 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow4R: Unifying 4D Reconstruction and Tracking with Scene Flow
Feb 15, 2026Reconstructing and tracking dynamic 3D scenes remains a fundamental challenge in computer vision. Existing approaches often decouple geometry from motion: multi-view reconstruction methods assume static scenes, while dynamic tracking frameworks rely on explicit camera pose estimation or separate motion models. We propose Flow4R, a unified framework that treats camera-space scene flow as the central representation linking 3D structure, object motion, and camera motion. Flow4R predicts a minimal per-pixel property set-3D point position, scene flow, pose weight, and confidence-from two-view inputs using a Vision Transformer. This flow-centric formulation allows local geometry and bidirectional motion to be inferred symmetrically with a shared decoder in a single forward pass, without requiring explicit pose regressors or bundle adjustment. Trained jointly on static and dynamic datasets, Flow4R achieves state-of-the-art performance on 4D reconstruction and tracking tasks, demonstrating the effectiveness of the flow-central representation for spatiotemporal scene understanding.
DynSUP: Dynamic Gaussian Splatting from An Unposed Image Pair
Dec 01, 2024



Recent advances in 3D Gaussian Splatting have shown promising results. Existing methods typically assume static scenes and/or multiple images with prior poses. Dynamics, sparse views, and unknown poses significantly increase the problem complexity due to insufficient geometric constraints. To overcome this challenge, we propose a method that can use only two images without prior poses to fit Gaussians in dynamic environments. To achieve this, we introduce two technical contributions. First, we propose an object-level two-view bundle adjustment. This strategy decomposes dynamic scenes into piece-wise rigid components, and jointly estimates the camera pose and motions of dynamic objects. Second, we design an SE(3) field-driven Gaussian training method. It enables fine-grained motion modeling through learnable per-Gaussian transformations. Our method leads to high-fidelity novel view synthesis of dynamic scenes while accurately preserving temporal consistency and object motion. Experiments on both synthetic and real-world datasets demonstrate that our method significantly outperforms state-of-the-art approaches designed for the cases of static environments, multiple images, and/or known poses. Our project page is available at https://colin-de.github.io/DynSUP/.
GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians
Dec 04, 2023



We introduce GaussianAvatars, a new method to create photorealistic head avatars that are fully controllable in terms of expression, pose, and viewpoint. The core idea is a dynamic 3D representation based on 3D Gaussian splats that are rigged to a parametric morphable face model. This combination facilitates photorealistic rendering while allowing for precise animation control via the underlying parametric model, e.g., through expression transfer from a driving sequence or by manually changing the morphable model parameters. We parameterize each splat by a local coordinate frame of a triangle and optimize for explicit displacement offset to obtain a more accurate geometric representation. During avatar reconstruction, we jointly optimize for the morphable model parameters and Gaussian splat parameters in an end-to-end fashion. We demonstrate the animation capabilities of our photorealistic avatar in several challenging scenarios. For instance, we show reenactments from a driving video, where our method outperforms existing works by a significant margin.
Cloth2Body: Generating 3D Human Body Mesh from 2D Clothing
Sep 28, 2023



In this paper, we define and study a new Cloth2Body problem which has a goal of generating 3D human body meshes from a 2D clothing image. Unlike the existing human mesh recovery problem, Cloth2Body needs to address new and emerging challenges raised by the partial observation of the input and the high diversity of the output. Indeed, there are three specific challenges. First, how to locate and pose human bodies into the clothes. Second, how to effectively estimate body shapes out of various clothing types. Finally, how to generate diverse and plausible results from a 2D clothing image. To this end, we propose an end-to-end framework that can accurately estimate 3D body mesh parameterized by pose and shape from a 2D clothing image. Along this line, we first utilize Kinematics-aware Pose Estimation to estimate body pose parameters. 3D skeleton is employed as a proxy followed by an inverse kinematics module to boost the estimation accuracy. We additionally design an adaptive depth trick to align the re-projected 3D mesh better with 2D clothing image by disentangling the effects of object size and camera extrinsic. Next, we propose Physics-informed Shape Estimation to estimate body shape parameters. 3D shape parameters are predicted based on partial body measurements estimated from RGB image, which not only improves pixel-wise human-cloth alignment, but also enables flexible user editing. Finally, we design Evolution-based pose generation method, a skeleton transplanting method inspired by genetic algorithms to generate diverse reasonable poses during inference. As shown by experimental results on both synthetic and real-world data, the proposed framework achieves state-of-the-art performance and can effectively recover natural and diverse 3D body meshes from 2D images that align well with clothing.
Revisiting Event-based Video Frame Interpolation
Jul 24, 2023



Dynamic vision sensors or event cameras provide rich complementary information for video frame interpolation. Existing state-of-the-art methods follow the paradigm of combining both synthesis-based and warping networks. However, few of those methods fully respect the intrinsic characteristics of events streams. Given that event cameras only encode intensity changes and polarity rather than color intensities, estimating optical flow from events is arguably more difficult than from RGB information. We therefore propose to incorporate RGB information in an event-guided optical flow refinement strategy. Moreover, in light of the quasi-continuous nature of the time signals provided by event cameras, we propose a divide-and-conquer strategy in which event-based intermediate frame synthesis happens incrementally in multiple simplified stages rather than in a single, long stage. Extensive experiments on both synthetic and real-world datasets show that these modifications lead to more reliable and realistic intermediate frame results than previous video frame interpolation methods. Our findings underline that a careful consideration of event characteristics such as high temporal density and elevated noise benefits interpolation accuracy.
NeRSemble: Multi-view Radiance Field Reconstruction of Human Heads
May 04, 2023



We focus on reconstructing high-fidelity radiance fields of human heads, capturing their animations over time, and synthesizing re-renderings from novel viewpoints at arbitrary time steps. To this end, we propose a new multi-view capture setup composed of 16 calibrated machine vision cameras that record time-synchronized images at 7.1 MP resolution and 73 frames per second. With our setup, we collect a new dataset of over 4700 high-resolution, high-framerate sequences of more than 220 human heads, from which we introduce a new human head reconstruction benchmark. The recorded sequences cover a wide range of facial dynamics, including head motions, natural expressions, emotions, and spoken language. In order to reconstruct high-fidelity human heads, we propose Dynamic Neural Radiance Fields using Hash Ensembles (NeRSemble). We represent scene dynamics by combining a deformation field and an ensemble of 3D multi-resolution hash encodings. The deformation field allows for precise modeling of simple scene movements, while the ensemble of hash encodings helps to represent complex dynamics. As a result, we obtain radiance field representations of human heads that capture motion over time and facilitate re-rendering of arbitrary novel viewpoints. In a series of experiments, we explore the design choices of our method and demonstrate that our approach outperforms state-of-the-art dynamic radiance field approaches by a significant margin.
Dual-Space NeRF: Learning Animatable Avatars and Scene Lighting in Separate Spaces
Aug 31, 2022
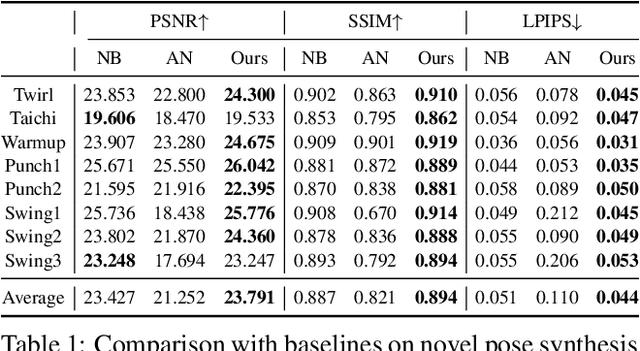
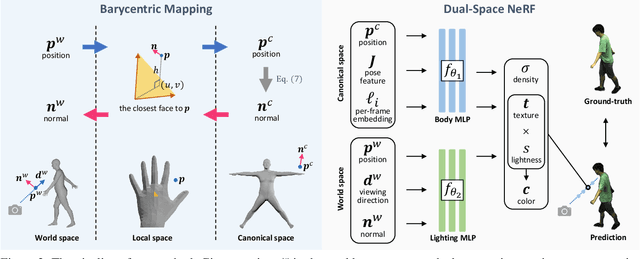
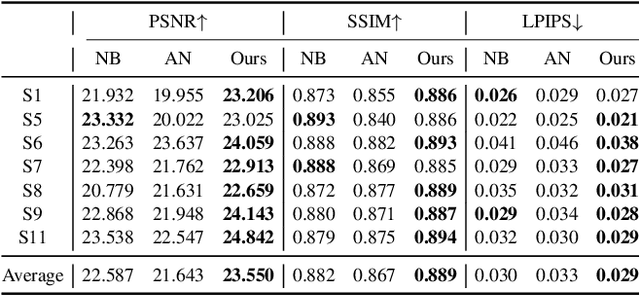
Modeling the human body in a canonical space is a common practice for capturing and animation. But when involving the neural radiance field (NeRF), learning a static NeRF in the canonical space is not enough because the lighting of the body changes when the person moves even though the scene lighting is constant. Previous methods alleviate the inconsistency of lighting by learning a per-frame embedding, but this operation does not generalize to unseen poses. Given that the lighting condition is static in the world space while the human body is consistent in the canonical space, we propose a dual-space NeRF that models the scene lighting and the human body with two MLPs in two separate spaces. To bridge these two spaces, previous methods mostly rely on the linear blend skinning (LBS) algorithm. However, the blending weights for LBS of a dynamic neural field are intractable and thus are usually memorized with another MLP, which does not generalize to novel poses. Although it is possible to borrow the blending weights of a parametric mesh such as SMPL, the interpolation operation introduces more artifacts. In this paper, we propose to use the barycentric mapping, which can directly generalize to unseen poses and surprisingly achieves superior results than LBS with neural blending weights. Quantitative and qualitative results on the Human3.6M and the ZJU-MoCap datasets show the effectiveness of our method.
UNIF: United Neural Implicit Functions for Clothed Human Reconstruction and Animation
Jul 20, 2022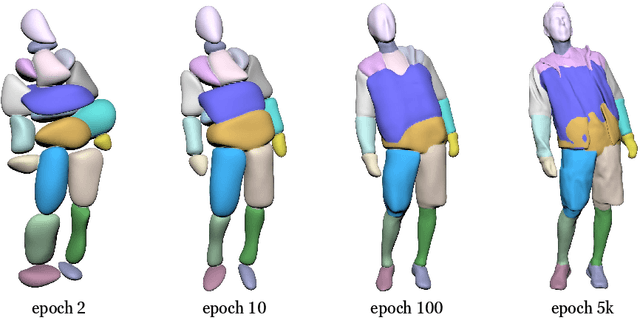
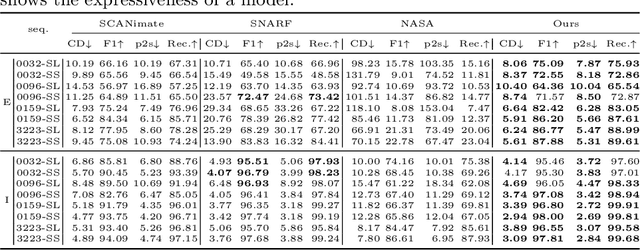
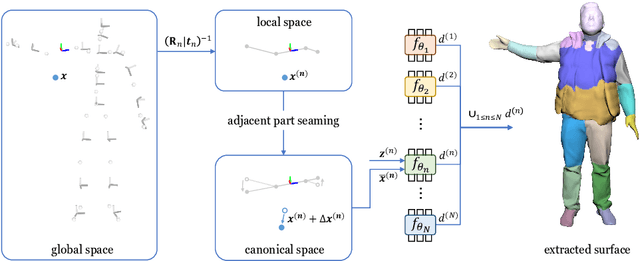
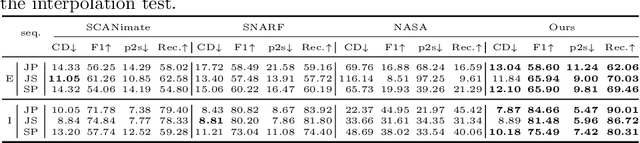
We propose united implicit functions (UNIF), a part-based method for clothed human reconstruction and animation with raw scans and skeletons as the input. Previous part-based methods for human reconstruction rely on ground-truth part labels from SMPL and thus are limited to minimal-clothed humans. In contrast, our method learns to separate parts from body motions instead of part supervision, thus can be extended to clothed humans and other articulated objects. Our Partition-from-Motion is achieved by a bone-centered initialization, a bone limit loss, and a section normal loss that ensure stable part division even when the training poses are limited. We also present a minimal perimeter loss for SDF to suppress extra surfaces and part overlapping. Another core of our method is an adjacent part seaming algorithm that produces non-rigid deformations to maintain the connection between parts which significantly relieves the part-based artifacts. Under this algorithm, we further propose "Competing Parts", a method that defines blending weights by the relative position of a point to bones instead of the absolute position, avoiding the generalization problem of neural implicit functions with inverse LBS (linear blend skinning). We demonstrate the effectiveness of our method by clothed human body reconstruction and animation on the CAPE and the ClothSeq datasets.
Speech Drives Templates: Co-Speech Gesture Synthesis with Learned Templates
Aug 18, 2021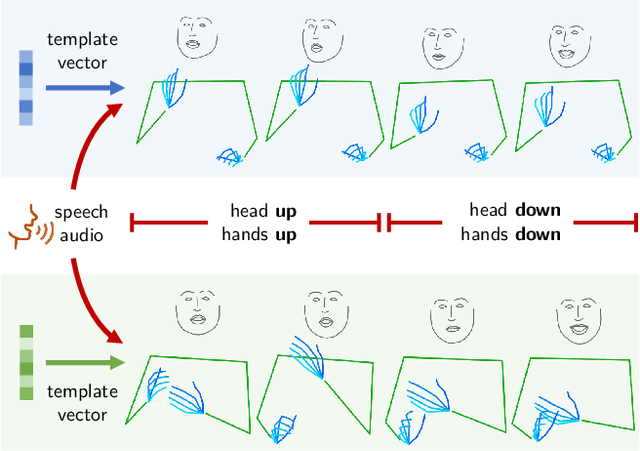
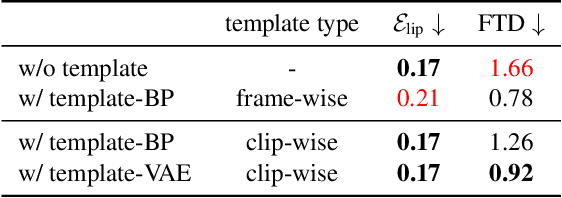
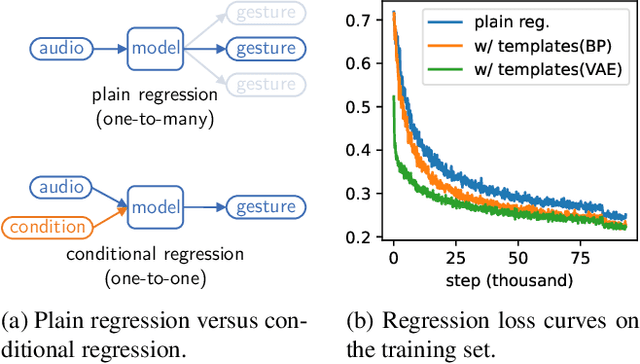

Co-speech gesture generation is to synthesize a gesture sequence that not only looks real but also matches with the input speech audio. Our method generates the movements of a complete upper body, including arms, hands, and the head. Although recent data-driven methods achieve great success, challenges still exist, such as limited variety, poor fidelity, and lack of objective metrics. Motivated by the fact that the speech cannot fully determine the gesture, we design a method that learns a set of gesture template vectors to model the latent conditions, which relieve the ambiguity. For our method, the template vector determines the general appearance of a generated gesture sequence, while the speech audio drives subtle movements of the body, both indispensable for synthesizing a realistic gesture sequence. Due to the intractability of an objective metric for gesture-speech synchronization, we adopt the lip-sync error as a proxy metric to tune and evaluate the synchronization ability of our model. Extensive experiments show the superiority of our method in both objective and subjective evaluations on fidelity and synchronization.
Learning to Recommend Frame for Interactive Video Object Segmentation in the Wild
Mar 18, 2021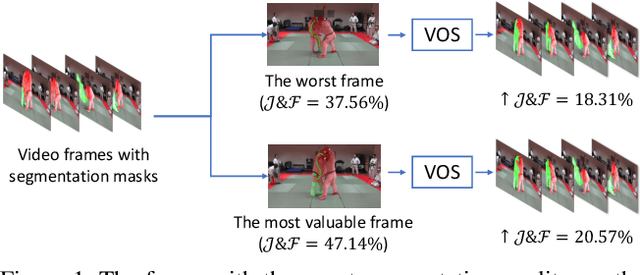
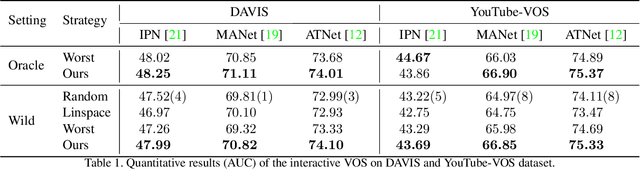
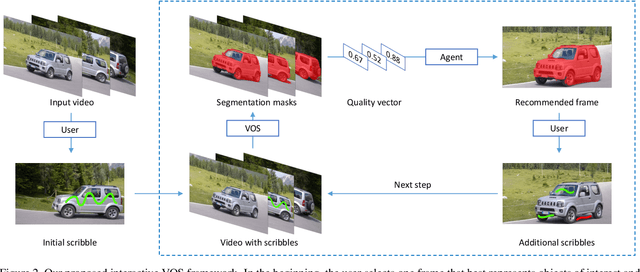
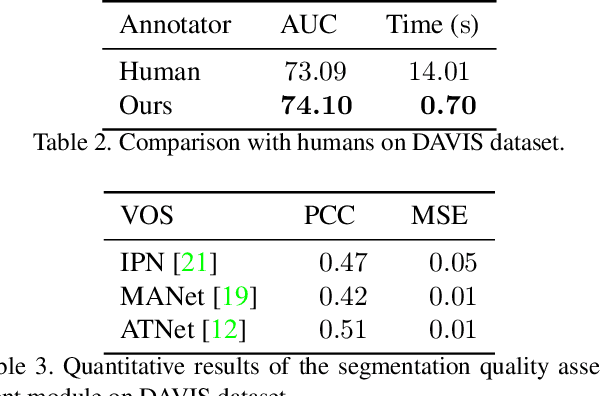
This paper proposes a framework for the interactive video object segmentation (VOS) in the wild where users can choose some frames for annotations iteratively. Then, based on the user annotations, a segmentation algorithm refines the masks. The previous interactive VOS paradigm selects the frame with some worst evaluation metric, and the ground truth is required for calculating the evaluation metric, which is impractical in the testing phase. In contrast, in this paper, we advocate that the frame with the worst evaluation metric may not be exactly the most valuable frame that leads to the most performance improvement across the video. Thus, we formulate the frame selection problem in the interactive VOS as a Markov Decision Process, where an agent is learned to recommend the frame under a deep reinforcement learning framework. The learned agent can automatically determine the most valuable frame, making the interactive setting more practical in the wild. Experimental results on the public datasets show the effectiveness of our learned agent without any changes to the underlying VOS algorithms. Our data, code, and models are available at https://github.com/svip-lab/IVOS-W.