facilitates synchronous bidirectional decoding. Then, we present the core approach which enables left-to-right and right-to-left decoding to interact with each other, so as to utilize both the history and future predictions simultaneously during inference. We apply the proposed model to both LSTM and self-attention networks. In addition, we propose two strategies for parameter optimization. The extensive experiments on machine translation and abstractive summarization demonstrate that our synchronous bidirectional inference model can achieve remarkable improvements over the strong baselines.
Language-Independent Representor for Neural Machine Translation
Nov 01, 2018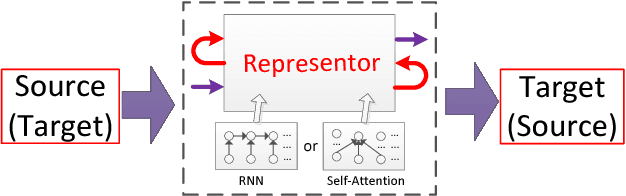
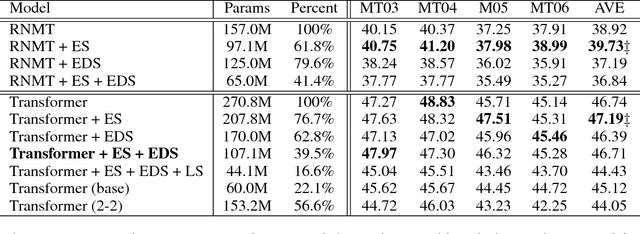
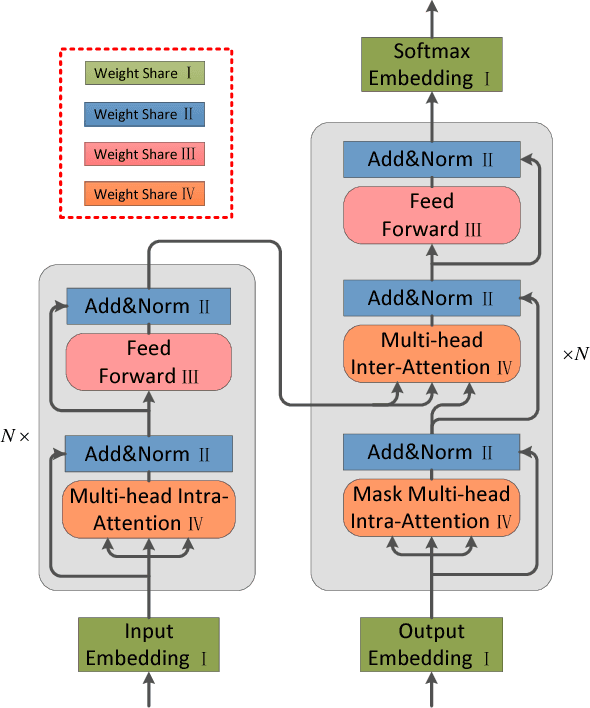

Current Neural Machine Translation (NMT) employs a language-specific encoder to represent the source sentence and adopts a language-specific decoder to generate target translation. This language-dependent design leads to large-scale network parameters and makes the duality of the parallel data underutilized. To address the problem, we propose in this paper a language-independent representor to replace the encoder and decoder by using weight sharing. This shared representor can not only reduce large portion of network parameters, but also facilitate us to fully explore the language duality by jointly training source-to-target, target-to-source, left-to-right and right-to-left translations within a multi-task learning framework. Experiments show that our proposed framework can obtain significant improvements over conventional NMT models on resource-rich and low-resource translation tasks with only a quarter of parameters.
Source-Critical Reinforcement Learning for Transferring Spoken Language Understanding to a New Language
Aug 22, 2018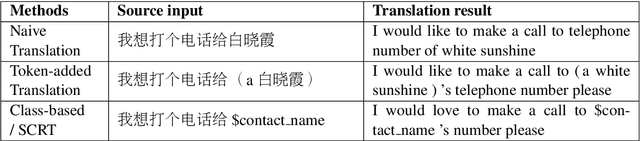
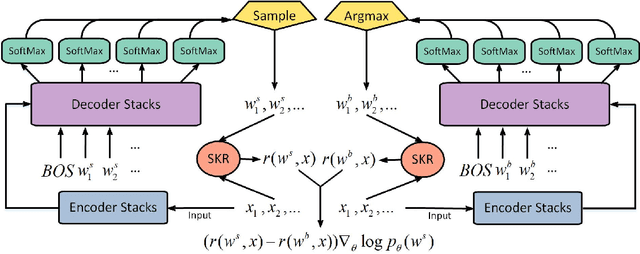
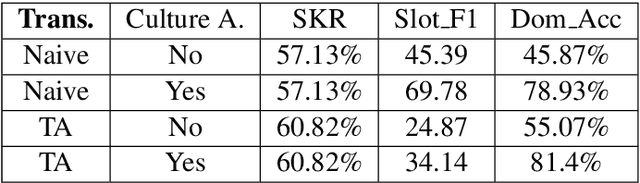
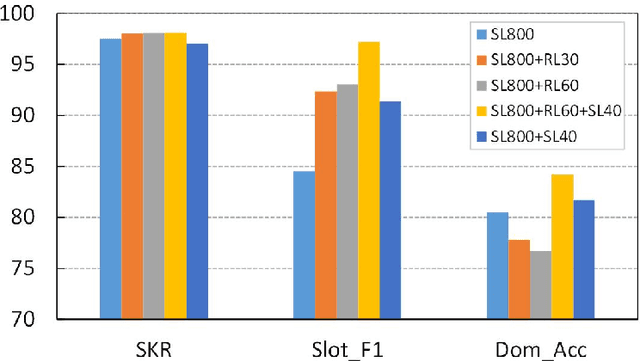
To deploy a spoken language understanding (SLU) model to a new language, language transferring is desired to avoid the trouble of acquiring and labeling a new big SLU corpus. Translating the original SLU corpus into the target language is an attractive strategy. However, SLU corpora consist of plenty of semantic labels (slots), which general-purpose translators cannot handle well, not to mention additional culture differences. This paper focuses on the language transferring task given a tiny in-domain parallel SLU corpus. The in-domain parallel corpus can be used as the first adaptation on the general translator. But more importantly, we show how to use reinforcement learning (RL) to further finetune the adapted translator, where translated sentences with more proper slot tags receive higher rewards. We evaluate our approach on Chinese to English language transferring for SLU systems. The experimental results show that the generated English SLU corpus via adaptation and reinforcement learning gives us over 97% in the slot F1 score and over 84% accuracy in domain classification. It demonstrates the effectiveness of the proposed language transferring method. Compared with naive translation, our proposed method improves domain classification accuracy by relatively 22%, and the slot filling F1 score by relatively more than 71%.
Phrase Table as Recommendation Memory for Neural Machine Translation
May 25, 2018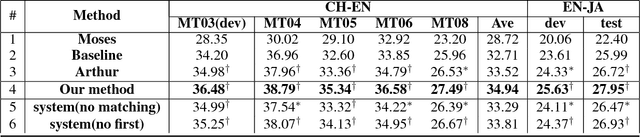
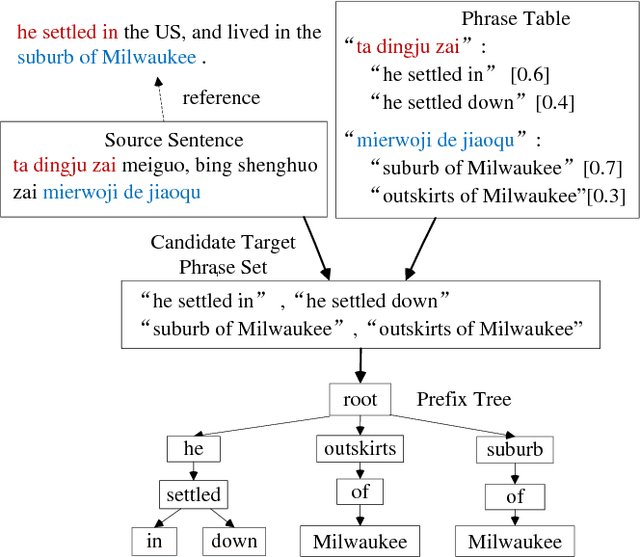


Neural Machine Translation (NMT) has drawn much attention due to its promising translation performance recently. However, several studies indicate that NMT often generates fluent but unfaithful translations. In this paper, we propose a method to alleviate this problem by using a phrase table as recommendation memory. The main idea is to add bonus to words worthy of recommendation, so that NMT can make correct predictions. Specifically, we first derive a prefix tree to accommodate all the candidate target phrases by searching the phrase translation table according to the source sentence. Then, we construct a recommendation word set by matching between candidate target phrases and previously translated target words by NMT. After that, we determine the specific bonus value for each recommendable word by using the attention vector and phrase translation probability. Finally, we integrate this bonus value into NMT to improve the translation results. The extensive experiments demonstrate that the proposed methods obtain remarkable improvements over the strong attentionbased NMT.
Learning Multimodal Word Representation via Dynamic Fusion Methods
Jan 02, 2018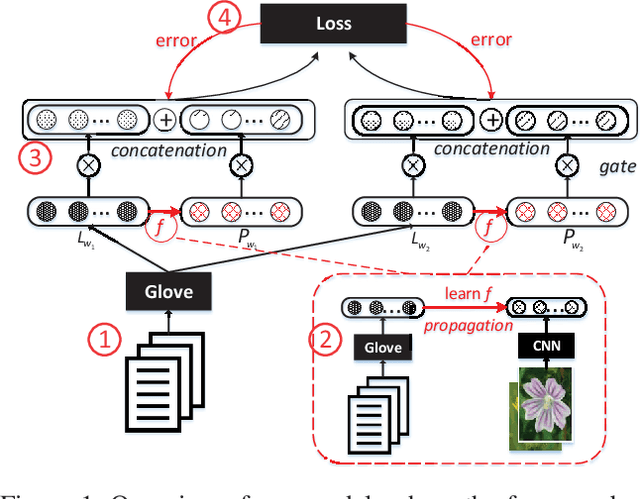
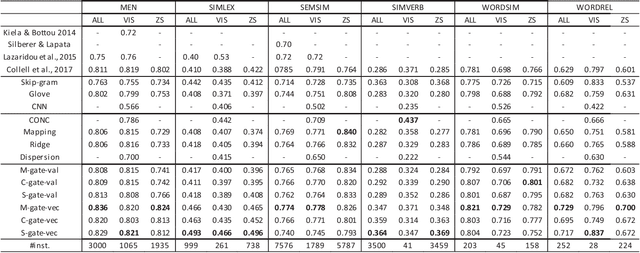
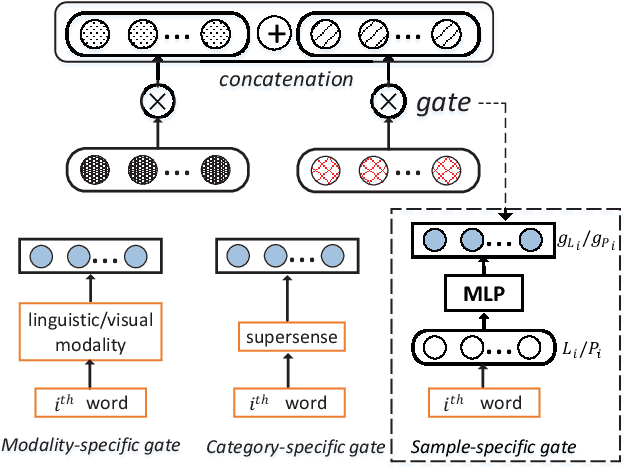
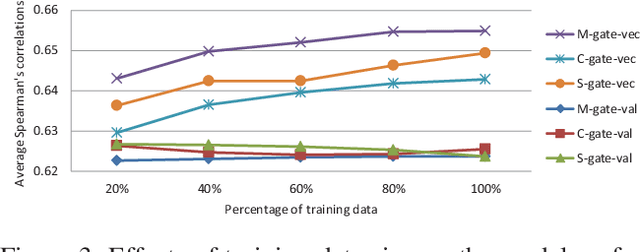
Multimodal models have been proven to outperform text-based models on learning semantic word representations. Almost all previous multimodal models typically treat the representations from different modalities equally. However, it is obvious that information from different modalities contributes differently to the meaning of words. This motivates us to build a multimodal model that can dynamically fuse the semantic representations from different modalities according to different types of words. To that end, we propose three novel dynamic fusion methods to assign importance weights to each modality, in which weights are learned under the weak supervision of word association pairs. The extensive experiments have demonstrated that the proposed methods outperform strong unimodal baselines and state-of-the-art multimodal models.