 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedArena: Comparing LLMs for Medicine-in-the-Wild Clinician Preferences
Mar 13, 2026Large language models (LLMs) are increasingly central to clinician workflows, spanning clinical decision support, medical education, and patient communication. However, current evaluation methods for medical LLMs rely heavily on static, templated benchmarks that fail to capture the complexity and dynamics of real-world clinical practice, creating a dissonance between benchmark performance and clinical utility. To address these limitations, we present MedArena, an interactive evaluation platform that enables clinicians to directly test and compare leading LLMs using their own medical queries. Given a clinician-provided query, MedArena presents responses from two randomly selected models and asks the user to select the preferred response. Out of 1571 preferences collected across 12 LLMs up to November 1, 2025, Gemini 2.0 Flash Thinking, Gemini 2.5 Pro, and GPT-4o were the top three models by Bradley-Terry rating. Only one-third of clinician-submitted questions resembled factual recall tasks (e.g., MedQA), whereas the majority addressed topics such as treatment selection, clinical documentation, or patient communication, with ~20% involving multi-turn conversations. Additionally, clinicians cited depth and detail and clarity of presentation more often than raw factual accuracy when explaining their preferences, highlighting the importance of readability and clinical nuance. We also confirm that the model rankings remain stable even after controlling for style-related factors like response length and formatting. By grounding evaluation in real-world clinical questions and preferences, MedArena offers a scalable platform for measuring and improving the utility and efficacy of medical LLMs.
MedCaseReasoning: Evaluating and learning diagnostic reasoning from clinical case reports
May 16, 2025Doctors and patients alike increasingly use Large Language Models (LLMs) to diagnose clinical cases. However, unlike domains such as math or coding, where correctness can be objectively defined by the final answer, medical diagnosis requires both the outcome and the reasoning process to be accurate. Currently, widely used medical benchmarks like MedQA and MMLU assess only accuracy in the final answer, overlooking the quality and faithfulness of the clinical reasoning process. To address this limitation, we introduce MedCaseReasoning, the first open-access dataset for evaluating LLMs on their ability to align with clinician-authored diagnostic reasoning. The dataset includes 14,489 diagnostic question-and-answer cases, each paired with detailed reasoning statements derived from open-access medical case reports. We evaluate state-of-the-art reasoning LLMs on MedCaseReasoning and find significant shortcomings in their diagnoses and reasoning: for instance, the top-performing open-source model, DeepSeek-R1, achieves only 48% 10-shot diagnostic accuracy and mentions only 64% of the clinician reasoning statements (recall). However, we demonstrate that fine-tuning LLMs on the reasoning traces derived from MedCaseReasoning significantly improves diagnostic accuracy and clinical reasoning recall by an average relative gain of 29% and 41%, respectively. The open-source dataset, code, and models are available at https://github.com/kevinwu23/Stanford-MedCaseReasoning.
Disentangling Reasoning and Knowledge in Medical Large Language Models
May 16, 2025



Medical reasoning in large language models (LLMs) aims to emulate clinicians' diagnostic thinking, but current benchmarks such as MedQA-USMLE, MedMCQA, and PubMedQA often mix reasoning with factual recall. We address this by separating 11 biomedical QA benchmarks into reasoning- and knowledge-focused subsets using a PubMedBERT classifier that reaches 81 percent accuracy, comparable to human performance. Our analysis shows that only 32.8 percent of questions require complex reasoning. We evaluate biomedical models (HuatuoGPT-o1, MedReason, m1) and general-domain models (DeepSeek-R1, o4-mini, Qwen3), finding consistent gaps between knowledge and reasoning performance. For example, m1 scores 60.5 on knowledge but only 47.1 on reasoning. In adversarial tests where models are misled with incorrect initial reasoning, biomedical models degrade sharply, while larger or RL-trained general models show more robustness. To address this, we train BioMed-R1 using fine-tuning and reinforcement learning on reasoning-heavy examples. It achieves the strongest performance among similarly sized models. Further gains may come from incorporating clinical case reports and training with adversarial and backtracking scenarios.
FineTuneBench: How well do commercial fine-tuning APIs infuse knowledge into LLMs?
Nov 07, 2024



There is great interest in fine-tuning frontier large language models (LLMs) to inject new information and update existing knowledge. While commercial LLM fine-tuning APIs from providers such as OpenAI and Google promise flexible adaptation for various applications, the efficacy of fine-tuning remains unclear. In this study, we introduce FineTuneBench, an evaluation framework and dataset for understanding how well commercial fine-tuning APIs can successfully learn new and updated knowledge. We analyze five frontier LLMs with commercially available fine-tuning APIs, including GPT-4o and Gemini 1.5 Pro, on their effectiveness in two settings: (1) ingesting novel information, such as recent news events and new people profiles, and (2) updating existing knowledge, such as updated medical guidelines and code frameworks. Our results reveal substantial shortcomings in all the models' abilities to effectively learn new information through fine-tuning, with an average generalization accuracy of 37% across all models. When updating existing knowledge, such as incorporating medical guideline updates, commercial fine-tuning APIs show even more limited capability (average generalization accuracy of 19%). Overall, fine-tuning GPT-4o mini is the most effective for infusing new knowledge and updating knowledge, followed by GPT-3.5 Turbo and GPT-4o. The fine-tuning APIs for Gemini 1.5 Flesh and Gemini 1.5 Pro are unable to learn new knowledge or update existing knowledge. These findings underscore a major shortcoming in using current commercial fine-tuning services to achieve reliable knowledge infusion in common scenarios. We open source the FineTuneBench dataset at https://github.com/kevinwu23/StanfordFineTuneBench.
How faithful are RAG models? Quantifying the tug-of-war between RAG and LLMs' internal prior
Apr 16, 2024



Retrieval augmented generation (RAG) is often used to fix hallucinations and provide up-to-date knowledge for large language models (LLMs). However, in cases when the LLM alone incorrectly answers a question, does providing the correct retrieved content always fix the error? Conversely, in cases where the retrieved content is incorrect, does the LLM know to ignore the wrong information, or does it recapitulate the error? To answer these questions, we systematically analyze the tug-of-war between a LLM's internal knowledge (i.e. its prior) and the retrieved information in settings when they disagree. We test GPT-4 and other LLMs on question-answering abilities across datasets with and without reference documents. As expected, providing the correct retrieved information fixes most model mistakes (94% accuracy). However, when the reference document is perturbed with increasing levels of wrong values, the LLM is more likely to recite the incorrect, modified information when its internal prior is weaker but is more resistant when its prior is stronger. Similarly, we also find that the more the modified information deviates from the model's prior, the less likely the model is to prefer it. These results highlight an underlying tension between a model's prior knowledge and the information presented in reference documents.
What's documented in AI? Systematic Analysis of 32K AI Model Cards
Feb 07, 2024The rapid proliferation of AI models has underscored the importance of thorough documentation, as it enables users to understand, trust, and effectively utilize these models in various applications. Although developers are encouraged to produce model cards, it's not clear how much information or what information these cards contain. In this study, we conduct a comprehensive analysis of 32,111 AI model documentations on Hugging Face, a leading platform for distributing and deploying AI models. Our investigation sheds light on the prevailing model card documentation practices. Most of the AI models with substantial downloads provide model cards, though the cards have uneven informativeness. We find that sections addressing environmental impact, limitations, and evaluation exhibit the lowest filled-out rates, while the training section is the most consistently filled-out. We analyze the content of each section to characterize practitioners' priorities. Interestingly, there are substantial discussions of data, sometimes with equal or even greater emphasis than the model itself. To evaluate the impact of model cards, we conducted an intervention study by adding detailed model cards to 42 popular models which had no or sparse model cards previously. We find that adding model cards is moderately correlated with an increase weekly download rates. Our study opens up a new perspective for analyzing community norms and practices for model documentation through large-scale data science and linguistics analysis.
How well do LLMs cite relevant medical references? An evaluation framework and analyses
Feb 03, 2024Large language models (LLMs) are currently being used to answer medical questions across a variety of clinical domains. Recent top-performing commercial LLMs, in particular, are also capable of citing sources to support their responses. In this paper, we ask: do the sources that LLMs generate actually support the claims that they make? To answer this, we propose three contributions. First, as expert medical annotations are an expensive and time-consuming bottleneck for scalable evaluation, we demonstrate that GPT-4 is highly accurate in validating source relevance, agreeing 88% of the time with a panel of medical doctors. Second, we develop an end-to-end, automated pipeline called \textit{SourceCheckup} and use it to evaluate five top-performing LLMs on a dataset of 1200 generated questions, totaling over 40K pairs of statements and sources. Interestingly, we find that between ~50% to 90% of LLM responses are not fully supported by the sources they provide. We also evaluate GPT-4 with retrieval augmented generation (RAG) and find that, even still, around 30\% of individual statements are unsupported, while nearly half of its responses are not fully supported. Third, we open-source our curated dataset of medical questions and expert annotations for future evaluations. Given the rapid pace of LLM development and the potential harms of incorrect or outdated medical information, it is crucial to also understand and quantify their capability to produce relevant, trustworthy medical references.
DataInf: Efficiently Estimating Data Influence in LoRA-tuned LLMs and Diffusion Models
Oct 02, 2023Quantifying the impact of training data points is crucial for understanding the outputs of machine learning models and for improving the transparency of the AI pipeline. The influence function is a principled and popular data attribution method, but its computational cost often makes it challenging to use. This issue becomes more pronounced in the setting of large language models and text-to-image models. In this work, we propose DataInf, an efficient influence approximation method that is practical for large-scale generative AI models. Leveraging an easy-to-compute closed-form expression, DataInf outperforms existing influence computation algorithms in terms of computational and memory efficiency. Our theoretical analysis shows that DataInf is particularly well-suited for parameter-efficient fine-tuning techniques such as LoRA. Through systematic empirical evaluations, we show that DataInf accurately approximates influence scores and is orders of magnitude faster than existing methods. In applications to RoBERTa-large, Llama-2-13B-chat, and stable-diffusion-v1.5 models, DataInf effectively identifies the most influential fine-tuning examples better than other approximate influence scores. Moreover, it can help to identify which data points are mislabeled.
GPT detectors are biased against non-native English writers
Apr 18, 2023

The rapid adoption of generative language models has brought about substantial advancements in digital communication, while simultaneously raising concerns regarding the potential misuse of AI-generated content. Although numerous detection methods have been proposed to differentiate between AI and human-generated content, the fairness and robustness of these detectors remain underexplored. In this study, we evaluate the performance of several widely-used GPT detectors using writing samples from native and non-native English writers. Our findings reveal that these detectors consistently misclassify non-native English writing samples as AI-generated, whereas native writing samples are accurately identified. Furthermore, we demonstrate that simple prompting strategies can not only mitigate this bias but also effectively bypass GPT detectors, suggesting that GPT detectors may unintentionally penalize writers with constrained linguistic expressions. Our results call for a broader conversation about the ethical implications of deploying ChatGPT content detectors and caution against their use in evaluative or educational settings, particularly when they may inadvertently penalize or exclude non-native English speakers from the global discourse.
Explaining medical AI performance disparities across sites with confounder Shapley value analysis
Nov 12, 2021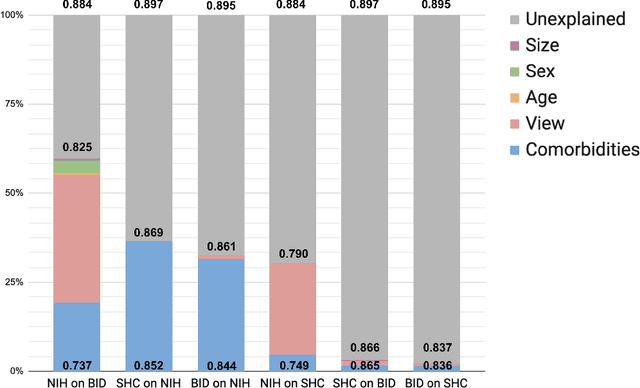

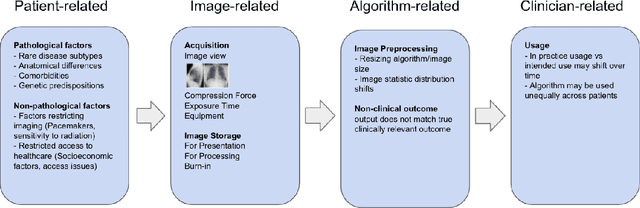
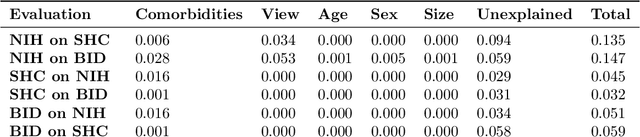
Medical AI algorithms can often experience degraded performance when evaluated on previously unseen sites. Addressing cross-site performance disparities is key to ensuring that AI is equitable and effective when deployed on diverse patient populations. Multi-site evaluations are key to diagnosing such disparities as they can test algorithms across a broader range of potential biases such as patient demographics, equipment types, and technical parameters. However, such tests do not explain why the model performs worse. Our framework provides a method for quantifying the marginal and cumulative effect of each type of bias on the overall performance difference when a model is evaluated on external data. We demonstrate its usefulness in a case study of a deep learning model trained to detect the presence of pneumothorax, where our framework can help explain up to 60% of the discrepancy in performance across different sites with known biases like disease comorbidities and imaging parameters.