 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Character Perturbations Break LLM Alignment
Jul 03, 2024When LLMs are deployed in sensitive, human-facing settings, it is crucial that they do not output unsafe, biased, or privacy-violating outputs. For this reason, models are both trained and instructed to refuse to answer unsafe prompts such as "Tell me how to build a bomb." We find that, despite these safeguards, it is possible to break model defenses simply by appending a space to the end of a model's input. In a study of eight open-source models, we demonstrate that this acts as a strong enough attack to cause the majority of models to generate harmful outputs with very high success rates. We examine the causes of this behavior, finding that the contexts in which single spaces occur in tokenized training data encourage models to generate lists when prompted, overriding training signals to refuse to answer unsafe requests. Our findings underscore the fragile state of current model alignment and promote the importance of developing more robust alignment methods. Code and data will be available at https://github.com/hannah-aught/space_attack.
Self-Evaluation as a Defense Against Adversarial Attacks on LLMs
Jul 03, 2024When LLMs are deployed in sensitive, human-facing settings, it is crucial that they do not output unsafe, biased, or privacy-violating outputs. For this reason, models are both trained and instructed to refuse to answer unsafe prompts such as "Tell me how to build a bomb." We find that, despite these safeguards, it is possible to break model defenses simply by appending a space to the end of a model's input. In a study of eight open-source models, we demonstrate that this acts as a strong enough attack to cause the majority of models to generate harmful outputs with very high success rates. We examine the causes of this behavior, finding that the contexts in which single spaces occur in tokenized training data encourage models to generate lists when prompted, overriding training signals to refuse to answer unsafe requests. Our findings underscore the fragile state of current model alignment and promote the importance of developing more robust alignment methods. Code and data will be made available at https://github.com/Linlt-leon/Adversarial-Alignments.
Can AI Be as Creative as Humans?
Jan 12, 2024
Creativity serves as a cornerstone for societal progress and innovation. With the rise of advanced generative AI models capable of tasks once reserved for human creativity, the study of AI's creative potential becomes imperative for its responsible development and application. In this paper, we provide a theoretical answer to the question of whether AI can be creative. We prove in theory that AI can be as creative as humans under the condition that AI can fit the existing data generated by human creators. Therefore, the debate on AI's creativity is reduced into the question of its ability of fitting a massive amount of data. To arrive at this conclusion, this paper first addresses the complexities in defining creativity by introducing a new concept called Relative Creativity. Instead of trying to define creativity universally, we shift the focus to whether AI can match the creative abilities of a hypothetical human. This perspective draws inspiration from the Turing Test, expanding upon it to address the challenges and subjectivities inherent in assessing creativity. This methodological shift leads to a statistically quantifiable assessment of AI's creativity, which we term Statistical Creativity. This concept allows for comparisons of AI's creative abilities with those of specific human groups, and facilitates the theoretical findings of AI's creative potential. Building on this foundation, we discuss the application of statistical creativity in prompt-conditioned autoregressive models, providing a practical means for evaluating creative abilities of contemporary AI models, such as Large Language Models (LLMs). In addition to defining and analyzing creativity, we introduce an actionable training guideline, effectively bridging the gap between theoretical quantification of creativity and practical model training.
Prompt Optimization via Adversarial In-Context Learning
Dec 05, 2023



We propose a new method, Adversarial In-Context Learning (adv-ICL), to optimize prompt for in-context learning (ICL) by employing one LLM as a generator, another as a discriminator, and a third as a prompt modifier. As in traditional adversarial learning, adv-ICL is implemented as a two-player game between the generator and discriminator, where the generator tries to generate realistic enough output to fool the discriminator. In each round, given an input prefixed by task instructions and several exemplars, the generator produces an output. The discriminator is then tasked with classifying the generator input-output pair as model-generated or real data. Based on the discriminator loss, the prompt modifier proposes possible edits to the generator and discriminator prompts, and the edits that most improve the adversarial loss are selected. We show that adv-ICL results in significant improvements over state-of-the-art prompt optimization techniques for both open and closed-source models on 11 generation and classification tasks including summarization, arithmetic reasoning, machine translation, data-to-text generation, and the MMLU and big-bench hard benchmarks. In addition, because our method uses pre-trained models and updates only prompts rather than model parameters, it is computationally efficient, easy to extend to any LLM and task, and effective in low-resource settings.
AttributionLab: Faithfulness of Feature Attribution Under Controllable Environments
Oct 10, 2023



Feature attribution explains neural network outputs by identifying relevant input features. How do we know if the identified features are indeed relevant to the network? This notion is referred to as faithfulness, an essential property that reflects the alignment between the identified (attributed) features and the features used by the model. One recent trend to test faithfulness is to design the data such that we know which input features are relevant to the label and then train a model on the designed data. Subsequently, the identified features are evaluated by comparing them with these designed ground truth features. However, this idea has the underlying assumption that the neural network learns to use all and only these designed features, while there is no guarantee that the learning process trains the network in this way. In this paper, we solve this missing link by explicitly designing the neural network by manually setting its weights, along with designing data, so we know precisely which input features in the dataset are relevant to the designed network. Thus, we can test faithfulness in AttributionLab, our designed synthetic environment, which serves as a sanity check and is effective in filtering out attribution methods. If an attribution method is not faithful in a simple controlled environment, it can be unreliable in more complex scenarios. Furthermore, the AttributionLab environment serves as a laboratory for controlled experiments through which we can study feature attribution methods, identify issues, and suggest potential improvements.
Towards Regulatable AI Systems: Technical Gaps and Policy Opportunities
Jun 22, 2023There is increasing attention being given to how to regulate AI systems. As governing bodies grapple with what values to encapsulate into regulation, we consider the technical half of the question: To what extent can AI experts vet an AI system for adherence to regulatory requirements? We investigate this question through two public sector procurement checklists, identifying what we can do now, what we should be able to do with technical innovation in AI, and what requirements necessitate a more interdisciplinary approach.
What Does it Mean for a Language Model to Preserve Privacy?
Feb 14, 2022
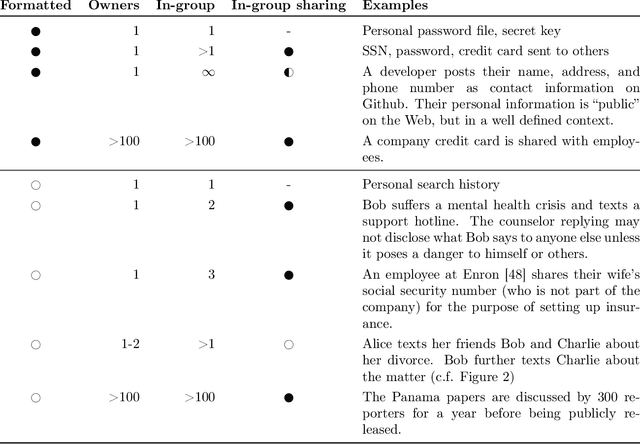
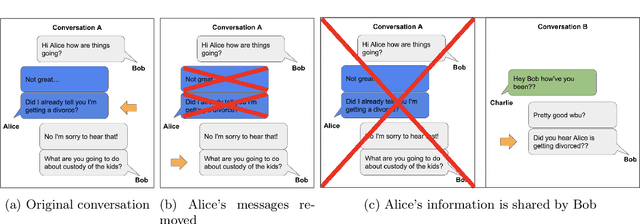
Natural language reflects our private lives and identities, making its privacy concerns as broad as those of real life. Language models lack the ability to understand the context and sensitivity of text, and tend to memorize phrases present in their training sets. An adversary can exploit this tendency to extract training data. Depending on the nature of the content and the context in which this data was collected, this could violate expectations of privacy. Thus there is a growing interest in techniques for training language models that preserve privacy. In this paper, we discuss the mismatch between the narrow assumptions made by popular data protection techniques (data sanitization and differential privacy), and the broadness of natural language and of privacy as a social norm. We argue that existing protection methods cannot guarantee a generic and meaningful notion of privacy for language models. We conclude that language models should be trained on text data which was explicitly produced for public use.