 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-wise Smoothing for Certified Robustness against Camera Motion Perturbations
Sep 22, 2023



In recent years, computer vision has made remarkable advancements in autonomous driving and robotics. However, it has been observed that deep learning-based visual perception models lack robustness when faced with camera motion perturbations. The current certification process for assessing robustness is costly and time-consuming due to the extensive number of image projections required for Monte Carlo sampling in the 3D camera motion space. To address these challenges, we present a novel, efficient, and practical framework for certifying the robustness of 3D-2D projective transformations against camera motion perturbations. Our approach leverages a smoothing distribution over the 2D pixel space instead of in the 3D physical space, eliminating the need for costly camera motion sampling and significantly enhancing the efficiency of robustness certifications. With the pixel-wise smoothed classifier, we are able to fully upper bound the projection errors using a technique of uniform partitioning in camera motion space. Additionally, we extend our certification framework to a more general scenario where only a single-frame point cloud is required in the projection oracle. This is achieved by deriving Lipschitz-based approximated partition intervals. Through extensive experimentation, we validate the trade-off between effectiveness and efficiency enabled by our proposed method. Remarkably, our approach achieves approximately 80% certified accuracy while utilizing only 30% of the projected image frames.
Interactive Car-Following: Matters but NOT Always
Jul 30, 2023



Following a leading vehicle is a daily but challenging task because it requires adapting to various traffic conditions and the leading vehicle's behaviors. However, the question `Does the following vehicle always actively react to the leading vehicle?' remains open. To seek the answer, we propose a novel metric to quantify the interaction intensity within the car-following pairs. The quantified interaction intensity enables us to recognize interactive and non-interactive car-following scenarios and derive corresponding policies for each scenario. Then, we develop an interaction-aware switching control framework with interactive and non-interactive policies, achieving a human-level car-following performance. The extensive simulations demonstrate that our interaction-aware switching control framework achieves improved control performance and data efficiency compared to the unified control strategies. Moreover, the experimental results reveal that human drivers would not always keep reacting to their leading vehicle but occasionally take safety-critical or intentional actions -- interaction matters but not always.
Datasets and Benchmarks for Offline Safe Reinforcement Learning
Jun 16, 2023



This paper presents a comprehensive benchmarking suite tailored to offline safe reinforcement learning (RL) challenges, aiming to foster progress in the development and evaluation of safe learning algorithms in both the training and deployment phases. Our benchmark suite contains three packages: 1) expertly crafted safe policies, 2) D4RL-styled datasets along with environment wrappers, and 3) high-quality offline safe RL baseline implementations. We feature a methodical data collection pipeline powered by advanced safe RL algorithms, which facilitates the generation of diverse datasets across 38 popular safe RL tasks, from robot control to autonomous driving. We further introduce an array of data post-processing filters, capable of modifying each dataset's diversity, thereby simulating various data collection conditions. Additionally, we provide elegant and extensible implementations of prevalent offline safe RL algorithms to accelerate research in this area. Through extensive experiments with over 50000 CPU and 800 GPU hours of computations, we evaluate and compare the performance of these baseline algorithms on the collected datasets, offering insights into their strengths, limitations, and potential areas of improvement. Our benchmarking framework serves as a valuable resource for researchers and practitioners, facilitating the development of more robust and reliable offline safe RL solutions in safety-critical applications. The benchmark website is available at \url{www.offline-saferl.org}.
MultiSum: A Dataset for Multimodal Summarization and Thumbnail Generation of Videos
Jun 07, 2023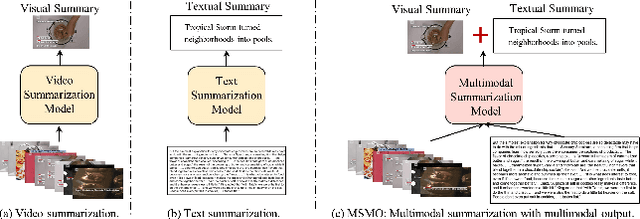
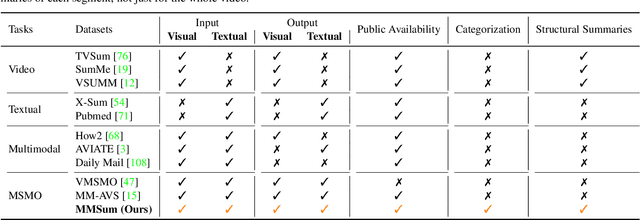
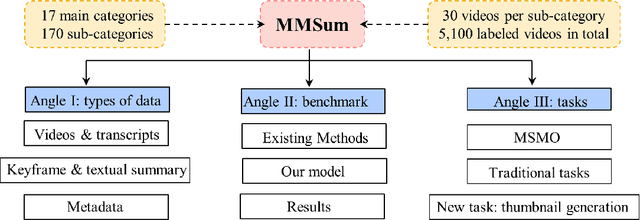
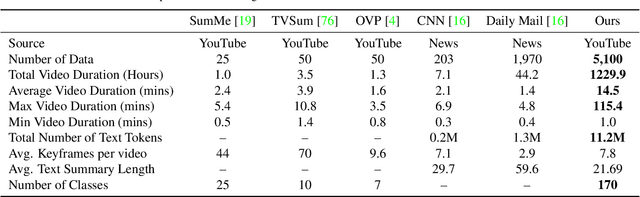
Multimodal summarization with multimodal output (MSMO) has emerged as a promising research direction. Nonetheless, numerous limitations exist within existing public MSMO datasets, including insufficient upkeep, data inaccessibility, limited size, and the absence of proper categorization, which pose significant challenges to effective research. To address these challenges and provide a comprehensive dataset for this new direction, we have meticulously curated the MultiSum dataset. Our new dataset features (1) Human-validated summaries for both video and textual content, providing superior human instruction and labels for multimodal learning. (2) Comprehensively and meticulously arranged categorization, spanning 17 principal categories and 170 subcategories to encapsulate a diverse array of real-world scenarios. (3) Benchmark tests performed on the proposed dataset to assess varied tasks and methods, including video temporal segmentation, video summarization, text summarization, and multimodal summarization. To champion accessibility and collaboration, we release the MultiSum dataset and the data collection tool as fully open-source resources, fostering transparency and accelerating future developments. Our project website can be found at https://multisum-dataset.github.io/.
Multimodal Representation Learning of Cardiovascular Magnetic Resonance Imaging
Apr 16, 2023Self-supervised learning is crucial for clinical imaging applications, given the lack of explicit labels in healthcare. However, conventional approaches that rely on precise vision-language alignment are not always feasible in complex clinical imaging modalities, such as cardiac magnetic resonance (CMR). CMR provides a comprehensive visualization of cardiac anatomy, physiology, and microstructure, making it challenging to interpret. Additionally, CMR reports require synthesizing information from sequences of images and different views, resulting in potentially weak alignment between the study and diagnosis report pair. To overcome these challenges, we propose \textbf{CMRformer}, a multimodal learning framework to jointly learn sequences of CMR images and associated cardiologist's reports. Moreover, one of the major obstacles to improving CMR study is the lack of large, publicly available datasets. To bridge this gap, we collected a large \textbf{CMR dataset}, which consists of 13,787 studies from clinical cases. By utilizing our proposed CMRformer and our collected dataset, we achieved remarkable performance in real-world clinical tasks, such as CMR image retrieval and diagnosis report retrieval. Furthermore, the learned representations are evaluated to be practically helpful for downstream applications, such as disease classification. Our work could potentially expedite progress in the CMR study and lead to more accurate and effective diagnosis and treatment.
Converting ECG Signals to Images for Efficient Image-text Retrieval via Encoding
Apr 13, 2023



Automated interpretation of electrocardiograms (ECG) has garnered significant attention with the advancements in machine learning methodologies. Despite the growing interest in automated ECG interpretation using machine learning, most current studies focus solely on classification or regression tasks and overlook a crucial aspect of clinical cardio-disease diagnosis: the diagnostic report generated by experienced human clinicians. In this paper, we introduce a novel approach to ECG interpretation, leveraging recent breakthroughs in Large Language Models (LLMs) and Vision-Transformer (ViT) models. Rather than treating ECG diagnosis as a classification or regression task, we propose an alternative method of automatically identifying the most similar clinical cases based on the input ECG data. Also, since interpreting ECG as images are more affordable and accessible, we process ECG as encoded images and adopt a vision-language learning paradigm to jointly learn vision-language alignment between encoded ECG images and ECG diagnosis reports. Encoding ECG into images can result in an efficient ECG retrieval system, which will be highly practical and useful in clinical applications. More importantly, our findings could serve as a crucial resource for providing diagnostic services in regions where only paper-printed ECG images are accessible due to past underdevelopment.
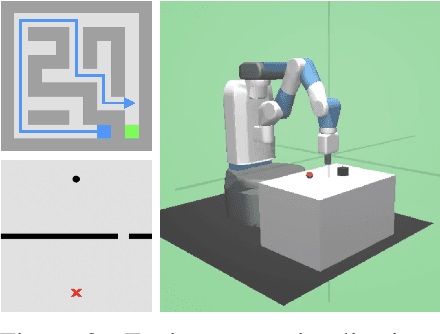
GOATS: Goal Sampling Adaptation for Scooping with Curriculum Reinforcement Learning
Mar 09, 2023



In this work, we first formulate the problem of goal-conditioned robotic water scooping with reinforcement learning. This task is challenging due to the complex dynamics of fluid and multi-modal goal-reaching. The policy is required to achieve both position goals and water amount goals, which leads to a large convoluted goal state space. To address these challenges, we introduce Goal Sampling Adaptation for Scooping (GOATS), a curriculum reinforcement learning method that can learn an effective and generalizable policy for robot scooping tasks. Specifically, we use a goal-factorized reward formulation and interpolate position goal distributions and amount goal distributions to create curriculum through the learning process. As a result, our proposed method can outperform the baselines in simulation and achieves 5.46% and 8.71% amount errors on bowl scooping and bucket scooping tasks, respectively, under 1000 variations of initial water states in the tank and a large goal state space. Besides being effective in simulation environments, our method can efficiently generalize to noisy real-robot water-scooping scenarios with different physical configurations and unseen settings, demonstrating superior efficacy and generalizability. The videos of this work are available on our project page: https://sites.google.com/view/goatscooping.
Interpolation for Robust Learning: Data Augmentation on Geodesics
Feb 07, 2023



We propose to study and promote the robustness of a model as per its performance through the interpolation of training data distributions. Specifically, (1) we augment the data by finding the worst-case Wasserstein barycenter on the geodesic connecting subpopulation distributions of different categories. (2) We regularize the model for smoother performance on the continuous geodesic path connecting subpopulation distributions. (3) Additionally, we provide a theoretical guarantee of robustness improvement and investigate how the geodesic location and the sample size contribute, respectively. Experimental validations of the proposed strategy on four datasets, including CIFAR-100 and ImageNet, establish the efficacy of our method, e.g., our method improves the baselines' certifiable robustness on CIFAR10 up to $7.7\%$, with $16.8\%$ on empirical robustness on CIFAR-100. Our work provides a new perspective of model robustness through the lens of Wasserstein geodesic-based interpolation with a practical off-the-shelf strategy that can be combined with existing robust training methods.
Transfer Knowledge from Natural Language to Electrocardiography: Can We Detect Cardiovascular Disease Through Language Models?
Jan 21, 2023



Recent advancements in Large Language Models (LLMs) have drawn increasing attention since the learned embeddings pretrained on large-scale datasets have shown powerful ability in various downstream applications. However, whether the learned knowledge by LLMs can be transferred to clinical cardiology remains unknown. In this work, we aim to bridge this gap by transferring the knowledge of LLMs to clinical Electrocardiography (ECG). We propose an approach for cardiovascular disease diagnosis and automatic ECG diagnosis report generation. We also introduce an additional loss function by Optimal Transport (OT) to align the distribution between ECG and language embedding. The learned embeddings are evaluated on two downstream tasks: (1) automatic ECG diagnosis report generation, and (2) zero-shot cardiovascular disease detection. Our approach is able to generate high-quality cardiac diagnosis reports and also achieves competitive zero-shot classification performance even compared with supervised baselines, which proves the feasibility of transferring knowledge from LLMs to the cardiac domain.
Curriculum Reinforcement Learning using Optimal Transport via Gradual Domain Adaptation
Oct 18, 2022

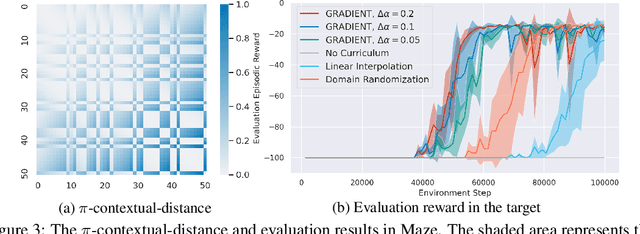
Curriculum Reinforcement Learning (CRL) aims to create a sequence of tasks, starting from easy ones and gradually learning towards difficult tasks. In this work, we focus on the idea of framing CRL as interpolations between a source (auxiliary) and a target task distribution. Although existing studies have shown the great potential of this idea, it remains unclear how to formally quantify and generate the movement between task distributions. Inspired by the insights from gradual domain adaptation in semi-supervised learning, we create a natural curriculum by breaking down the potentially large task distributional shift in CRL into smaller shifts. We propose GRADIENT, which formulates CRL as an optimal transport problem with a tailored distance metric between tasks. Specifically, we generate a sequence of task distributions as a geodesic interpolation (i.e., Wasserstein barycenter) between the source and target distributions. Different from many existing methods, our algorithm considers a task-dependent contextual distance metric and is capable of handling nonparametric distributions in both continuous and discrete context settings. In addition, we theoretically show that GRADIENT enables smooth transfer between subsequent stages in the curriculum under certain conditions. We conduct extensive experiments in locomotion and manipulation tasks and show that our proposed GRADIENT achieves higher performance than baselines in terms of learning efficiency and asymptotic performance.