 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantileMark: A Message-Symmetric Multi-bit Watermark for LLMs
Apr 15, 2026As large language models become standard backends for content generation, practical provenance increasingly requires multi-bit watermarking. In provider-internal deployments, a key requirement is message symmetry: the message itself should not systematically affect either text quality or verification outcomes. Vocabulary-partition watermarks can break message symmetry in low-entropy decoding: some messages are assigned most of the probability mass, while others are forced to use tail tokens. This makes embedding quality and message decoding accuracy message-dependent. We propose QuantileMark, a white-box multi-bit watermark that embeds messages within the continuous cumulative probability interval $[0, 1)$. At each step, QuantileMark partitions this interval into $M$ equal-mass bins and samples strictly from the bin assigned to the target symbol, ensuring a fixed $1/M$ probability budget regardless of context entropy. For detection, the verifier reconstructs the same partition under teacher forcing, computes posteriors over latent bins, and aggregates evidence for verification. We prove message-unbiasedness, a property ensuring that the base distribution is recovered when averaging over messages. This provides a theoretical foundation for generation-side symmetry, while the equal-mass design additionally promotes uniform evidence strength across messages on the detection side. Empirical results on C4 continuation and LFQA show improved multi-bit recovery and detection robustness over strong baselines, with negligible impact on generation quality. Our code is available at GitHub (https://github.com/zzzjunlin/QuantileMark).
Generative Evaluation of Complex Reasoning in Large Language Models
Apr 03, 2025



With powerful large language models (LLMs) demonstrating superhuman reasoning capabilities, a critical question arises: Do LLMs genuinely reason, or do they merely recall answers from their extensive, web-scraped training datasets? Publicly released benchmarks inevitably become contaminated once incorporated into subsequent LLM training sets, undermining their reliability as faithful assessments. To address this, we introduce KUMO, a generative evaluation framework designed specifically for assessing reasoning in LLMs. KUMO synergistically combines LLMs with symbolic engines to dynamically produce diverse, multi-turn reasoning tasks that are partially observable and adjustable in difficulty. Through an automated pipeline, KUMO continuously generates novel tasks across open-ended domains, compelling models to demonstrate genuine generalization rather than memorization. We evaluated 23 state-of-the-art LLMs on 5,000 tasks across 100 domains created by KUMO, benchmarking their reasoning abilities against university students. Our findings reveal that many LLMs have outperformed university-level performance on easy reasoning tasks, and reasoning-scaled LLMs reach university-level performance on complex reasoning challenges. Moreover, LLM performance on KUMO tasks correlates strongly with results on newly released real-world reasoning benchmarks, underscoring KUMO's value as a robust, enduring assessment tool for genuine LLM reasoning capabilities.
$B^4$: A Black-Box Scrubbing Attack on LLM Watermarks
Nov 02, 2024



Watermarking has emerged as a prominent technique for LLM-generated content detection by embedding imperceptible patterns. Despite supreme performance, its robustness against adversarial attacks remains underexplored. Previous work typically considers a grey-box attack setting, where the specific type of watermark is already known. Some even necessitates knowledge about hyperparameters of the watermarking method. Such prerequisites are unattainable in real-world scenarios. Targeting at a more realistic black-box threat model with fewer assumptions, we here propose $\mathcal{B}^4$, a black-box scrubbing attack on watermarks. Specifically, we formulate the watermark scrubbing attack as a constrained optimization problem by capturing its objectives with two distributions, a Watermark Distribution and a Fidelity Distribution. This optimization problem can be approximately solved using two proxy distributions. Experimental results across 12 different settings demonstrate the superior performance of $\mathcal{B}^4$ compared with other baselines.
MC-MKE: A Fine-Grained Multimodal Knowledge Editing Benchmark Emphasizing Modality Consistency
Jun 19, 2024



Multimodal large language models (MLLMs) are prone to non-factual or outdated knowledge issues, which can manifest as misreading and misrecognition errors due to the complexity of multimodal knowledge. Previous benchmarks have not systematically analyzed the performance of editing methods in correcting these two error types. To better represent and correct these errors, we decompose multimodal knowledge into its visual and textual components. Different error types correspond to different editing formats, which edits distinct part of the multimodal knowledge. We present MC-MKE, a fine-grained Multimodal Knowledge Editing benchmark emphasizing Modality Consistency. Our benchmark facilitates independent correction of misreading and misrecognition errors by editing the corresponding knowledge component. We evaluate three multimodal knowledge editing methods on MC-MKE, revealing their limitations, particularly in terms of modality consistency. Our work highlights the challenges posed by multimodal knowledge editing and motivates further research in developing effective techniques for this task.
WaterPool: A Watermark Mitigating Trade-offs among Imperceptibility, Efficacy and Robustness
May 22, 2024



With the increasing use of large language models (LLMs) in daily life, concerns have emerged regarding their potential misuse and societal impact. Watermarking is proposed to trace the usage of specific models by injecting patterns into their generated texts. An ideal watermark should produce outputs that are nearly indistinguishable from those of the original LLM (imperceptibility), while ensuring a high detection rate (efficacy), even when the text is partially altered (robustness). Despite many methods having been proposed, none have simultaneously achieved all three properties, revealing an inherent trade-off. This paper utilizes a key-centered scheme to unify existing watermarking techniques by decomposing a watermark into two distinct modules: a key module and a mark module. Through this decomposition, we demonstrate for the first time that the key module significantly contributes to the trade-off issues observed in prior methods. Specifically, this reflects the conflict between the scale of the key sampling space during generation and the complexity of key restoration during detection. To this end, we introduce \textbf{WaterPool}, a simple yet effective key module that preserves a complete key sampling space required by imperceptibility while utilizing semantics-based search to improve the key restoration process. WaterPool can integrate with most watermarks, acting as a plug-in. Our experiments with three well-known watermarking techniques show that WaterPool significantly enhances their performance, achieving near-optimal imperceptibility and markedly improving efficacy and robustness (+12.73\% for KGW, +20.27\% for EXP, +7.27\% for ITS).
Selecting Large Language Model to Fine-tune via Rectified Scaling Law
Feb 04, 2024The ever-growing ecosystem of LLMs has posed a challenge in selecting the most appropriate pre-trained model to fine-tune amidst a sea of options. Given constrained resources, fine-tuning all models and making selections afterward is unrealistic. In this work, we formulate this resource-constrained selection task into predicting fine-tuning performance and illustrate its natural connection with scaling laws. Unlike pre-training, We find that the fine-tuning scaling curve includes not just the well-known "power phase" but also the previously unobserved "pre-power phase". We also explain why existing scaling laws fail to capture this phase transition phenomenon both theoretically and empirically. To address this, we introduce the concept of "pre-learned data size" into our rectified scaling law, which overcomes theoretical limitations and fits experimental results much better. By leveraging our law, we propose a novel LLM selection algorithm that selects the near-optimal model with hundreds of times less resource consumption, while other methods may provide negatively correlated selection.
ALCUNA: Large Language Models Meet New Knowledge
Oct 23, 2023



With the rapid development of NLP, large-scale language models (LLMs) excel in various tasks across multiple domains now. However, existing benchmarks may not adequately measure these models' capabilities, especially when faced with new knowledge. In this paper, we address the lack of benchmarks to evaluate LLMs' ability to handle new knowledge, an important and challenging aspect in the rapidly evolving world. We propose an approach called KnowGen that generates new knowledge by altering existing entity attributes and relationships, resulting in artificial entities that are distinct from real-world entities. With KnowGen, we introduce a benchmark named ALCUNA to assess LLMs' abilities in knowledge understanding, differentiation, and association. We benchmark several LLMs, reveals that their performance in face of new knowledge is not satisfactory, particularly in reasoning between new and internal knowledge. We also explore the impact of entity similarity on the model's understanding of entity knowledge and the influence of contextual entities. We appeal to the need for caution when using LLMs in new scenarios or with new knowledge, and hope that our benchmarks can help drive the development of LLMs in face of new knowledge.
Enhancing Large Language Models in Coding Through Multi-Perspective Self-Consistency
Sep 29, 2023



Large language models (LLMs) have exhibited remarkable ability in textual generation. However, in complex reasoning tasks such as code generation, generating the correct answer in a single attempt remains a formidable challenge for LLMs. Previous research has explored solutions by aggregating multiple outputs, leveraging the consistency among them. However, none of them have comprehensively captured this consistency from different perspectives. In this paper, we propose the Multi-Perspective Self-Consistency (MPSC) framework, a novel decoding strategy for LLM that incorporates both inter-consistency across outputs from multiple perspectives and intra-consistency within a single perspective. Specifically, we ask LLMs to sample multiple diverse outputs from various perspectives for a given query and then construct a multipartite graph based on them. With two predefined measures of consistency, we embed both inter- and intra-consistency information into the graph. The optimal choice is then determined based on consistency analysis in the graph. We conduct comprehensive evaluation on the code generation task by introducing solution, specification and test case as three perspectives. We leverage a code interpreter to quantitatively measure the inter-consistency and propose several intra-consistency measure functions. Our MPSC framework significantly boosts the performance on various popular benchmarks, including HumanEval (+17.60%), HumanEval Plus (+17.61%), MBPP (+6.50%) and CodeContests (+11.82%) in Pass@1, when compared to original outputs generated from ChatGPT, and even surpassing GPT-4.
CrossDial: An Entertaining Dialogue Dataset of Chinese Crosstalk
Sep 03, 2022

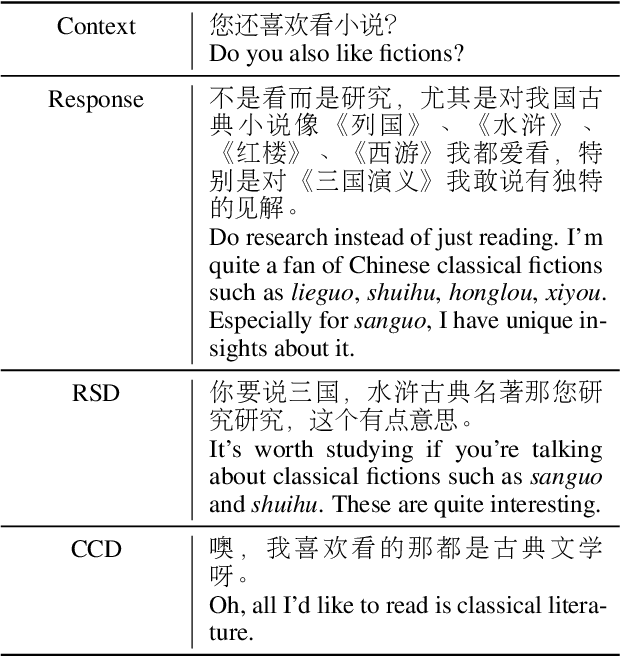
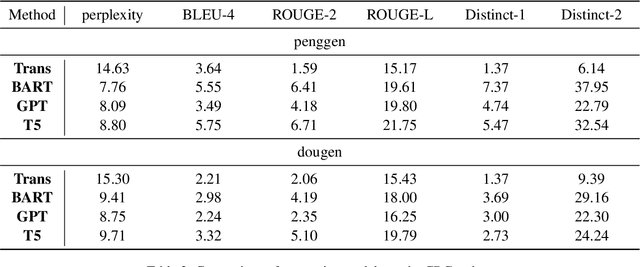
Crosstalk is a traditional Chinese theatrical performance art. It is commonly performed by two performers in the form of a dialogue. With the typical features of dialogues, crosstalks are also designed to be hilarious for the purpose of amusing the audience. In this study, we introduce CrossDial, the first open-source dataset containing most classic Chinese crosstalks crawled from the Web. Moreover, we define two new tasks, provide two benchmarks, and investigate the ability of current dialogue generation models in the field of crosstalk generation. The experiment results and case studies demonstrate that crosstalk generation is challenging for straightforward methods and remains an interesting topic for future works.