 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency evaluation of benchmarks used for causal discovery
Jun 01, 2026In graphical causal model, causal discovery aims to construct a causal graph based on numerical data and domain knowledge in plain text. However, the evaluation of causal discovery methods remains a challenge in the area as the progress of domain researches often makes benchmark causal graphs contain mis-aligned knowledge. This problem especially affects the evaluation of large language model (LLM) based causal discovery methods as they are sensitive to the new discoveries in the literature. This work is the first to systematically study the quality of benchmark causal graphs. Specifically, we design a pipeline that automatically retrieves relevant research papers from scientific databases, and prompts LLMs to check the consistency between the benchmark causal graphs and domain research papers. We evaluate 11 popular real-world benchmarks, for which our pipeline in total proceeds 38,081 domain papers. Our results show that popular benchmarks vary significantly in their consistency with domain research, with clear implications for causal discovery research.
Swimming with Whales: Analysis of Power Imbalances in Stake-Weighted Governance
May 19, 2026Voting methods weighted by stakes are the fundamental governance paradigm in Proof-of-Stake (PoS) blockchains. Such a paradigm is known to be prone to power distortions: a few users possessing large stakes may completely control decision making, even without owning the totality of the stakes. We study this phenomenon through the lens of computational social choice, focusing on the extent of power imbalances in stake-weighted voting when power is quantified using the Penrose-Banzhaf power index. Our work presents both analytical and empirical contributions. Analytically, we demonstrate that while a perfect alignment between power and relative stake ownership is generally unattainable, it can be approximated in expectation under specific conditions. Empirically, using data from a real-world on-chain governance system (Project Catalyst), we provide a more fine-grained understanding of the power imbalances that are likely to occur in current stake-weighted governance systems.
Deep Speckle Holography Redefines Label-free Nanoparticle Phenotyping
May 03, 2026Nanoparticle metrology has long been constrained by the assumption that, in mixed and unprocessed fluids, particle size, morphology, composition, and species-specific abundance cannot be resolved simultaneously from a single label-free measurement. Here, we revisit this long-standing limitation by showing that complex forward speckle-holographic fields define an information-rich optical space for multidimensional particle signatures. We report deep speckle holography, a physics-informed generative framework that profiles particle identity, size, morphology, and species-resolved abundance from a single non-contact optical measurement. Across purified suspensions, mixed particle populations, environmental waters, human urine, and other unprocessed native fluids, the method enables direct nanoparticle inference without purification, labeling, or destructive preprocessing, delivering concurrent multidimensional readouts in 0.9 s over a dynamic range spanning 10 orders of magnitude. Deep speckle holography establishes a route toward direct label-free nanoparticle phenotyping in real-world fluids, moving nanoscale measurement beyond isolated-particle characterization toward multidimensional inference in complex mixtures, and expanding the scope of questions nanoscale measurement can address, from real-time tracking of nanoparticle transformations in living and environmental systems to non-invasive quality control of nanomedicine formulations, and beyond.
Don't Act Blindly: Robust GUI Automation via Action-Effect Verification and Self-Correction
Apr 07, 2026Autonomous GUI agents based on vision-language models (VLMs) often assume deterministic environment responses, generating actions without verifying whether previous operations succeeded. In real-world settings with network latency, rendering delays, and system interruptions, this assumption leads to undetected action failures, repetitive ineffective behaviors, and catastrophic error accumulation. Moreover, learning robust recovery strategies is challenging due to the high cost of online interaction and the lack of real-time feedback in offline datasets.We propose VeriGUI (Verification-driven GUI Agent), which explicitly models action outcomes and recovery under noisy environments. VeriGUI introduces a Thinking--Verification--Action--Expectation (TVAE) framework to detect failures and guide corrective reasoning, and a two-stage training pipeline that combines Robust SFT with synthetic failure trajectories and GRPO with asymmetric verification rewards. We further construct a Robustness Benchmark based on AndroidControl to evaluate failure recognition and correction. Experiments show that VeriGUI significantly reduces failure loops and improves recovery success while maintaining competitive standard task performance.
Silo-Bench: A Scalable Environment for Evaluating Distributed Coordination in Multi-Agent LLM Systems
Mar 01, 2026Large language models are increasingly deployed in multi-agent systems to overcome context limitations by distributing information across agents. Yet whether agents can reliably compute with distributed information -- rather than merely exchange it -- remains an open question. We introduce Silo-Bench, a role-agnostic benchmark of 30 algorithmic tasks across three communication complexity levels, evaluating 54 configurations over 1,620 experiments. Our experiments expose a fundamental Communication-Reasoning Gap: agents spontaneously form task-appropriate coordination topologies and exchange information actively, yet systematically fail to synthesize distributed state into correct answers. The failure is localized to the reasoning-integration stage -- agents often acquire sufficient information but cannot integrate it. This coordination overhead compounds with scale, eventually eliminating parallelization gains entirely. These findings demonstrate that naively scaling agent count cannot circumvent context limitations, and Silo-Bench provides a foundation for tracking progress toward genuinely collaborative multi-agent systems.
Text to Query Plans for Question Answering on Large Tables
Aug 26, 2025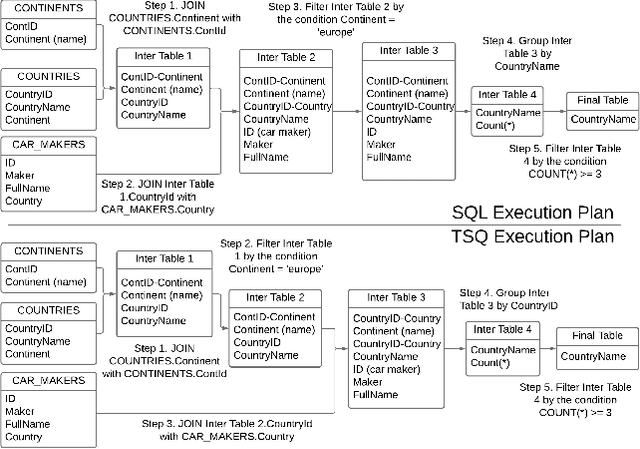

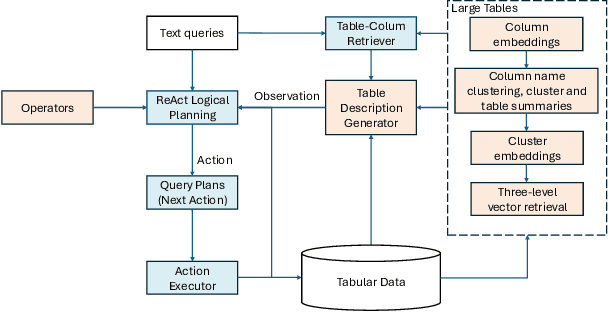

Efficient querying and analysis of large tabular datasets remain significant challenges, especially for users without expertise in programming languages like SQL. Text-to-SQL approaches have shown promising performance on benchmark data; however, they inherit SQL's drawbacks, including inefficiency with large datasets and limited support for complex data analyses beyond basic querying. We propose a novel framework that transforms natural language queries into query plans. Our solution is implemented outside traditional databases, allowing us to support classical SQL commands while avoiding SQL's inherent limitations. Additionally, we enable complex analytical functions, such as principal component analysis and anomaly detection, providing greater flexibility and extensibility than traditional SQL capabilities. We leverage LLMs to iteratively interpret queries and construct operation sequences, addressing computational complexity by incrementally building solutions. By executing operations directly on the data, we overcome context length limitations without requiring the entire dataset to be processed by the model. We validate our framework through experiments on both standard databases and large scientific tables, demonstrating its effectiveness in handling extensive datasets and performing sophisticated data analyses.
Improving Generalization Ability of Robotic Imitation Learning by Resolving Causal Confusion in Observations
Jul 30, 2025Recent developments in imitation learning have considerably advanced robotic manipulation. However, current techniques in imitation learning can suffer from poor generalization, limiting performance even under relatively minor domain shifts. In this work, we aim to enhance the generalization capabilities of complex imitation learning algorithms to handle unpredictable changes from the training environments to deployment environments. To avoid confusion caused by observations that are not relevant to the target task, we propose to explicitly learn the causal relationship between observation components and expert actions, employing a framework similar to [6], where a causal structural function is learned by intervention on the imitation learning policy. Disentangling the feature representation from image input as in [6] is hard to satisfy in complex imitation learning process in robotic manipulation, we theoretically clarify that this requirement is not necessary in causal relationship learning. Therefore, we propose a simple causal structure learning framework that can be easily embedded in recent imitation learning architectures, such as the Action Chunking Transformer [31]. We demonstrate our approach using a simulation of the ALOHA [31] bimanual robot arms in Mujoco, and show that the method can considerably mitigate the generalization problem of existing complex imitation learning algorithms.
The Eye of Sherlock Holmes: Uncovering User Private Attribute Profiling via Vision-Language Model Agentic Framework
May 25, 2025



Our research reveals a new privacy risk associated with the vision-language model (VLM) agentic framework: the ability to infer sensitive attributes (e.g., age and health information) and even abstract ones (e.g., personality and social traits) from a set of personal images, which we term "image private attribute profiling." This threat is particularly severe given that modern apps can easily access users' photo albums, and inference from image sets enables models to exploit inter-image relations for more sophisticated profiling. However, two main challenges hinder our understanding of how well VLMs can profile an individual from a few personal photos: (1) the lack of benchmark datasets with multi-image annotations for private attributes, and (2) the limited ability of current multimodal large language models (MLLMs) to infer abstract attributes from large image collections. In this work, we construct PAPI, the largest dataset for studying private attribute profiling in personal images, comprising 2,510 images from 251 individuals with 3,012 annotated privacy attributes. We also propose HolmesEye, a hybrid agentic framework that combines VLMs and LLMs to enhance privacy inference. HolmesEye uses VLMs to extract both intra-image and inter-image information and LLMs to guide the inference process as well as consolidate the results through forensic analysis, overcoming existing limitations in long-context visual reasoning. Experiments reveal that HolmesEye achieves a 10.8% improvement in average accuracy over state-of-the-art baselines and surpasses human-level performance by 15.0% in predicting abstract attributes. This work highlights the urgency of addressing privacy risks in image-based profiling and offers both a new dataset and an advanced framework to guide future research in this area.
PathGPT: Leveraging Large Language Models for Personalized Route Generation
Apr 08, 2025The proliferation of GPS enabled devices has led to the accumulation of a substantial corpus of historical trajectory data. By leveraging these data for training machine learning models,researchers have devised novel data-driven methodologies that address the personalized route recommendation (PRR) problem. In contrast to conventional algorithms such as Dijkstra shortest path algorithm,these novel algorithms possess the capacity to discern and learn patterns within the data,thereby facilitating the generation of more personalized paths. However,once these models have been trained,their application is constrained to the generation of routes that align with their training patterns. This limitation renders them less adaptable to novel scenarios and the deployment of multiple machine learning models might be necessary to address new possible scenarios,which can be costly as each model must be trained separately. Inspired by recent advances in the field of Large Language Models (LLMs),we leveraged their natural language understanding capabilities to develop a unified model to solve the PRR problem while being seamlessly adaptable to new scenarios without additional training. To accomplish this,we combined the extensive knowledge LLMs acquired during training with further access to external hand-crafted context information,similar to RAG (Retrieved Augmented Generation) systems,to enhance their ability to generate paths according to user-defined requirements. Extensive experiments on different datasets show a considerable uplift in LLM performance on the PRR problem.
Constraint Multi-class Positive and Unlabeled Learning for Distantly Supervised Named Entity Recognition
Apr 07, 2025



Distantly supervised named entity recognition (DS-NER) has been proposed to exploit the automatically labeled training data by external knowledge bases instead of human annotations. However, it tends to suffer from a high false negative rate due to the inherent incompleteness. To address this issue, we present a novel approach called \textbf{C}onstraint \textbf{M}ulti-class \textbf{P}ositive and \textbf{U}nlabeled Learning (CMPU), which introduces a constraint factor on the risk estimator of multiple positive classes. It suggests that the constraint non-negative risk estimator is more robust against overfitting than previous PU learning methods with limited positive data. Solid theoretical analysis on CMPU is provided to prove the validity of our approach. Extensive experiments on two benchmark datasets that were labeled using diverse external knowledge sources serve to demonstrate the superior performance of CMPU in comparison to existing DS-NER methods.