 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Efficient Long Video Understanding for Multimodal LLMs
Mar 06, 2025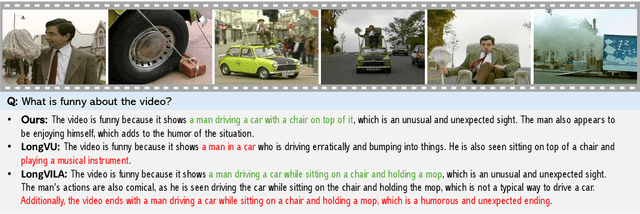
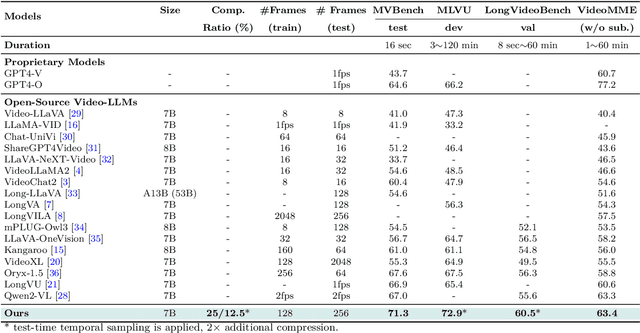
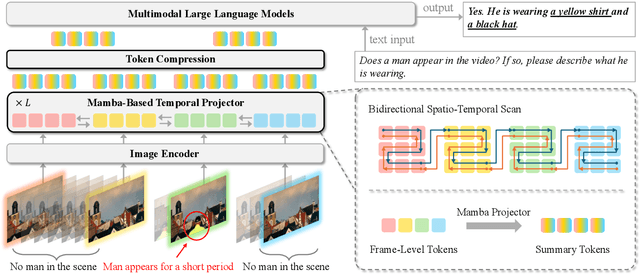
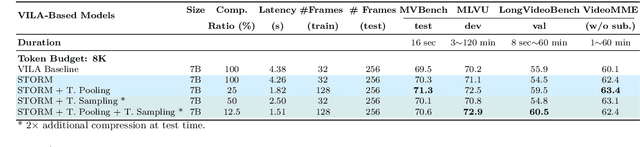
Recent advances in video-based multimodal large language models (Video-LLMs) have significantly improved video understanding by processing videos as sequences of image frames. However, many existing methods treat frames independently in the vision backbone, lacking explicit temporal modeling, which limits their ability to capture dynamic patterns and efficiently handle long videos. To address these limitations, we introduce STORM (\textbf{S}patiotemporal \textbf{TO}ken \textbf{R}eduction for \textbf{M}ultimodal LLMs), a novel architecture incorporating a dedicated temporal encoder between the image encoder and the LLM. Our temporal encoder leverages the Mamba State Space Model to integrate temporal information into image tokens, generating enriched representations that preserve inter-frame dynamics across the entire video sequence. This enriched encoding not only enhances video reasoning capabilities but also enables effective token reduction strategies, including test-time sampling and training-based temporal and spatial pooling, substantially reducing computational demands on the LLM without sacrificing key temporal information. By integrating these techniques, our approach simultaneously reduces training and inference latency while improving performance, enabling efficient and robust video understanding over extended temporal contexts. Extensive evaluations show that STORM achieves state-of-the-art results across various long video understanding benchmarks (more than 5\% improvement on MLVU and LongVideoBench) while reducing the computation costs by up to $8\times$ and the decoding latency by 2.4-2.9$\times$ for the fixed numbers of input frames. Project page is available at https://research.nvidia.com/labs/lpr/storm
FeatSharp: Your Vision Model Features, Sharper
Feb 22, 2025The feature maps of vision encoders are fundamental to myriad modern AI tasks, ranging from core perception algorithms (e.g. semantic segmentation, object detection, depth perception, etc.) to modern multimodal understanding in vision-language models (VLMs). Currently, in computer vision, the frontier of general purpose vision backbones are Vision Transformers (ViT), typically trained using contrastive loss (e.g. CLIP). A key problem with most off-the-shelf ViTs, particularly CLIP, is that these models are inflexibly low resolution. Most run at 224x224px, while the "high resolution" versions are around 378-448px, but still inflexible. We introduce a novel method to coherently and cheaply upsample the feature maps of low-res vision encoders while picking up on fine-grained details that would otherwise be lost due to resolution. We demonstrate the effectiveness of this approach on core perception tasks as well as within agglomerative model (RADIO) training as a way of providing richer targets for distillation.
QLIP: Text-Aligned Visual Tokenization Unifies Auto-Regressive Multimodal Understanding and Generation
Feb 07, 2025We introduce Quantized Language-Image Pretraining (QLIP), a visual tokenization method that combines state-of-the-art reconstruction quality with state-of-the-art zero-shot image understanding. QLIP trains a binary-spherical-quantization-based autoencoder with reconstruction and language-image alignment objectives. We are the first to show that the two objectives do not need to be at odds. We balance the two loss terms dynamically during training and show that a two-stage training pipeline effectively mixes the large-batch requirements of image-language pre-training with the memory bottleneck imposed by the reconstruction objective. We validate the effectiveness of QLIP for multimodal understanding and text-conditioned image generation with a single model. Specifically, QLIP serves as a drop-in replacement for the visual encoder for LLaVA and the image tokenizer for LlamaGen with comparable or even better performance. Finally, we demonstrate that QLIP enables a unified mixed-modality auto-regressive model for understanding and generation.
Factorized Implicit Global Convolution for Automotive Computational Fluid Dynamics Prediction
Feb 06, 2025Computational Fluid Dynamics (CFD) is crucial for automotive design, requiring the analysis of large 3D point clouds to study how vehicle geometry affects pressure fields and drag forces. However, existing deep learning approaches for CFD struggle with the computational complexity of processing high-resolution 3D data. We propose Factorized Implicit Global Convolution (FIGConv), a novel architecture that efficiently solves CFD problems for very large 3D meshes with arbitrary input and output geometries. FIGConv achieves quadratic complexity $O(N^2)$, a significant improvement over existing 3D neural CFD models that require cubic complexity $O(N^3)$. Our approach combines Factorized Implicit Grids to approximate high-resolution domains, efficient global convolutions through 2D reparameterization, and a U-shaped architecture for effective information gathering and integration. We validate our approach on the industry-standard Ahmed body dataset and the large-scale DrivAerNet dataset. In DrivAerNet, our model achieves an $R^2$ value of 0.95 for drag prediction, outperforming the previous state-of-the-art by a significant margin. This represents a 40% improvement in relative mean squared error and a 70% improvement in absolute mean squared error over previous methods.
Mosaic3D: Foundation Dataset and Model for Open-Vocabulary 3D Segmentation
Feb 04, 2025



We tackle open-vocabulary 3D scene understanding by introducing a novel data generation pipeline and training framework. Our method addresses three critical requirements for effective training: precise 3D region segmentation, comprehensive textual descriptions, and sufficient dataset scale. By leveraging state-of-the-art open-vocabulary image segmentation models and region-aware Vision-Language Models, we develop an automatic pipeline that generates high-quality 3D mask-text pairs. Applying this pipeline to multiple 3D scene datasets, we create Mosaic3D-5.6M, a dataset of over 30K annotated scenes with 5.6M mask-text pairs, significantly larger than existing datasets. Building upon this data, we propose Mosaic3D, a foundation model combining a 3D encoder trained with contrastive learning and a lightweight mask decoder for open-vocabulary 3D semantic and instance segmentation. Our approach achieves state-of-the-art results on open-vocabulary 3D semantic and instance segmentation tasks including ScanNet200, Matterport3D, and ScanNet++, with ablation studies validating the effectiveness of our large-scale training data.
Parallel Sequence Modeling via Generalized Spatial Propagation Network
Jan 21, 2025



We present the Generalized Spatial Propagation Network (GSPN), a new attention mechanism optimized for vision tasks that inherently captures 2D spatial structures. Existing attention models, including transformers, linear attention, and state-space models like Mamba, process multi-dimensional data as 1D sequences, compromising spatial coherence and efficiency. GSPN overcomes these limitations by directly operating on spatially coherent image data and forming dense pairwise connections through a line-scan approach. Central to GSPN is the Stability-Context Condition, which ensures stable, context-aware propagation across 2D sequences and reduces the effective sequence length to $\sqrt{N}$ for a square map with N elements, significantly enhancing computational efficiency. With learnable, input-dependent weights and no reliance on positional embeddings, GSPN achieves superior spatial fidelity and state-of-the-art performance in vision tasks, including ImageNet classification, class-guided image generation, and text-to-image generation. Notably, GSPN accelerates SD-XL with softmax-attention by over $84\times$ when generating 16K images.
SimAvatar: Simulation-Ready Avatars with Layered Hair and Clothing
Dec 12, 2024We introduce SimAvatar, a framework designed to generate simulation-ready clothed 3D human avatars from a text prompt. Current text-driven human avatar generation methods either model hair, clothing, and the human body using a unified geometry or produce hair and garments that are not easily adaptable for simulation within existing simulation pipelines. The primary challenge lies in representing the hair and garment geometry in a way that allows leveraging established prior knowledge from foundational image diffusion models (e.g., Stable Diffusion) while being simulation-ready using either physics or neural simulators. To address this task, we propose a two-stage framework that combines the flexibility of 3D Gaussians with simulation-ready hair strands and garment meshes. Specifically, we first employ three text-conditioned 3D generative models to generate garment mesh, body shape and hair strands from the given text prompt. To leverage prior knowledge from foundational diffusion models, we attach 3D Gaussians to the body mesh, garment mesh, as well as hair strands and learn the avatar appearance through optimization. To drive the avatar given a pose sequence, we first apply physics simulators onto the garment meshes and hair strands. We then transfer the motion onto 3D Gaussians through carefully designed mechanisms for each body part. As a result, our synthesized avatars have vivid texture and realistic dynamic motion. To the best of our knowledge, our method is the first to produce highly realistic, fully simulation-ready 3D avatars, surpassing the capabilities of current approaches.
StreamChat: Chatting with Streaming Video
Dec 11, 2024



This paper presents StreamChat, a novel approach that enhances the interaction capabilities of Large Multimodal Models (LMMs) with streaming video content. In streaming interaction scenarios, existing methods rely solely on visual information available at the moment a question is posed, resulting in significant delays as the model remains unaware of subsequent changes in the streaming video. StreamChat addresses this limitation by innovatively updating the visual context at each decoding step, ensuring that the model utilizes up-to-date video content throughout the decoding process. Additionally, we introduce a flexible and efficient crossattention-based architecture to process dynamic streaming inputs while maintaining inference efficiency for streaming interactions. Furthermore, we construct a new dense instruction dataset to facilitate the training of streaming interaction models, complemented by a parallel 3D-RoPE mechanism that encodes the relative temporal information of visual and text tokens. Experimental results demonstrate that StreamChat achieves competitive performance on established image and video benchmarks and exhibits superior capabilities in streaming interaction scenarios compared to state-of-the-art video LMM.
RADIO Amplified: Improved Baselines for Agglomerative Vision Foundation Models
Dec 10, 2024Agglomerative models have recently emerged as a powerful approach to training vision foundation models, leveraging multi-teacher distillation from existing models such as CLIP, DINO, and SAM. This strategy enables the efficient creation of robust models, combining the strengths of individual teachers while significantly reducing computational and resource demands. In this paper, we thoroughly analyze state-of-the-art agglomerative models, identifying critical challenges including resolution mode shifts, teacher imbalance, idiosyncratic teacher artifacts, and an excessive number of output tokens. To address these issues, we propose several novel solutions: multi-resolution training, mosaic augmentation, and improved balancing of teacher loss functions. Specifically, in the context of Vision Language Models, we introduce a token compression technique to maintain high-resolution information within a fixed token count. We release our top-performing models, available in multiple scales (-B, -L, -H, and -g), alongside inference code and pretrained weights.
Gated Delta Networks: Improving Mamba2 with Delta Rule
Dec 09, 2024Linear Transformers have gained attention as efficient alternatives to standard Transformers, but their performance in retrieval and long-context tasks has been limited. To address these limitations, recent work has explored two distinct mechanisms: gating for adaptive memory control and the delta update rule for precise memory modifications. We observe that these mechanisms are complementary: gating enables rapid memory erasure while the delta rule facilitates targeted updates. Building on this insight, we introduce the gated delta rule and develop a parallel training algorithm optimized for modern hardware. Our proposed architecture, Gated DeltaNet, consistently surpasses existing models like Mamba2 and DeltaNet across multiple benchmarks, including language modeling, common-sense reasoning, in-context retrieval, length extrapolation, and long-context understanding. We further enhance performance by developing hybrid architectures that combine Gated DeltaNet layers with sliding window attention or Mamba2 layers, achieving both improved training efficiency and superior task performance.