 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat's documented in AI? Systematic Analysis of 32K AI Model Cards
Feb 07, 2024The rapid proliferation of AI models has underscored the importance of thorough documentation, as it enables users to understand, trust, and effectively utilize these models in various applications. Although developers are encouraged to produce model cards, it's not clear how much information or what information these cards contain. In this study, we conduct a comprehensive analysis of 32,111 AI model documentations on Hugging Face, a leading platform for distributing and deploying AI models. Our investigation sheds light on the prevailing model card documentation practices. Most of the AI models with substantial downloads provide model cards, though the cards have uneven informativeness. We find that sections addressing environmental impact, limitations, and evaluation exhibit the lowest filled-out rates, while the training section is the most consistently filled-out. We analyze the content of each section to characterize practitioners' priorities. Interestingly, there are substantial discussions of data, sometimes with equal or even greater emphasis than the model itself. To evaluate the impact of model cards, we conducted an intervention study by adding detailed model cards to 42 popular models which had no or sparse model cards previously. We find that adding model cards is moderately correlated with an increase weekly download rates. Our study opens up a new perspective for analyzing community norms and practices for model documentation through large-scale data science and linguistics analysis.
Selecting Large Language Model to Fine-tune via Rectified Scaling Law
Feb 04, 2024The ever-growing ecosystem of LLMs has posed a challenge in selecting the most appropriate pre-trained model to fine-tune amidst a sea of options. Given constrained resources, fine-tuning all models and making selections afterward is unrealistic. In this work, we formulate this resource-constrained selection task into predicting fine-tuning performance and illustrate its natural connection with scaling laws. Unlike pre-training, We find that the fine-tuning scaling curve includes not just the well-known "power phase" but also the previously unobserved "pre-power phase". We also explain why existing scaling laws fail to capture this phase transition phenomenon both theoretically and empirically. To address this, we introduce the concept of "pre-learned data size" into our rectified scaling law, which overcomes theoretical limitations and fits experimental results much better. By leveraging our law, we propose a novel LLM selection algorithm that selects the near-optimal model with hundreds of times less resource consumption, while other methods may provide negatively correlated selection.
How well do LLMs cite relevant medical references? An evaluation framework and analyses
Feb 03, 2024Large language models (LLMs) are currently being used to answer medical questions across a variety of clinical domains. Recent top-performing commercial LLMs, in particular, are also capable of citing sources to support their responses. In this paper, we ask: do the sources that LLMs generate actually support the claims that they make? To answer this, we propose three contributions. First, as expert medical annotations are an expensive and time-consuming bottleneck for scalable evaluation, we demonstrate that GPT-4 is highly accurate in validating source relevance, agreeing 88% of the time with a panel of medical doctors. Second, we develop an end-to-end, automated pipeline called \textit{SourceCheckup} and use it to evaluate five top-performing LLMs on a dataset of 1200 generated questions, totaling over 40K pairs of statements and sources. Interestingly, we find that between ~50% to 90% of LLM responses are not fully supported by the sources they provide. We also evaluate GPT-4 with retrieval augmented generation (RAG) and find that, even still, around 30\% of individual statements are unsupported, while nearly half of its responses are not fully supported. Third, we open-source our curated dataset of medical questions and expert annotations for future evaluations. Given the rapid pace of LLM development and the potential harms of incorrect or outdated medical information, it is crucial to also understand and quantify their capability to produce relevant, trustworthy medical references.
Stochastic Amortization: A Unified Approach to Accelerate Feature and Data Attribution
Jan 29, 2024



Many tasks in explainable machine learning, such as data valuation and feature attribution, perform expensive computation for each data point and can be intractable for large datasets. These methods require efficient approximations, and learning a network that directly predicts the desired output, which is commonly known as amortization, is a promising solution. However, training such models with exact labels is often intractable; we therefore explore training with noisy labels and find that this is inexpensive and surprisingly effective. Through theoretical analysis of the label noise and experiments with various models and datasets, we show that this approach significantly accelerates several feature attribution and data valuation methods, often yielding an order of magnitude speedup over existing approaches.
TrustLLM: Trustworthiness in Large Language Models
Jan 25, 2024



Large language models (LLMs), exemplified by ChatGPT, have gained considerable attention for their excellent natural language processing capabilities. Nonetheless, these LLMs present many challenges, particularly in the realm of trustworthiness. Therefore, ensuring the trustworthiness of LLMs emerges as an important topic. This paper introduces TrustLLM, a comprehensive study of trustworthiness in LLMs, including principles for different dimensions of trustworthiness, established benchmark, evaluation, and analysis of trustworthiness for mainstream LLMs, and discussion of open challenges and future directions. Specifically, we first propose a set of principles for trustworthy LLMs that span eight different dimensions. Based on these principles, we further establish a benchmark across six dimensions including truthfulness, safety, fairness, robustness, privacy, and machine ethics. We then present a study evaluating 16 mainstream LLMs in TrustLLM, consisting of over 30 datasets. Our findings firstly show that in general trustworthiness and utility (i.e., functional effectiveness) are positively related. Secondly, our observations reveal that proprietary LLMs generally outperform most open-source counterparts in terms of trustworthiness, raising concerns about the potential risks of widely accessible open-source LLMs. However, a few open-source LLMs come very close to proprietary ones. Thirdly, it is important to note that some LLMs may be overly calibrated towards exhibiting trustworthiness, to the extent that they compromise their utility by mistakenly treating benign prompts as harmful and consequently not responding. Finally, we emphasize the importance of ensuring transparency not only in the models themselves but also in the technologies that underpin trustworthiness. Knowing the specific trustworthy technologies that have been employed is crucial for analyzing their effectiveness.
Navigating Dataset Documentations in AI: A Large-Scale Analysis of Dataset Cards on Hugging Face
Jan 24, 2024



Advances in machine learning are closely tied to the creation of datasets. While data documentation is widely recognized as essential to the reliability, reproducibility, and transparency of ML, we lack a systematic empirical understanding of current dataset documentation practices. To shed light on this question, here we take Hugging Face -- one of the largest platforms for sharing and collaborating on ML models and datasets -- as a prominent case study. By analyzing all 7,433 dataset documentation on Hugging Face, our investigation provides an overview of the Hugging Face dataset ecosystem and insights into dataset documentation practices, yielding 5 main findings: (1) The dataset card completion rate shows marked heterogeneity correlated with dataset popularity. (2) A granular examination of each section within the dataset card reveals that the practitioners seem to prioritize Dataset Description and Dataset Structure sections, while the Considerations for Using the Data section receives the lowest proportion of content. (3) By analyzing the subsections within each section and utilizing topic modeling to identify key topics, we uncover what is discussed in each section, and underscore significant themes encompassing both technical and social impacts, as well as limitations within the Considerations for Using the Data section. (4) Our findings also highlight the need for improved accessibility and reproducibility of datasets in the Usage sections. (5) In addition, our human annotation evaluation emphasizes the pivotal role of comprehensive dataset content in shaping individuals' perceptions of a dataset card's overall quality. Overall, our study offers a unique perspective on analyzing dataset documentation through large-scale data science analysis and underlines the need for more thorough dataset documentation in machine learning research.
Can AI Be as Creative as Humans?
Jan 12, 2024
Creativity serves as a cornerstone for societal progress and innovation. With the rise of advanced generative AI models capable of tasks once reserved for human creativity, the study of AI's creative potential becomes imperative for its responsible development and application. In this paper, we provide a theoretical answer to the question of whether AI can be creative. We prove in theory that AI can be as creative as humans under the condition that AI can fit the existing data generated by human creators. Therefore, the debate on AI's creativity is reduced into the question of its ability of fitting a massive amount of data. To arrive at this conclusion, this paper first addresses the complexities in defining creativity by introducing a new concept called Relative Creativity. Instead of trying to define creativity universally, we shift the focus to whether AI can match the creative abilities of a hypothetical human. This perspective draws inspiration from the Turing Test, expanding upon it to address the challenges and subjectivities inherent in assessing creativity. This methodological shift leads to a statistically quantifiable assessment of AI's creativity, which we term Statistical Creativity. This concept allows for comparisons of AI's creative abilities with those of specific human groups, and facilitates the theoretical findings of AI's creative potential. Building on this foundation, we discuss the application of statistical creativity in prompt-conditioned autoregressive models, providing a practical means for evaluating creative abilities of contemporary AI models, such as Large Language Models (LLMs). In addition to defining and analyzing creativity, we introduce an actionable training guideline, effectively bridging the gap between theoretical quantification of creativity and practical model training.
Learning and Forgetting Unsafe Examples in Large Language Models
Dec 20, 2023



As the number of large language models (LLMs) released to the public grows, there is a pressing need to understand the safety implications associated with these models learning from third-party custom finetuning data. We explore the behavior of LLMs finetuned on noisy custom data containing unsafe content, represented by datasets that contain biases, toxicity, and harmfulness, finding that while aligned LLMs can readily learn this unsafe content, they also tend to forget it more significantly than other examples when subsequently finetuned on safer content. Drawing inspiration from the discrepancies in forgetting, we introduce the "ForgetFilter" algorithm, which filters unsafe data based on how strong the model's forgetting signal is for that data. We demonstrate that the ForgetFilter algorithm ensures safety in customized finetuning without compromising downstream task performance, unlike sequential safety finetuning. ForgetFilter outperforms alternative strategies like replay and moral self-correction in curbing LLMs' ability to assimilate unsafe content during custom finetuning, e.g. 75% lower than not applying any safety measures and 62% lower than using self-correction in toxicity score.
Zoology: Measuring and Improving Recall in Efficient Language Models
Dec 08, 2023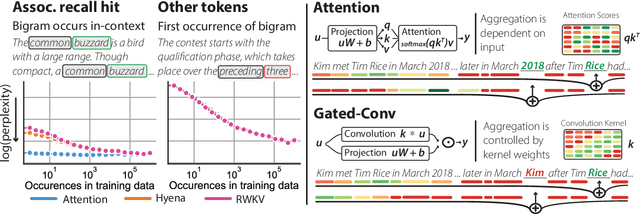



Attention-free language models that combine gating and convolutions are growing in popularity due to their efficiency and increasingly competitive performance. To better understand these architectures, we pretrain a suite of 17 attention and "gated-convolution" language models, finding that SoTA gated-convolution architectures still underperform attention by up to 2.1 perplexity points on the Pile. In fine-grained analysis, we find 82% of the gap is explained by each model's ability to recall information that is previously mentioned in-context, e.g. "Hakuna Matata means no worries Hakuna Matata it means no" $\rightarrow$ "??". On this task, termed "associative recall", we find that attention outperforms gated-convolutions by a large margin: a 70M parameter attention model outperforms a 1.4 billion parameter gated-convolution model on associative recall. This is surprising because prior work shows gated convolutions can perfectly solve synthetic tests for AR capability. To close the gap between synthetics and real language, we develop a new formalization of the task called multi-query associative recall (MQAR) that better reflects actual language. We perform an empirical and theoretical study of MQAR that elucidates differences in the parameter-efficiency of attention and gated-convolution recall. Informed by our analysis, we evaluate simple convolution-attention hybrids and show that hybrids with input-dependent sparse attention patterns can close 97.4% of the gap to attention, while maintaining sub-quadratic scaling. Our code is accessible at: https://github.com/HazyResearch/zoology.
GraphMETRO: Mitigating Complex Distribution Shifts in GNNs via Mixture of Aligned Experts
Dec 07, 2023



Graph Neural Networks' (GNNs) ability to generalize across complex distributions is crucial for real-world applications. However, prior research has primarily focused on specific types of distribution shifts, such as larger graph size, or inferred shifts from constructed data environments, which is highly limited when confronted with multiple and nuanced distribution shifts. For instance, in a social graph, a user node might experience increased interactions and content alterations, while other user nodes encounter distinct shifts. Neglecting such complexities significantly impedes generalization. To address it, we present GraphMETRO, a novel framework that enhances GNN generalization under complex distribution shifts in both node and graph-level tasks. Our approach employs a mixture-of-experts (MoE) architecture with a gating model and expert models aligned in a shared representation space. The gating model identifies key mixture components governing distribution shifts, while each expert generates invariant representations w.r.t. a mixture component. Finally, GraphMETRO aggregates representations from multiple experts to generate the final invariant representation. Our experiments on synthetic and realworld datasets demonstrate GraphMETRO's superiority and interpretability. To highlight, GraphMETRO achieves state-of-the-art performances on four real-world datasets from GOOD benchmark, outperforming the best baselines on WebKB and Twitch datasets by 67% and 4.2%, respectively.