 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularized Deep Signed Distance Fields for Reactive Motion Generation
Mar 09, 2022
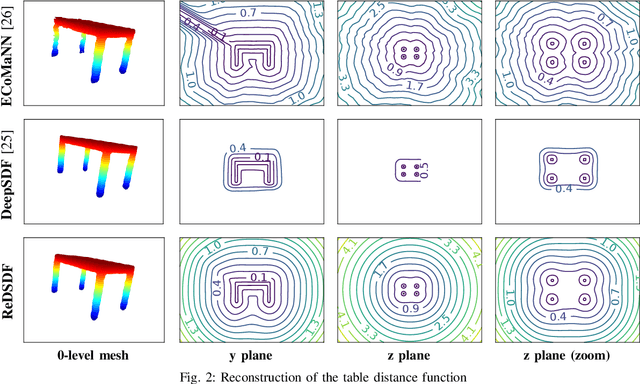
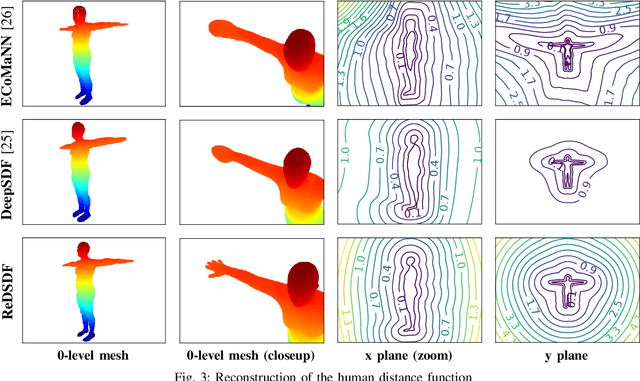
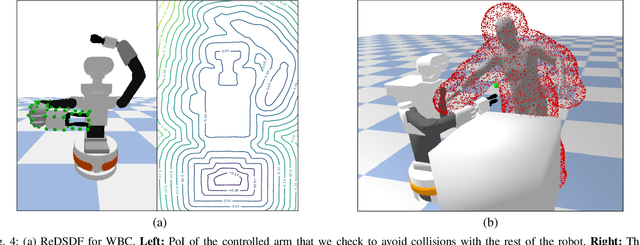
Autonomous robots should operate in real-world dynamic environments and collaborate with humans in tight spaces. A key component for allowing robots to leave structured lab and manufacturing settings is their ability to evaluate online and real-time collisions with the world around them. Distance-based constraints are fundamental for enabling robots to plan their actions and act safely, protecting both humans and their hardware. However, different applications require different distance resolutions, leading to various heuristic approaches for measuring distance fields w.r.t. obstacles, which are computationally expensive and hinder their application in dynamic obstacle avoidance use-cases. We propose Regularized Deep Signed Distance Fields (ReDSDF), a single neural implicit function that can compute smooth distance fields at any scale, with fine-grained resolution over high-dimensional manifolds and articulated bodies like humans, thanks to our effective data generation and a simple inductive bias during training. We demonstrate the effectiveness of our approach in representative simulated tasks for whole-body control (WBC) and safe Human-Robot Interaction (HRI) in shared workspaces. Finally, we provide proof of concept of a real-world application in a HRI handover task with a mobile manipulator robot.
Graph-based Reinforcement Learning meets Mixed Integer Programs: An application to 3D robot assembly discovery
Mar 08, 2022
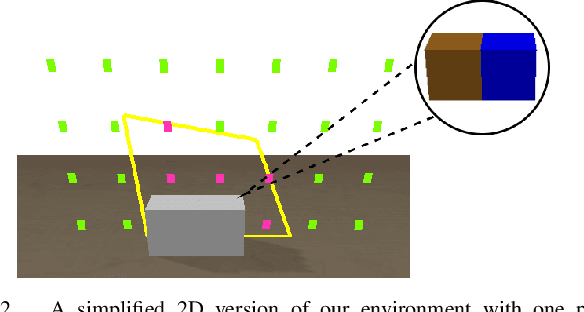

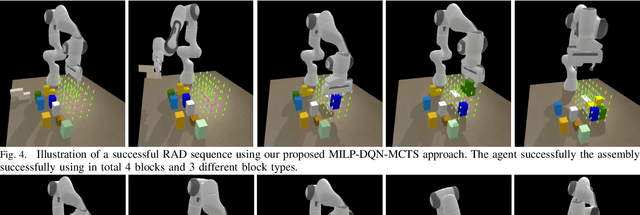
Robot assembly discovery is a challenging problem that lives at the intersection of resource allocation and motion planning. The goal is to combine a predefined set of objects to form something new while considering task execution with the robot-in-the-loop. In this work, we tackle the problem of building arbitrary, predefined target structures entirely from scratch using a set of Tetris-like building blocks and a robotic manipulator. Our novel hierarchical approach aims at efficiently decomposing the overall task into three feasible levels that benefit mutually from each other. On the high level, we run a classical mixed-integer program for global optimization of block-type selection and the blocks' final poses to recreate the desired shape. Its output is then exploited to efficiently guide the exploration of an underlying reinforcement learning (RL) policy. This RL policy draws its generalization properties from a flexible graph-based representation that is learned through Q-learning and can be refined with search. Moreover, it accounts for the necessary conditions of structural stability and robotic feasibility that cannot be effectively reflected in the previous layer. Lastly, a grasp and motion planner transforms the desired assembly commands into robot joint movements. We demonstrate the performance of the proposed method on a set of competitive simulated robot assembly discovery environments and report performance and robustness gains compared to an unstructured end-to-end approach. Videos are available at https://sites.google.com/view/rl-meets-milp .
Robot Learning of Mobile Manipulation with Reachability Behavior Priors
Mar 08, 2022
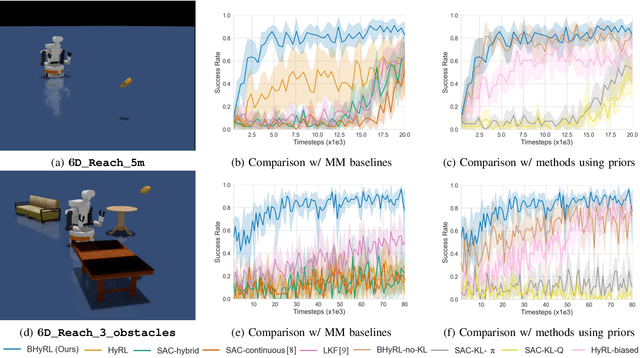

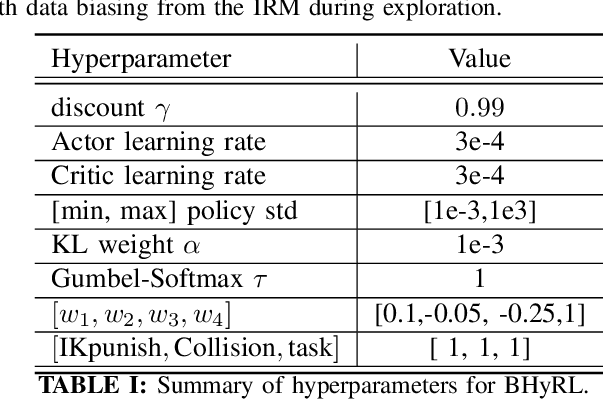
Mobile Manipulation (MM) systems are ideal candidates for taking up the role of a personal assistant in unstructured real-world environments. Among other challenges, MM requires effective coordination of the robot's embodiments for executing tasks that require both mobility and manipulation. Reinforcement Learning (RL) holds the promise of endowing robots with adaptive behaviors, but most methods require prohibitively large amounts of data for learning a useful control policy. In this work, we study the integration of robotic reachability priors in actor-critic RL methods for accelerating the learning of MM for reaching and fetching tasks. Namely, we consider the problem of optimal base placement and the subsequent decision of whether to activate the arm for reaching a 6D target. For this, we devise a novel Hybrid RL method that handles discrete and continuous actions jointly, resorting to the Gumbel-Softmax reparameterization. Next, we train a reachability prior using data from the operational robot workspace, inspired by classical methods. Subsequently, we derive Boosted Hybrid RL (BHyRL), a novel algorithm for learning Q-functions by modeling them as a sum of residual approximators. Every time a new task needs to be learned, we can transfer our learned residuals and learn the component of the Q-function that is task-specific, hence, maintaining the task structure from prior behaviors. Moreover, we find that regularizing the target policy with a prior policy yields more expressive behaviors. We evaluate our method in simulation in reaching and fetching tasks of increasing difficulty, and we show the superior performance of BHyRL against baseline methods. Finally, we zero-transfer our learned 6D fetching policy with BHyRL to our MM robot TIAGo++. For more details and code release, please refer to our project site: irosalab.com/rlmmbp
A Hierarchical Approach to Active Pose Estimation
Mar 08, 2022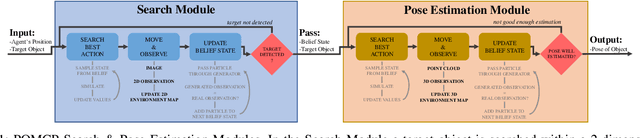
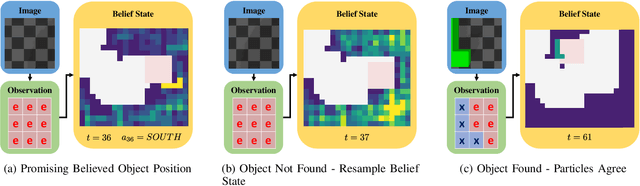
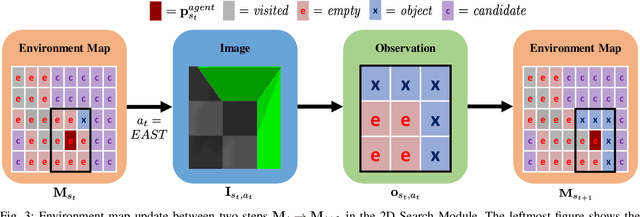
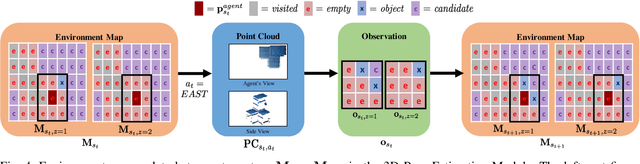
Creating mobile robots which are able to find and manipulate objects in large environments is an active topic of research. These robots not only need to be capable of searching for specific objects but also to estimate their poses often relying on environment observations, which is even more difficult in the presence of occlusions. Therefore, to tackle this problem we propose a simple hierarchical approach to estimate the pose of a desired object. An Active Visual Search module operating with RGB images first obtains a rough estimation of the object 2D pose, followed by a more computationally expensive Active Pose Estimation module using point cloud data. We empirically show that processing image features to obtain a richer observation speeds up the search and pose estimation computations, in comparison to a binary decision that indicates whether the object is or not in the current image.
Residual Robot Learning for Object-Centric Probabilistic Movement Primitives
Mar 08, 2022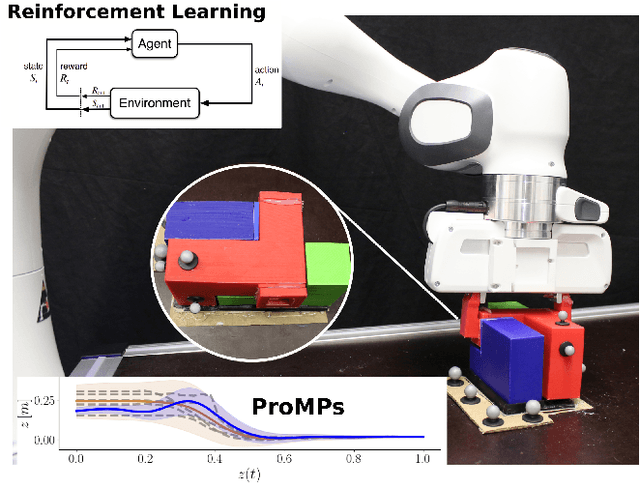
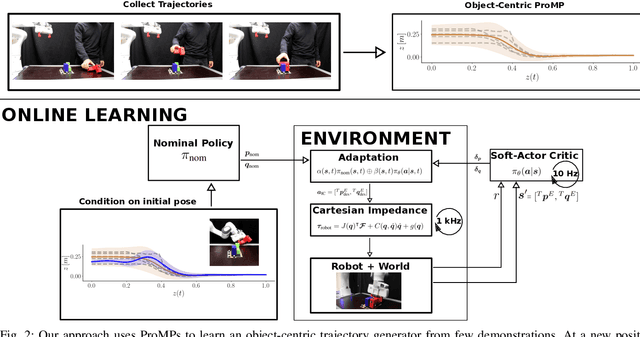
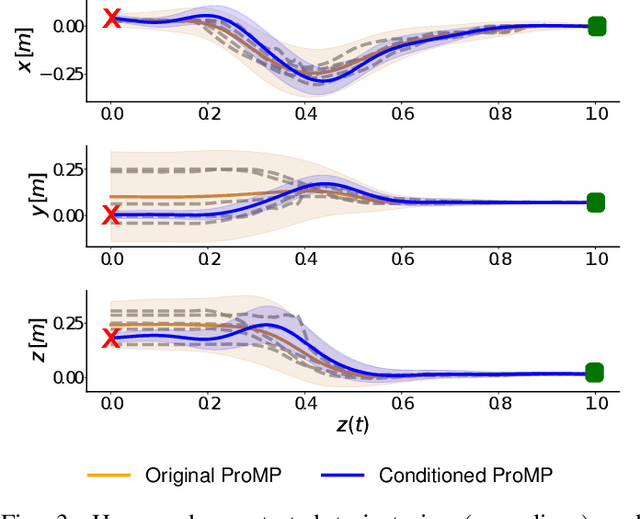

It is desirable for future robots to quickly learn new tasks and adapt learned skills to constantly changing environments. To this end, Probabilistic Movement Primitives (ProMPs) have shown to be a promising framework to learn generalizable trajectory generators from distributions over demonstrated trajectories. However, in practical applications that require high precision in the manipulation of objects, the accuracy of ProMPs is often insufficient, in particular when they are learned in cartesian space from external observations and executed with limited controller gains. Therefore, we propose to combine ProMPs with recently introduced Residual Reinforcement Learning (RRL), to account for both, corrections in position and orientation during task execution. In particular, we learn a residual on top of a nominal ProMP trajectory with Soft-Actor Critic and incorporate the variability in the demonstrations as a decision variable to reduce the search space for RRL. As a proof of concept, we evaluate our proposed method on a 3D block insertion task with a 7-DoF Franka Emika Panda robot. Experimental results show that the robot successfully learns to complete the insertion which was not possible before with using basic ProMPs.
An Analysis of Measure-Valued Derivatives for Policy Gradients
Mar 08, 2022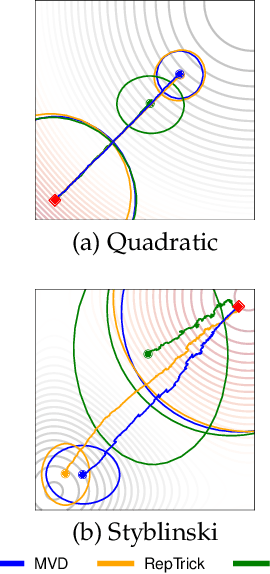
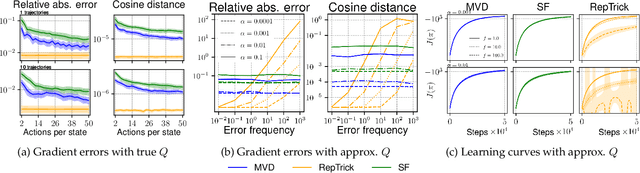
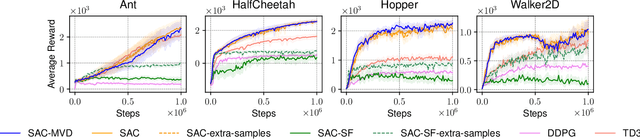
Reinforcement learning methods for robotics are increasingly successful due to the constant development of better policy gradient techniques. A precise (low variance) and accurate (low bias) gradient estimator is crucial to face increasingly complex tasks. Traditional policy gradient algorithms use the likelihood-ratio trick, which is known to produce unbiased but high variance estimates. More modern approaches exploit the reparametrization trick, which gives lower variance gradient estimates but requires differentiable value function approximators. In this work, we study a different type of stochastic gradient estimator - the Measure-Valued Derivative. This estimator is unbiased, has low variance, and can be used with differentiable and non-differentiable function approximators. We empirically evaluate this estimator in the actor-critic policy gradient setting and show that it can reach comparable performance with methods based on the likelihood-ratio or reparametrization tricks, both in low and high-dimensional action spaces. With this work, we want to show that the Measure-Valued Derivative estimator can be a useful alternative to other policy gradient estimators.
PAC-Bayesian Lifelong Learning For Multi-Armed Bandits
Mar 07, 2022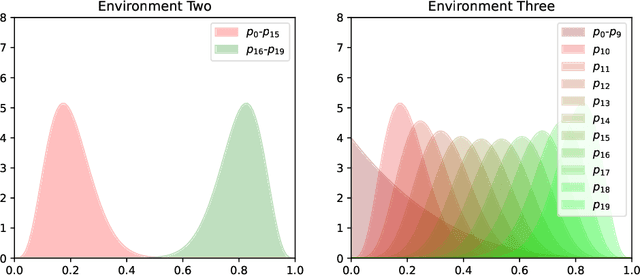
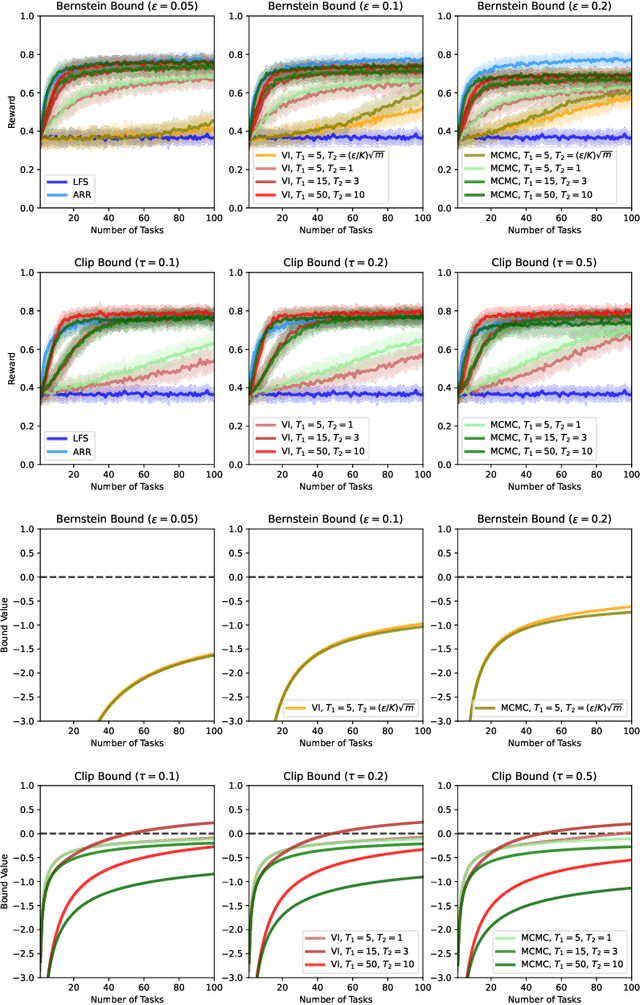
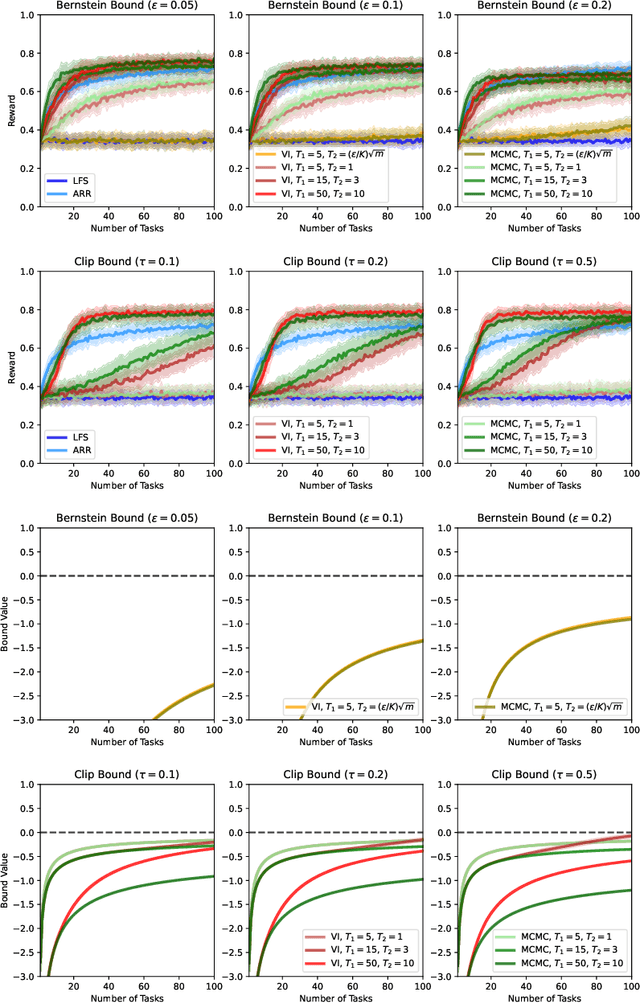
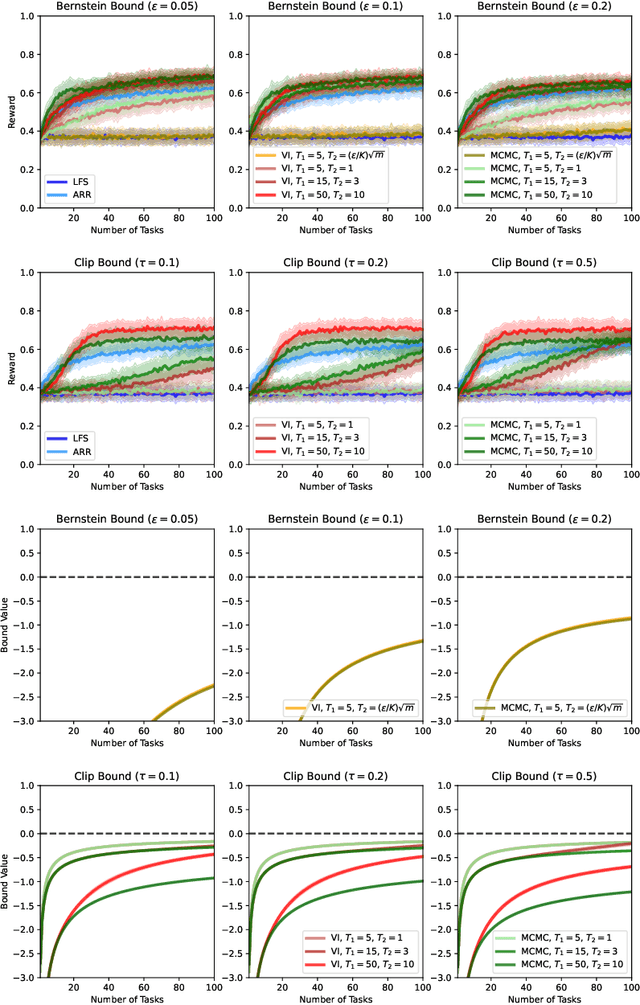
We present a PAC-Bayesian analysis of lifelong learning. In the lifelong learning problem, a sequence of learning tasks is observed one-at-a-time, and the goal is to transfer information acquired from previous tasks to new learning tasks. We consider the case when each learning task is a multi-armed bandit problem. We derive lower bounds on the expected average reward that would be obtained if a given multi-armed bandit algorithm was run in a new task with a particular prior and for a set number of steps. We propose lifelong learning algorithms that use our new bounds as learning objectives. Our proposed algorithms are evaluated in several lifelong multi-armed bandit problems and are found to perform better than a baseline method that does not use generalisation bounds.
* 29 pages, 5 figures
An Adaptive Human Driver Model for Realistic Race Car Simulations
Mar 03, 2022
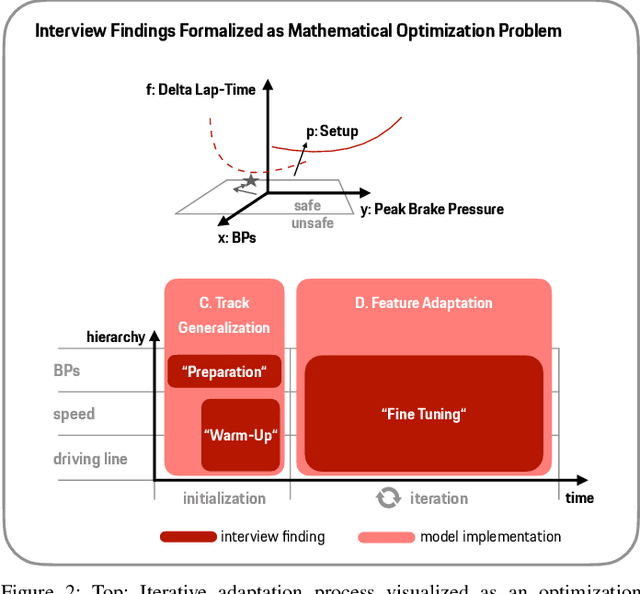
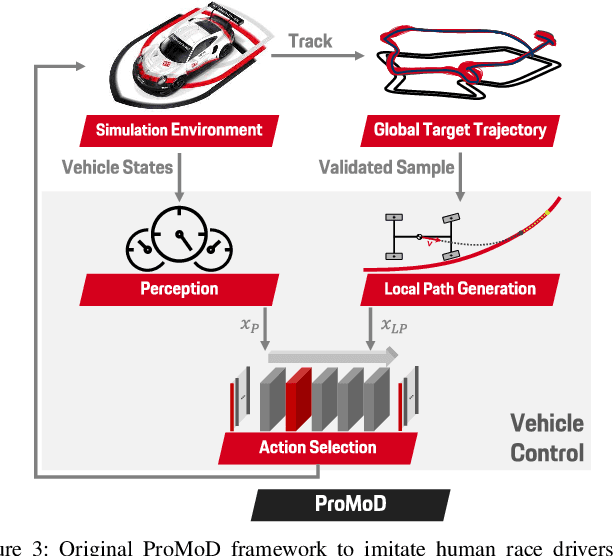
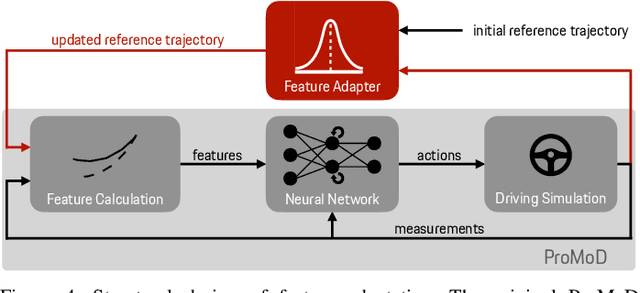
Engineering a high-performance race car requires a direct consideration of the human driver using real-world tests or Human-Driver-in-the-Loop simulations. Apart from that, offline simulations with human-like race driver models could make this vehicle development process more effective and efficient but are hard to obtain due to various challenges. With this work, we intend to provide a better understanding of race driver behavior and introduce an adaptive human race driver model based on imitation learning. Using existing findings and an interview with a professional race engineer, we identify fundamental adaptation mechanisms and how drivers learn to optimize lap time on a new track. Subsequently, we use these insights to develop generalization and adaptation techniques for a recently presented probabilistic driver modeling approach and evaluate it using data from professional race drivers and a state-of-the-art race car simulator. We show that our framework can create realistic driving line distributions on unseen race tracks with almost human-like performance. Moreover, our driver model optimizes its driving lap by lap, correcting driving errors from previous laps while achieving faster lap times. This work contributes to a better understanding and modeling of the human driver, aiming to expedite simulation methods in the modern vehicle development process and potentially supporting automated driving and racing technologies.
Integrating Contrastive Learning with Dynamic Models for Reinforcement Learning from Images
Mar 02, 2022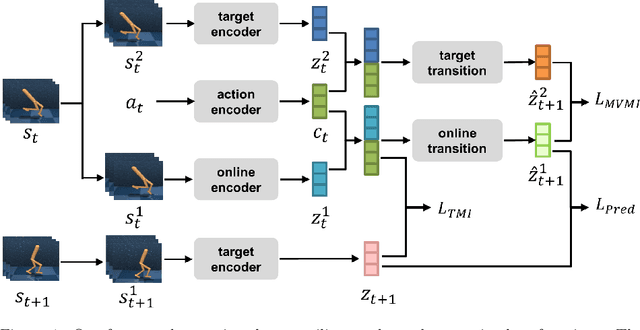

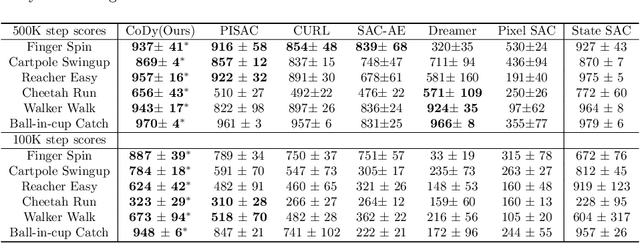
Recent methods for reinforcement learning from images use auxiliary tasks to learn image features that are used by the agent's policy or Q-function. In particular, methods based on contrastive learning that induce linearity of the latent dynamics or invariance to data augmentation have been shown to greatly improve the sample efficiency of the reinforcement learning algorithm and the generalizability of the learned embedding. We further argue, that explicitly improving Markovianity of the learned embedding is desirable and propose a self-supervised representation learning method which integrates contrastive learning with dynamic models to synergistically combine these three objectives: (1) We maximize the InfoNCE bound on the mutual information between the state- and action-embedding and the embedding of the next state to induce a linearly predictive embedding without explicitly learning a linear transition model, (2) we further improve Markovianity of the learned embedding by explicitly learning a non-linear transition model using regression, and (3) we maximize the mutual information between the two nonlinear predictions of the next embeddings based on the current action and two independent augmentations of the current state, which naturally induces transformation invariance not only for the state embedding, but also for the nonlinear transition model. Experimental evaluation on the Deepmind control suite shows that our proposed method achieves higher sample efficiency and better generalization than state-of-art methods based on contrastive learning or reconstruction.
* 28 pages, 11 figures, 5 tables
A Unified Perspective on Value Backup and Exploration in Monte-Carlo Tree Search
Feb 11, 2022



Monte-Carlo Tree Search (MCTS) is a class of methods for solving complex decision-making problems through the synergy of Monte-Carlo planning and Reinforcement Learning (RL). The highly combinatorial nature of the problems commonly addressed by MCTS requires the use of efficient exploration strategies for navigating the planning tree and quickly convergent value backup methods. These crucial problems are particularly evident in recent advances that combine MCTS with deep neural networks for function approximation. In this work, we propose two methods for improving the convergence rate and exploration based on a newly introduced backup operator and entropy regularization. We provide strong theoretical guarantees to bound convergence rate, approximation error, and regret of our methods. Moreover, we introduce a mathematical framework based on the use of the $\alpha$-divergence for backup and exploration in MCTS. We show that this theoretical formulation unifies different approaches, including our newly introduced ones, under the same mathematical framework, allowing to obtain different methods by simply changing the value of $\alpha$. In practice, our unified perspective offers a flexible way to balance between exploration and exploitation by tuning the single $\alpha$ parameter according to the problem at hand. We validate our methods through a rigorous empirical study from basic toy problems to the complex Atari games, and including both MDP and POMDP problems.