 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCa: Contrastive Captioners are Image-Text Foundation Models
May 04, 2022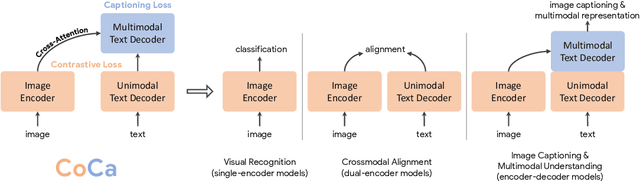

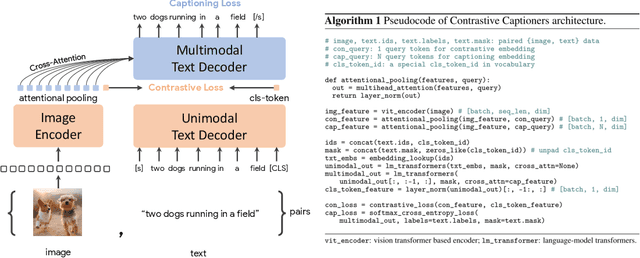
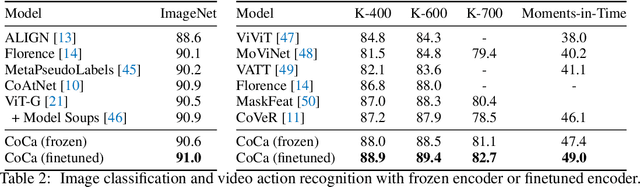
Exploring large-scale pretrained foundation models is of significant interest in computer vision because these models can be quickly transferred to many downstream tasks. This paper presents Contrastive Captioner (CoCa), a minimalist design to pretrain an image-text encoder-decoder foundation model jointly with contrastive loss and captioning loss, thereby subsuming model capabilities from contrastive approaches like CLIP and generative methods like SimVLM. In contrast to standard encoder-decoder transformers where all decoder layers attend to encoder outputs, CoCa omits cross-attention in the first half of decoder layers to encode unimodal text representations, and cascades the remaining decoder layers which cross-attend to the image encoder for multimodal image-text representations. We apply a contrastive loss between unimodal image and text embeddings, in addition to a captioning loss on the multimodal decoder outputs which predicts text tokens autoregressively. By sharing the same computational graph, the two training objectives are computed efficiently with minimal overhead. CoCa is pretrained end-to-end and from scratch on both web-scale alt-text data and annotated images by treating all labels simply as text, seamlessly unifying natural language supervision for representation learning. Empirically, CoCa achieves state-of-the-art performance with zero-shot transfer or minimal task-specific adaptation on a broad range of downstream tasks, spanning visual recognition (ImageNet, Kinetics-400/600/700, Moments-in-Time), crossmodal retrieval (MSCOCO, Flickr30K, MSR-VTT), multimodal understanding (VQA, SNLI-VE, NLVR2), and image captioning (MSCOCO, NoCaps). Notably on ImageNet classification, CoCa obtains 86.3% zero-shot top-1 accuracy, 90.6% with a frozen encoder and learned classification head, and new state-of-the-art 91.0% top-1 accuracy on ImageNet with a finetuned encoder.
Self-supervised Learning with Random-projection Quantizer for Speech Recognition
Feb 03, 2022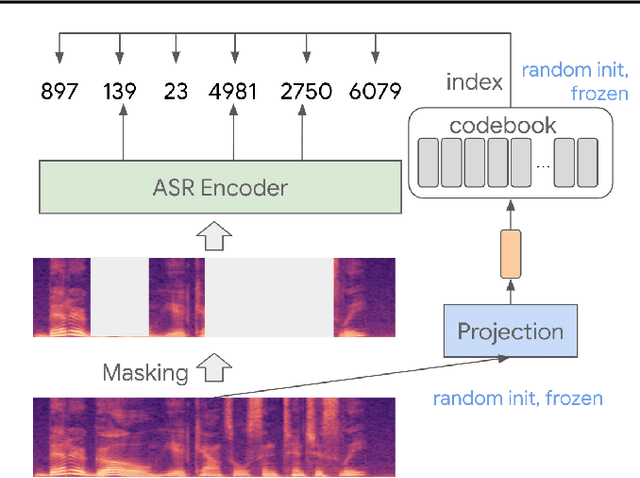

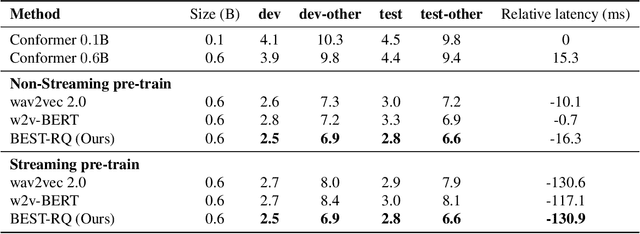
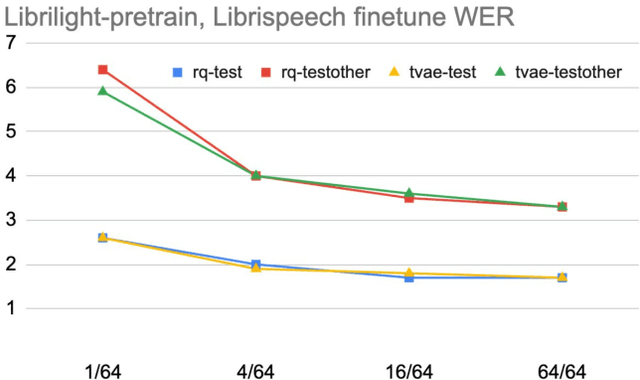
We present a simple and effective self-supervised learning approach for speech recognition. The approach learns a model to predict the masked speech signals, in the form of discrete labels generated with a random-projection quantizer. In particular the quantizer projects speech inputs with a randomly initialized matrix, and does a nearest-neighbor lookup in a randomly-initialized codebook. Neither the matrix nor the codebook is updated during self-supervised learning. Since the random-projection quantizer is not trained and is separated from the speech recognition model, the design makes the approach flexible and is compatible with universal speech recognition architecture. On LibriSpeech our approach achieves similar word-error-rates as previous work using self-supervised learning with non-streaming models, and provides lower word-error-rates and latency than wav2vec 2.0 and w2v-BERT with streaming models. On multilingual tasks the approach also provides significant improvement over wav2vec 2.0 and w2v-BERT.
Co-training Transformer with Videos and Images Improves Action Recognition
Dec 14, 2021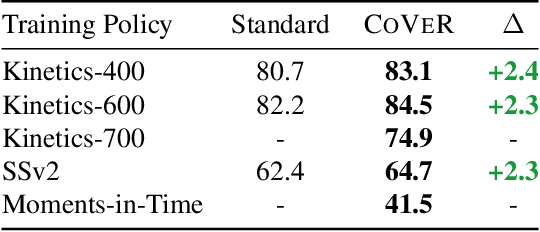
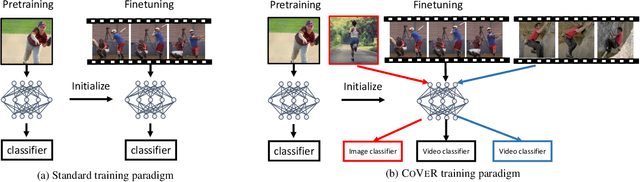

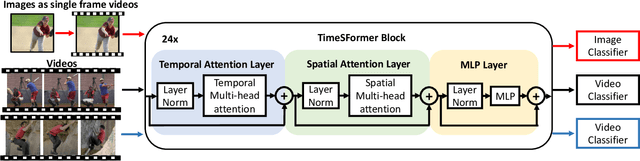
In learning action recognition, models are typically pre-trained on object recognition with images, such as ImageNet, and later fine-tuned on target action recognition with videos. This approach has achieved good empirical performance especially with recent transformer-based video architectures. While recently many works aim to design more advanced transformer architectures for action recognition, less effort has been made on how to train video transformers. In this work, we explore several training paradigms and present two findings. First, video transformers benefit from joint training on diverse video datasets and label spaces (e.g., Kinetics is appearance-focused while SomethingSomething is motion-focused). Second, by further co-training with images (as single-frame videos), the video transformers learn even better video representations. We term this approach as Co-training Videos and Images for Action Recognition (CoVeR). In particular, when pretrained on ImageNet-21K based on the TimeSFormer architecture, CoVeR improves Kinetics-400 Top-1 Accuracy by 2.4%, Kinetics-600 by 2.3%, and SomethingSomething-v2 by 2.3%. When pretrained on larger-scale image datasets following previous state-of-the-art, CoVeR achieves best results on Kinetics-400 (87.2%), Kinetics-600 (87.9%), Kinetics-700 (79.8%), SomethingSomething-v2 (70.9%), and Moments-in-Time (46.1%), with a simple spatio-temporal video transformer.
Vector-quantized Image Modeling with Improved VQGAN
Oct 09, 2021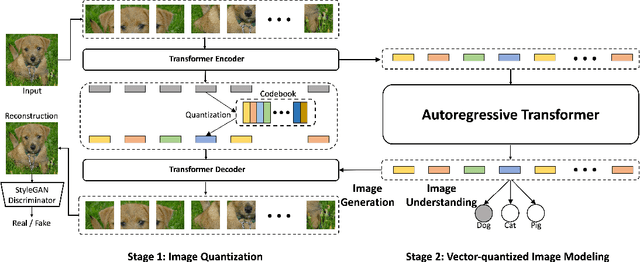



Pretraining language models with next-token prediction on massive text corpora has delivered phenomenal zero-shot, few-shot, transfer learning and multi-tasking capabilities on both generative and discriminative language tasks. Motivated by this success, we explore a Vector-quantized Image Modeling (VIM) approach that involves pretraining a Transformer to predict rasterized image tokens autoregressively. The discrete image tokens are encoded from a learned Vision-Transformer-based VQGAN (ViT-VQGAN). We first propose multiple improvements over vanilla VQGAN from architecture to codebook learning, yielding better efficiency and reconstruction fidelity. The improved ViT-VQGAN further improves vector-quantized image modeling tasks, including unconditional, class-conditioned image generation and unsupervised representation learning. When trained on ImageNet at 256x256 resolution, we achieve Inception Score (IS) of 175.1 and Fr'echet Inception Distance (FID) of 4.17, a dramatic improvement over the vanilla VQGAN, which obtains 70.6 and 17.04 for IS and FID, respectively. Based on ViT-VQGAN and unsupervised pretraining, we further evaluate the pretrained Transformer by averaging intermediate features, similar to Image GPT (iGPT). This ImageNet-pretrained VIM-L significantly beats iGPT-L on linear-probe accuracy from 60.3% to 72.2% for a similar model size. ViM-L also outperforms iGPT-XL which is trained with extra web image data and larger model size.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021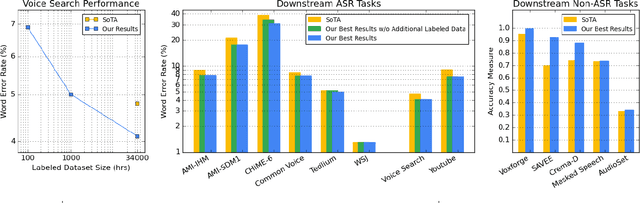
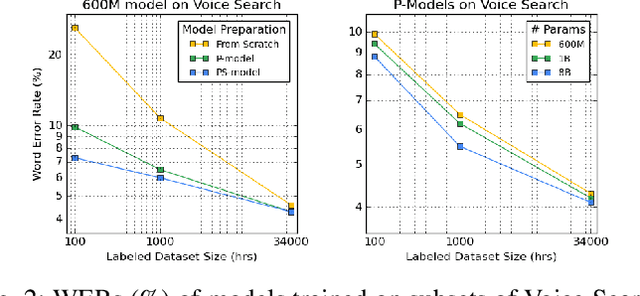
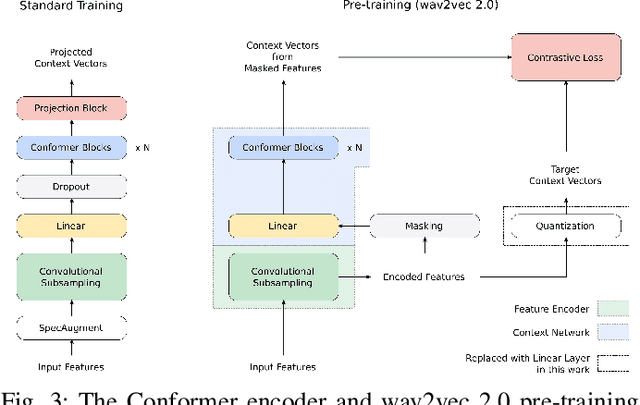
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
SimVLM: Simple Visual Language Model Pretraining with Weak Supervision
Aug 24, 2021
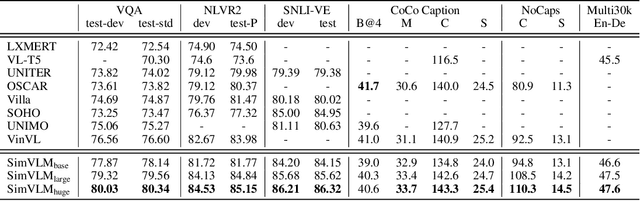
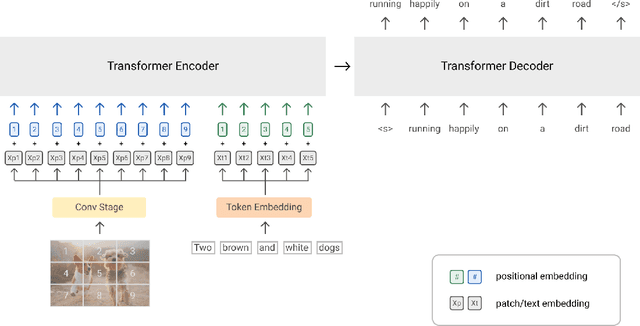
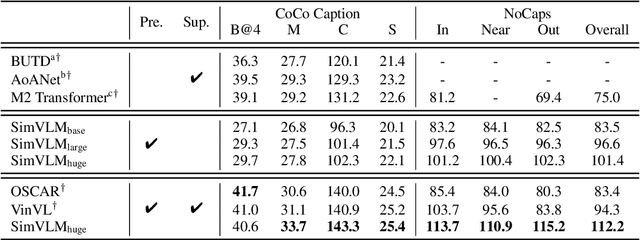
With recent progress in joint modeling of visual and textual representations, Vision-Language Pretraining (VLP) has achieved impressive performance on many multimodal downstream tasks. However, the requirement for expensive annotations including clean image captions and regional labels limits the scalability of existing approaches, and complicates the pretraining procedure with the introduction of multiple dataset-specific objectives. In this work, we relax these constraints and present a minimalist pretraining framework, named Simple Visual Language Model (SimVLM). Unlike prior work, SimVLM reduces the training complexity by exploiting large-scale weak supervision, and is trained end-to-end with a single prefix language modeling objective. Without utilizing extra data or task-specific customization, the resulting model significantly outperforms previous pretraining methods and achieves new state-of-the-art results on a wide range of discriminative and generative vision-language benchmarks, including VQA (+3.74% vqa-score), NLVR2 (+1.17% accuracy), SNLI-VE (+1.37% accuracy) and image captioning tasks (+10.1% average CIDEr score). Furthermore, we demonstrate that SimVLM acquires strong generalization and transfer ability, enabling zero-shot behavior including open-ended visual question answering and cross-modality transfer.
Normalization effects on shallow neural networks and related asymptotic expansions
Nov 20, 2020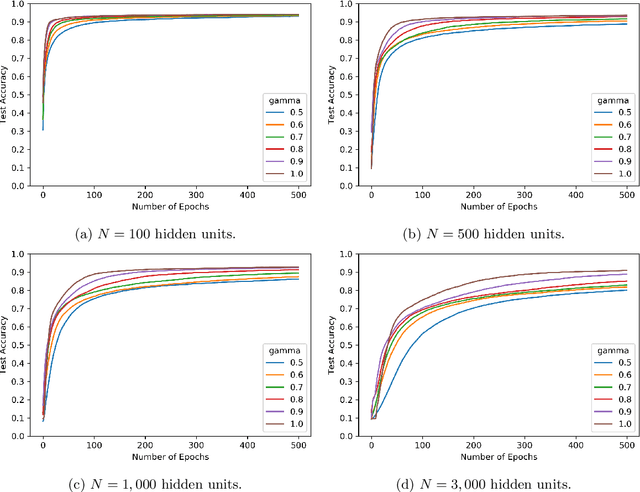
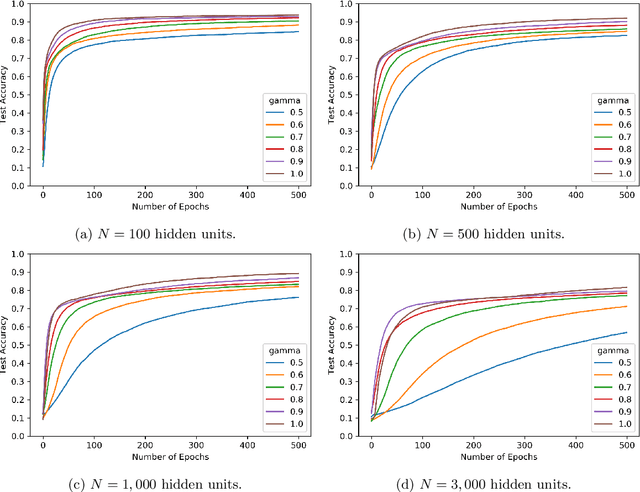
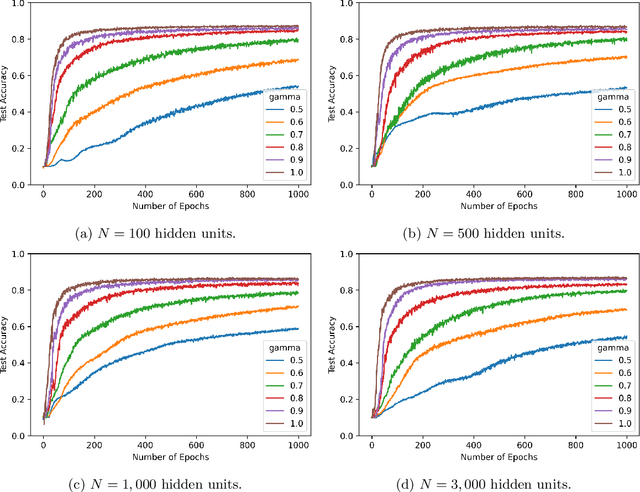
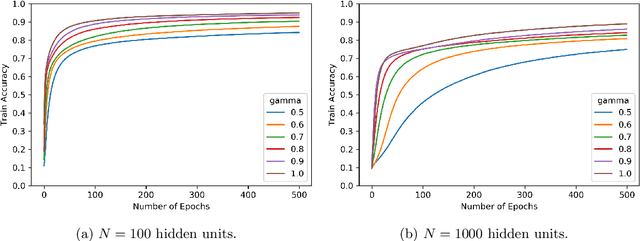
We consider shallow (single hidden layer) neural networks and characterize their performance when trained with stochastic gradient descent as the number of hidden units $N$ and gradient descent steps grow to infinity. In particular, we investigate the effect of different scaling schemes, which lead to different normalizations of the neural network, on the network's statistical output, closing the gap between the $1/\sqrt{N}$ and the mean-field $1/N$ normalization. We develop an asymptotic expansion for the neural network's statistical output pointwise with respect to the scaling parameter as the number of hidden units grows to infinity. Based on this expansion we demonstrate mathematically that to leading order in $N$ there is no bias-variance trade off, in that both bias and variance (both explicitly characterized) decrease as the number of hidden units increases and time grows. In addition, we show that to leading order in $N$, the variance of the neural network's statistical output decays as the implied normalization by the scaling parameter approaches the mean field normalization. Numerical studies on the MNIST and CIFAR10 datasets show that test and train accuracy monotonically improve as the neural network's normalization gets closer to the mean field normalization.
Cascaded encoders for unifying streaming and non-streaming ASR
Oct 27, 2020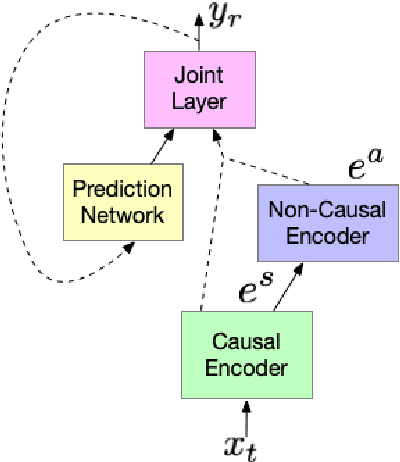
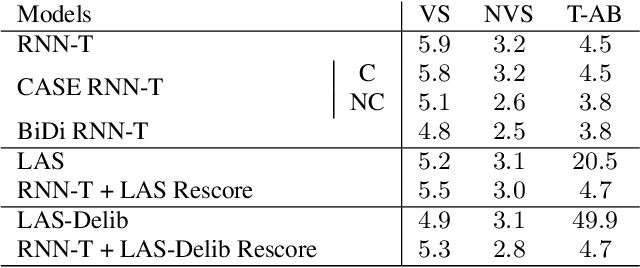
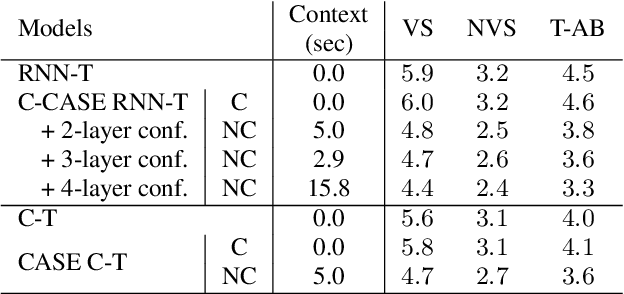
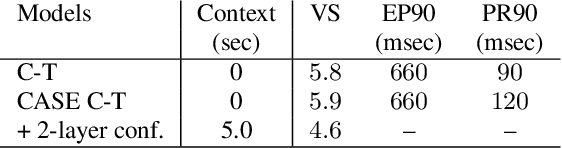
End-to-end (E2E) automatic speech recognition (ASR) models, by now, have shown competitive performance on several benchmarks. These models are structured to either operate in streaming or non-streaming mode. This work presents cascaded encoders for building a single E2E ASR model that can operate in both these modes simultaneously. The proposed model consists of streaming and non-streaming encoders. Input features are first processed by the streaming encoder; the non-streaming encoder operates exclusively on the output of the streaming encoder. A single decoder then learns to decode either using the output of the streaming or the non-streaming encoder. Results show that this model achieves similar word error rates (WER) as a standalone streaming model when operating in streaming mode, and obtains 10% -- 27% relative improvement when operating in non-streaming mode. Our results also show that the proposed approach outperforms existing E2E two-pass models, especially on long-form speech.
FastEmit: Low-latency Streaming ASR with Sequence-level Emission Regularization
Oct 21, 2020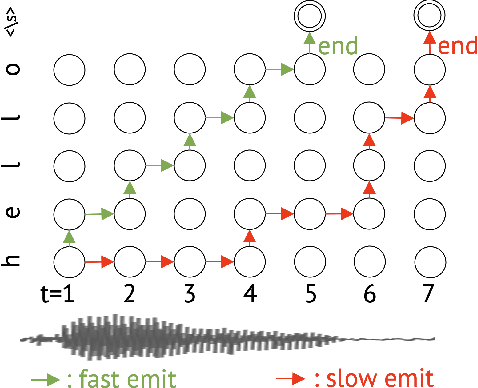
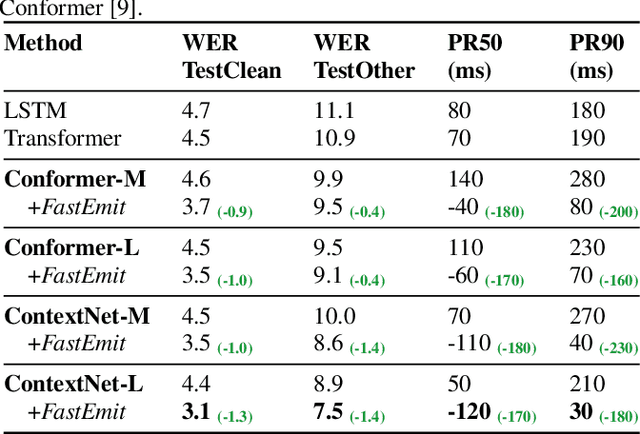

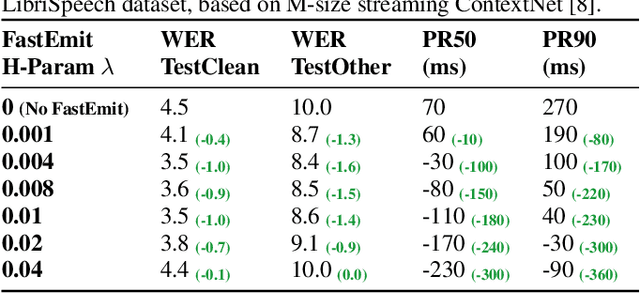
Streaming automatic speech recognition (ASR) aims to emit each hypothesized word as quickly and accurately as possible. However, emitting fast without degrading quality, as measured by word error rate (WER), is highly challenging. Existing approaches including Early and Late Penalties and Constrained Alignments penalize emission delay by manipulating per-token or per-frame probability prediction in sequence transducer models. While being successful in reducing delay, these approaches suffer from significant accuracy regression and also require additional word alignment information from an existing model. In this work, we propose a sequence-level emission regularization method, named FastEmit, that applies latency regularization directly on per-sequence probability in training transducer models, and does not require any alignment. We demonstrate that FastEmit is more suitable to the sequence-level optimization of transducer models for streaming ASR by applying it on various end-to-end streaming ASR networks including RNN-Transducer, Transformer-Transducer, ConvNet-Transducer and Conformer-Transducer. We achieve 150-300 ms latency reduction with significantly better accuracy over previous techniques on a Voice Search test set. FastEmit also improves streaming ASR accuracy from 4.4%/8.9% to 3.1%/7.5% WER, meanwhile reduces 90th percentile latency from 210 ms to only 30 ms on LibriSpeech.
Universal ASR: Unify and Improve Streaming ASR with Full-context Modeling
Oct 12, 2020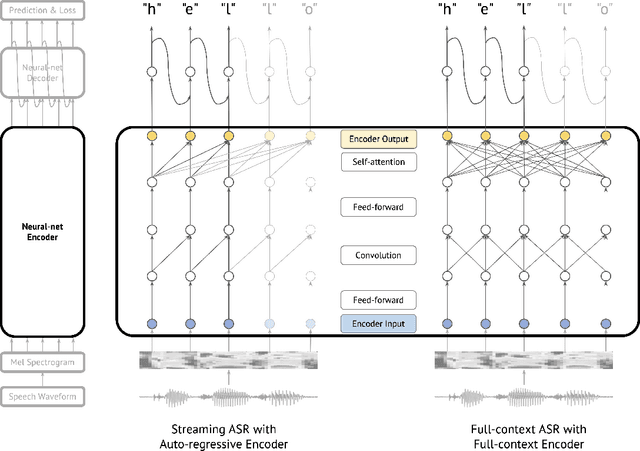
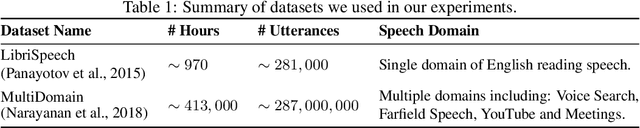
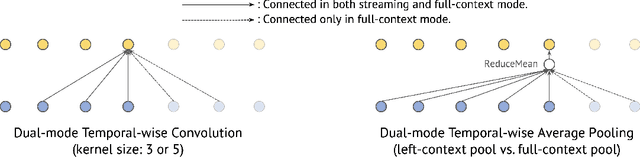
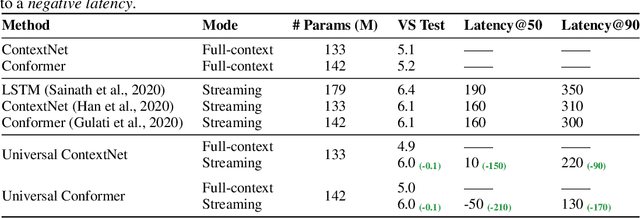
Streaming automatic speech recognition (ASR) aims to emit each hypothesized word as quickly and accurately as possible, while full-context ASR waits for the completion of a full speech utterance before emitting completed hypotheses. In this work, we propose a unified framework, Universal ASR, to train a single end-to-end ASR model with shared weights for both streaming and full-context speech recognition. We show that the latency and accuracy of streaming ASR significantly benefit from weight sharing and joint training of full-context ASR, especially with inplace knowledge distillation. The Universal ASR framework can be applied to recent state-of-the-art convolution-based and transformer-based ASR networks. We present extensive experiments with two state-of-the-art ASR networks, ContextNet and Conformer, on two datasets, a widely used public dataset LibriSpeech and an internal large-scale dataset MultiDomain. Experiments and ablation studies demonstrate that Universal ASR not only simplifies the workflow of training and deploying streaming and full-context ASR models, but also significantly improves both emission latency and recognition accuracy of streaming ASR. With Universal ASR, we achieve new state-of-the-art streaming ASR results on both LibriSpeech and MultiDomain in terms of accuracy and latency.