 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Potential of Consistency Learning for Detecting and Grounding Multi-Modal Media Manipulation
Jun 06, 2025
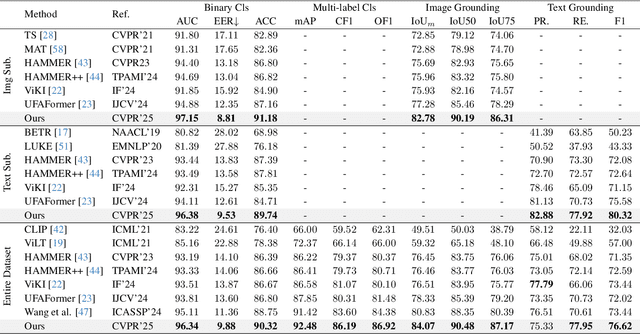
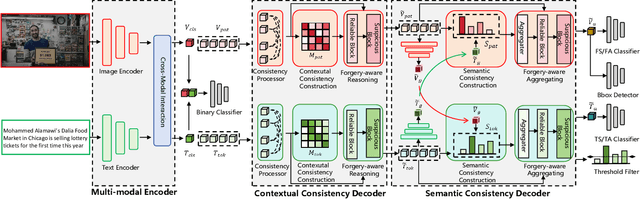
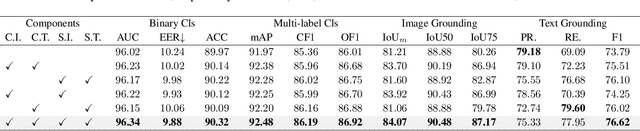
To tackle the threat of fake news, the task of detecting and grounding multi-modal media manipulation DGM4 has received increasing attention. However, most state-of-the-art methods fail to explore the fine-grained consistency within local content, usually resulting in an inadequate perception of detailed forgery and unreliable results. In this paper, we propose a novel approach named Contextual-Semantic Consistency Learning (CSCL) to enhance the fine-grained perception ability of forgery for DGM4. Two branches for image and text modalities are established, each of which contains two cascaded decoders, i.e., Contextual Consistency Decoder (CCD) and Semantic Consistency Decoder (SCD), to capture within-modality contextual consistency and across-modality semantic consistency, respectively. Both CCD and SCD adhere to the same criteria for capturing fine-grained forgery details. To be specific, each module first constructs consistency features by leveraging additional supervision from the heterogeneous information of each token pair. Then, the forgery-aware reasoning or aggregating is adopted to deeply seek forgery cues based on the consistency features. Extensive experiments on DGM4 datasets prove that CSCL achieves new state-of-the-art performance, especially for the results of grounding manipulated content. Codes and weights are avaliable at https://github.com/liyih/CSCL.
DOGe: Defensive Output Generation for LLM Protection Against Knowledge Distillation
May 26, 2025
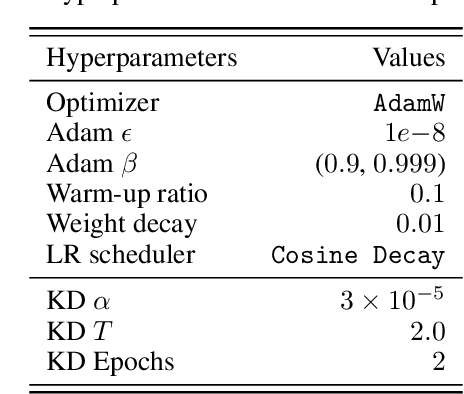
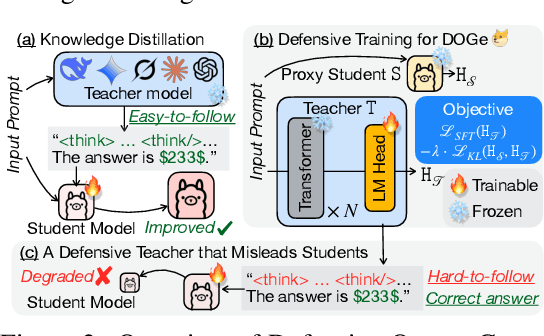

Large Language Models (LLMs) represent substantial intellectual and economic investments, yet their effectiveness can inadvertently facilitate model imitation via knowledge distillation (KD).In practical scenarios, competitors can distill proprietary LLM capabilities by simply observing publicly accessible outputs, akin to reverse-engineering a complex performance by observation alone. Existing protective methods like watermarking only identify imitation post-hoc, while other defenses assume the student model mimics the teacher's internal logits, rendering them ineffective against distillation purely from observed output text. This paper confronts the challenge of actively protecting LLMs within the realistic constraints of API-based access. We introduce an effective and efficient Defensive Output Generation (DOGe) strategy that subtly modifies the output behavior of an LLM. Its outputs remain accurate and useful for legitimate users, yet are designed to be misleading for distillation, significantly undermining imitation attempts. We achieve this by fine-tuning only the final linear layer of the teacher LLM with an adversarial loss. This targeted training approach anticipates and disrupts distillation attempts during inference time. Our experiments show that, while preserving or even improving the original performance of the teacher model, student models distilled from the defensively generated teacher outputs demonstrate catastrophically reduced performance, demonstrating our method's effectiveness as a practical safeguard against KD-based model imitation.
Joint Detection of Fraud and Concept Drift inOnline Conversations with LLM-Assisted Judgment
May 07, 2025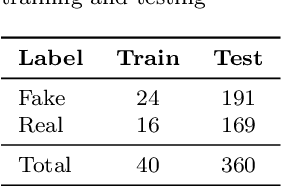
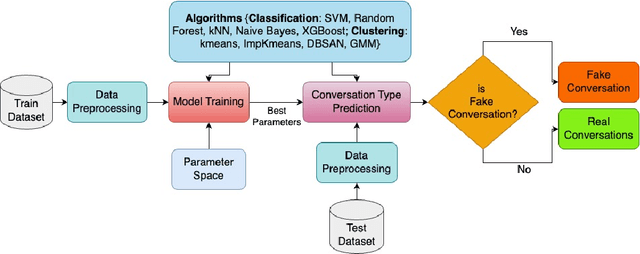
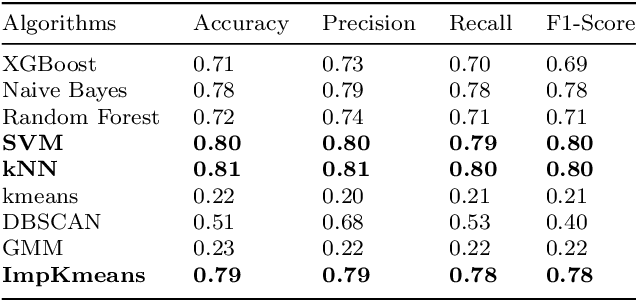
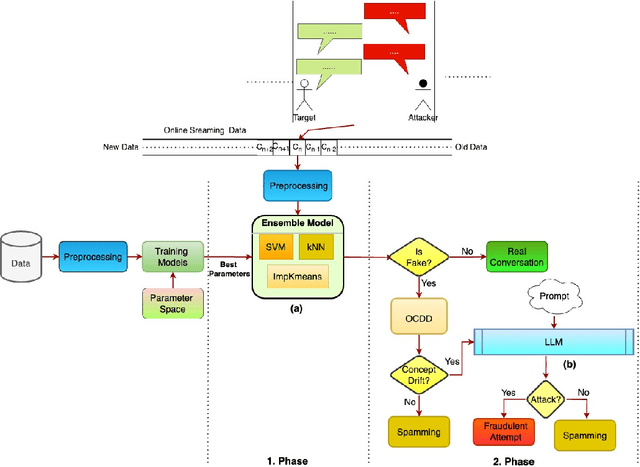
Detecting fake interactions in digital communication platforms remains a challenging and insufficiently addressed problem. These interactions may appear as harmless spam or escalate into sophisticated scam attempts, making it difficult to flag malicious intent early. Traditional detection methods often rely on static anomaly detection techniques that fail to adapt to dynamic conversational shifts. One key limitation is the misinterpretation of benign topic transitions referred to as concept drift as fraudulent behavior, leading to either false alarms or missed threats. We propose a two stage detection framework that first identifies suspicious conversations using a tailored ensemble classification model. To improve the reliability of detection, we incorporate a concept drift analysis step using a One Class Drift Detector (OCDD) to isolate conversational shifts within flagged dialogues. When drift is detected, a large language model (LLM) assesses whether the shift indicates fraudulent manipulation or a legitimate topic change. In cases where no drift is found, the behavior is inferred to be spam like. We validate our framework using a dataset of social engineering chat scenarios and demonstrate its practical advantages in improving both accuracy and interpretability for real time fraud detection. To contextualize the trade offs, we compare our modular approach against a Dual LLM baseline that performs detection and judgment using different language models.
Intrinsic Barriers to Explaining Deep Foundation Models
Apr 21, 2025Deep Foundation Models (DFMs) offer unprecedented capabilities but their increasing complexity presents profound challenges to understanding their internal workings-a critical need for ensuring trust, safety, and accountability. As we grapple with explaining these systems, a fundamental question emerges: Are the difficulties we face merely temporary hurdles, awaiting more sophisticated analytical techniques, or do they stem from \emph{intrinsic barriers} deeply rooted in the nature of these large-scale models themselves? This paper delves into this critical question by examining the fundamental characteristics of DFMs and scrutinizing the limitations encountered by current explainability methods when confronted with this inherent challenge. We probe the feasibility of achieving satisfactory explanations and consider the implications for how we must approach the verification and governance of these powerful technologies.
Are We Merely Justifying Results ex Post Facto? Quantifying Explanatory Inversion in Post-Hoc Model Explanations
Apr 11, 2025Post-hoc explanation methods provide interpretation by attributing predictions to input features. Natural explanations are expected to interpret how the inputs lead to the predictions. Thus, a fundamental question arises: Do these explanations unintentionally reverse the natural relationship between inputs and outputs? Specifically, are the explanations rationalizing predictions from the output rather than reflecting the true decision process? To investigate such explanatory inversion, we propose Inversion Quantification (IQ), a framework that quantifies the degree to which explanations rely on outputs and deviate from faithful input-output relationships. Using the framework, we demonstrate on synthetic datasets that widely used methods such as LIME and SHAP are prone to such inversion, particularly in the presence of spurious correlations, across tabular, image, and text domains. Finally, we propose Reproduce-by-Poking (RBP), a simple and model-agnostic enhancement to post-hoc explanation methods that integrates forward perturbation checks. We further show that under the IQ framework, RBP theoretically guarantees the mitigation of explanatory inversion. Empirically, for example, on the synthesized data, RBP can reduce the inversion by 1.8% on average across iconic post-hoc explanation approaches and domains.
Window Token Concatenation for Efficient Visual Large Language Models
Apr 05, 2025To effectively reduce the visual tokens in Visual Large Language Models (VLLMs), we propose a novel approach called Window Token Concatenation (WiCo). Specifically, we employ a sliding window to concatenate spatially adjacent visual tokens. However, directly concatenating these tokens may group diverse tokens into one, and thus obscure some fine details. To address this challenge, we propose fine-tuning the last few layers of the vision encoder to adaptively adjust the visual tokens, encouraging that those within the same window exhibit similar features. To further enhance the performance on fine-grained visual understanding tasks, we introduce WiCo+, which decomposes the visual tokens in later layers of the LLM. Such a design enjoys the merits of the large perception field of the LLM for fine-grained visual understanding while keeping a small number of visual tokens for efficient inference. We perform extensive experiments on both coarse- and fine-grained visual understanding tasks based on LLaVA-1.5 and Shikra, showing better performance compared with existing token reduction projectors. The code is available: https://github.com/JackYFL/WiCo.
A Survey of Scaling in Large Language Model Reasoning
Apr 02, 2025The rapid advancements in large Language models (LLMs) have significantly enhanced their reasoning capabilities, driven by various strategies such as multi-agent collaboration. However, unlike the well-established performance improvements achieved through scaling data and model size, the scaling of reasoning in LLMs is more complex and can even negatively impact reasoning performance, introducing new challenges in model alignment and robustness. In this survey, we provide a comprehensive examination of scaling in LLM reasoning, categorizing it into multiple dimensions and analyzing how and to what extent different scaling strategies contribute to improving reasoning capabilities. We begin by exploring scaling in input size, which enables LLMs to process and utilize more extensive context for improved reasoning. Next, we analyze scaling in reasoning steps that improves multi-step inference and logical consistency. We then examine scaling in reasoning rounds, where iterative interactions refine reasoning outcomes. Furthermore, we discuss scaling in training-enabled reasoning, focusing on optimization through iterative model improvement. Finally, we review applications of scaling across domains and outline future directions for further advancing LLM reasoning. By synthesizing these diverse perspectives, this survey aims to provide insights into how scaling strategies fundamentally enhance the reasoning capabilities of LLMs and further guide the development of next-generation AI systems.
CyberBOT: Towards Reliable Cybersecurity Education via Ontology-Grounded Retrieval Augmented Generation
Apr 01, 2025


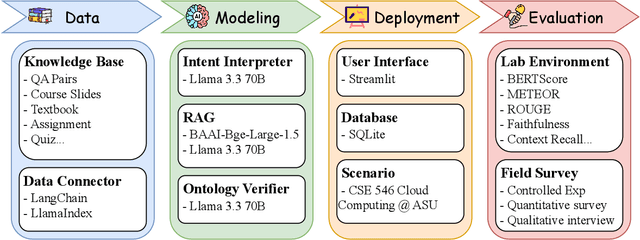
Advancements in large language models (LLMs) have enabled the development of intelligent educational tools that support inquiry-based learning across technical domains. In cybersecurity education, where accuracy and safety are paramount, systems must go beyond surface-level relevance to provide information that is both trustworthy and domain-appropriate. To address this challenge, we introduce CyberBOT, a question-answering chatbot that leverages a retrieval-augmented generation (RAG) pipeline to incorporate contextual information from course-specific materials and validate responses using a domain-specific cybersecurity ontology. The ontology serves as a structured reasoning layer that constrains and verifies LLM-generated answers, reducing the risk of misleading or unsafe guidance. CyberBOT has been deployed in a large graduate-level course at Arizona State University (ASU), where more than one hundred students actively engage with the system through a dedicated web-based platform. Computational evaluations in lab environments highlight the potential capacity of CyberBOT, and a forthcoming field study will evaluate its pedagogical impact. By integrating structured domain reasoning with modern generative capabilities, CyberBOT illustrates a promising direction for developing reliable and curriculum-aligned AI applications in specialized educational contexts.
RedditESS: A Mental Health Social Support Interaction Dataset -- Understanding Effective Social Support to Refine AI-Driven Support Tools
Mar 27, 2025Effective mental health support is crucial for alleviating psychological distress. While large language model (LLM)-based assistants have shown promise in mental health interventions, existing research often defines "effective" support primarily in terms of empathetic acknowledgments, overlooking other essential dimensions such as informational guidance, community validation, and tangible coping strategies. To address this limitation and better understand what constitutes effective support, we introduce RedditESS, a novel real-world dataset derived from Reddit posts, including supportive comments and original posters' follow-up responses. Grounded in established social science theories, we develop an ensemble labeling mechanism to annotate supportive comments as effective or not and perform qualitative assessments to ensure the reliability of the annotations. Additionally, we demonstrate the practical utility of RedditESS by using it to guide LLM alignment toward generating more context-sensitive and genuinely helpful supportive responses. By broadening the understanding of effective support, our study paves the way for advanced AI-driven mental health interventions.
Personalized Attacks of Social Engineering in Multi-turn Conversations -- LLM Agents for Simulation and Detection
Mar 18, 2025



The rapid advancement of conversational agents, particularly chatbots powered by Large Language Models (LLMs), poses a significant risk of social engineering (SE) attacks on social media platforms. SE detection in multi-turn, chat-based interactions is considerably more complex than single-instance detection due to the dynamic nature of these conversations. A critical factor in mitigating this threat is understanding the mechanisms through which SE attacks operate, specifically how attackers exploit vulnerabilities and how victims' personality traits contribute to their susceptibility. In this work, we propose an LLM-agentic framework, SE-VSim, to simulate SE attack mechanisms by generating multi-turn conversations. We model victim agents with varying personality traits to assess how psychological profiles influence susceptibility to manipulation. Using a dataset of over 1000 simulated conversations, we examine attack scenarios in which adversaries, posing as recruiters, funding agencies, and journalists, attempt to extract sensitive information. Based on this analysis, we present a proof of concept, SE-OmniGuard, to offer personalized protection to users by leveraging prior knowledge of the victims personality, evaluating attack strategies, and monitoring information exchanges in conversations to identify potential SE attempts.