 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlink: Dynamic Visual Token Resolution for Enhanced Multimodal Understanding
Dec 11, 2025Multimodal large language models (MLLMs) have achieved remarkable progress on various vision-language tasks, yet their visual perception remains limited. Humans, in comparison, perceive complex scenes efficiently by dynamically scanning and focusing on salient regions in a sequential "blink-like" process. Motivated by this strategy, we first investigate whether MLLMs exhibit similar behavior. Our pilot analysis reveals that MLLMs naturally attend to different visual regions across layers and that selectively allocating more computation to salient tokens can enhance visual perception. Building on this insight, we propose Blink, a dynamic visual token resolution framework that emulates the human-inspired process within a single forward pass. Specifically, Blink includes two modules: saliency-guided scanning and dynamic token resolution. It first estimates the saliency of visual tokens in each layer based on the attention map, and extends important tokens through a plug-and-play token super-resolution (TokenSR) module. In the next layer, it drops the extended tokens when they lose focus. This dynamic mechanism balances broad exploration and fine-grained focus, thereby enhancing visual perception adaptively and efficiently. Extensive experiments validate Blink, demonstrating its effectiveness in enhancing visual perception and multimodal understanding.
A2R: An Asymmetric Two-Stage Reasoning Framework for Parallel Reasoning
Sep 26, 2025



Recent Large Reasoning Models have achieved significant improvements in complex task-solving capabilities by allocating more computation at the inference stage with a "thinking longer" paradigm. Even as the foundational reasoning capabilities of models advance rapidly, the persistent gap between a model's performance in a single attempt and its latent potential, often revealed only across multiple solution paths, starkly highlights the disparity between its realized and inherent capabilities. To address this, we present A2R, an Asymmetric Two-Stage Reasoning framework designed to explicitly bridge the gap between a model's potential and its actual performance. In this framework, an "explorer" model first generates potential solutions in parallel through repeated sampling. Subsequently,a "synthesizer" model integrates these references for a more refined, second stage of reasoning. This two-stage process allows computation to be scaled orthogonally to existing sequential methods. Our work makes two key innovations: First, we present A2R as a plug-and-play parallel reasoning framework that explicitly enhances a model's capabilities on complex questions. For example, using our framework, the Qwen3-8B-distill model achieves a 75% performance improvement compared to its self-consistency baseline. Second, through a systematic analysis of the explorer and synthesizer roles, we identify an effective asymmetric scaling paradigm. This insight leads to A2R-Efficient, a "small-to-big" variant that combines a Qwen3-4B explorer with a Qwen3-8B synthesizer. This configuration surpasses the average performance of a monolithic Qwen3-32B model at a nearly 30% lower cost. Collectively, these results show that A2R is not only a performance-boosting framework but also an efficient and practical solution for real-world applications.
Weights-Rotated Preference Optimization for Large Language Models
Aug 25, 2025Despite the efficacy of Direct Preference Optimization (DPO) in aligning Large Language Models (LLMs), reward hacking remains a pivotal challenge. This issue emerges when LLMs excessively reduce the probability of rejected completions to achieve high rewards, without genuinely meeting their intended goals. As a result, this leads to overly lengthy generation lacking diversity, as well as catastrophic forgetting of knowledge. We investigate the underlying reason behind this issue, which is representation redundancy caused by neuron collapse in the parameter space. Hence, we propose a novel Weights-Rotated Preference Optimization (RoPO) algorithm, which implicitly constrains the output layer logits with the KL divergence inherited from DPO and explicitly constrains the intermediate hidden states by fine-tuning on a multi-granularity orthogonal matrix. This design prevents the policy model from deviating too far from the reference model, thereby retaining the knowledge and expressive capabilities acquired during pre-training and SFT stages. Our RoPO achieves up to a 3.27-point improvement on AlpacaEval 2, and surpasses the best baseline by 6.2 to 7.5 points on MT-Bench with merely 0.015% of the trainable parameters, demonstrating its effectiveness in alleviating the reward hacking problem of DPO.
Semantic Energy: Detecting LLM Hallucination Beyond Entropy
Aug 20, 2025Large Language Models (LLMs) are being increasingly deployed in real-world applications, but they remain susceptible to hallucinations, which produce fluent yet incorrect responses and lead to erroneous decision-making. Uncertainty estimation is a feasible approach to detect such hallucinations. For example, semantic entropy estimates uncertainty by considering the semantic diversity across multiple sampled responses, thus identifying hallucinations. However, semantic entropy relies on post-softmax probabilities and fails to capture the model's inherent uncertainty, causing it to be ineffective in certain scenarios. To address this issue, we introduce Semantic Energy, a novel uncertainty estimation framework that leverages the inherent confidence of LLMs by operating directly on logits of penultimate layer. By combining semantic clustering with a Boltzmann-inspired energy distribution, our method better captures uncertainty in cases where semantic entropy fails. Experiments across multiple benchmarks show that Semantic Energy significantly improves hallucination detection and uncertainty estimation, offering more reliable signals for downstream applications such as hallucination detection.
BEE-RAG: Balanced Entropy Engineering for Retrieval-Augmented Generation
Aug 07, 2025



With the rapid advancement of large language models (LLMs), retrieval-augmented generation (RAG) has emerged as a critical approach to supplement the inherent knowledge limitations of LLMs. However, due to the typically large volume of retrieved information, RAG tends to operate with long context lengths. From the perspective of entropy engineering, we identify unconstrained entropy growth and attention dilution due to long retrieval context as significant factors affecting RAG performance. In this paper, we propose the balanced entropy-engineered RAG (BEE-RAG) framework, which improves the adaptability of RAG systems to varying context lengths through the principle of entropy invariance. By leveraging balanced context entropy to reformulate attention dynamics, BEE-RAG separates attention sensitivity from context length, ensuring a stable entropy level. Building upon this, we introduce a zero-shot inference strategy for multi-importance estimation and a parameter-efficient adaptive fine-tuning mechanism to obtain the optimal balancing factor for different settings. Extensive experiments across multiple RAG tasks demonstrate the effectiveness of BEE-RAG.
Advantageous Parameter Expansion Training Makes Better Large Language Models
May 30, 2025



Although scaling up the number of trainable parameters in both pre-training and fine-tuning can effectively improve the performance of large language models, it also leads to increased computational overhead. When delving into the parameter difference, we find that a subset of parameters, termed advantageous parameters, plays a crucial role in determining model performance. Further analysis reveals that stronger models tend to possess more such parameters. In this paper, we propose Advantageous Parameter EXpansion Training (APEX), a method that progressively expands advantageous parameters into the space of disadvantageous ones, thereby increasing their proportion and enhancing training effectiveness. Further theoretical analysis from the perspective of matrix effective rank explains the performance gains of APEX. Extensive experiments on both instruction tuning and continued pre-training demonstrate that, in instruction tuning, APEX outperforms full-parameter tuning while using only 52% of the trainable parameters. In continued pre-training, APEX achieves the same perplexity level as conventional training with just 33% of the training data, and yields significant improvements on downstream tasks.
Reinforced Informativeness Optimization for Long-Form Retrieval-Augmented Generation
May 27, 2025Long-form question answering (LFQA) presents unique challenges for large language models, requiring the synthesis of coherent, paragraph-length answers. While retrieval-augmented generation (RAG) systems have emerged as a promising solution, existing research struggles with key limitations: the scarcity of high-quality training data for long-form generation, the compounding risk of hallucination in extended outputs, and the absence of reliable evaluation metrics for factual completeness. In this paper, we propose RioRAG, a novel reinforcement learning (RL) framework that advances long-form RAG through reinforced informativeness optimization. Our approach introduces two fundamental innovations to address the core challenges. First, we develop an RL training paradigm of reinforced informativeness optimization that directly optimizes informativeness and effectively addresses the slow-thinking deficit in conventional RAG systems, bypassing the need for expensive supervised data. Second, we propose a nugget-centric hierarchical reward modeling approach that enables precise assessment of long-form answers through a three-stage process: extracting the nugget from every source webpage, constructing a nugget claim checklist, and computing rewards based on factual alignment. Extensive experiments on two LFQA benchmarks LongFact and RAGChecker demonstrate the effectiveness of the proposed method. Our codes are available at https://github.com/RUCAIBox/RioRAG.
Unveiling Knowledge Utilization Mechanisms in LLM-based Retrieval-Augmented Generation
May 17, 2025
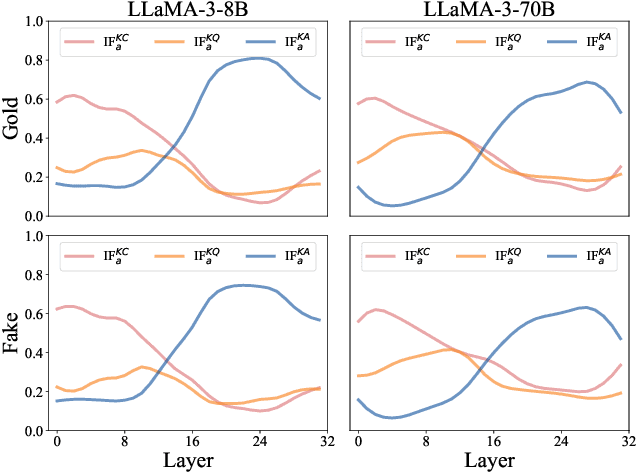
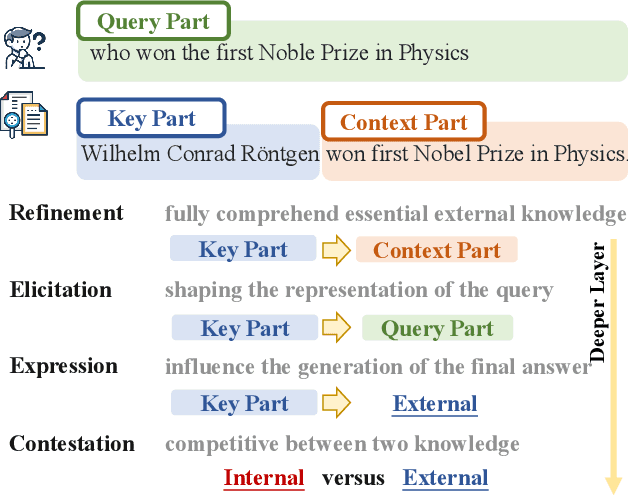
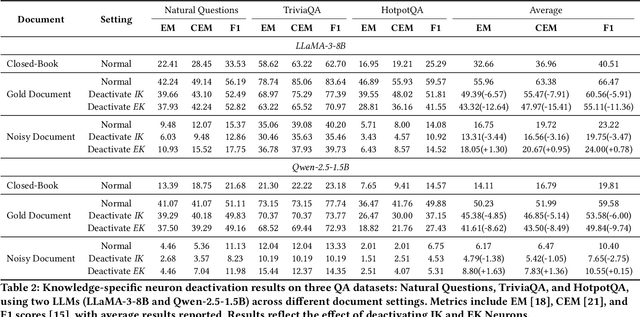
Considering the inherent limitations of parametric knowledge in large language models (LLMs), retrieval-augmented generation (RAG) is widely employed to expand their knowledge scope. Since RAG has shown promise in knowledge-intensive tasks like open-domain question answering, its broader application to complex tasks and intelligent assistants has further advanced its utility. Despite this progress, the underlying knowledge utilization mechanisms of LLM-based RAG remain underexplored. In this paper, we present a systematic investigation of the intrinsic mechanisms by which LLMs integrate internal (parametric) and external (retrieved) knowledge in RAG scenarios. Specially, we employ knowledge stream analysis at the macroscopic level, and investigate the function of individual modules at the microscopic level. Drawing on knowledge streaming analyses, we decompose the knowledge utilization process into four distinct stages within LLM layers: knowledge refinement, knowledge elicitation, knowledge expression, and knowledge contestation. We further demonstrate that the relevance of passages guides the streaming of knowledge through these stages. At the module level, we introduce a new method, knowledge activation probability entropy (KAPE) for neuron identification associated with either internal or external knowledge. By selectively deactivating these neurons, we achieve targeted shifts in the LLM's reliance on one knowledge source over the other. Moreover, we discern complementary roles for multi-head attention and multi-layer perceptron layers during knowledge formation. These insights offer a foundation for improving interpretability and reliability in retrieval-augmented LLMs, paving the way for more robust and transparent generative solutions in knowledge-intensive domains.
Inner Thinking Transformer: Leveraging Dynamic Depth Scaling to Foster Adaptive Internal Thinking
Feb 19, 2025



Large language models (LLMs) face inherent performance bottlenecks under parameter constraints, particularly in processing critical tokens that demand complex reasoning. Empirical analysis reveals challenging tokens induce abrupt gradient spikes across layers, exposing architectural stress points in standard Transformers. Building on this insight, we propose Inner Thinking Transformer (ITT), which reimagines layer computations as implicit thinking steps. ITT dynamically allocates computation through Adaptive Token Routing, iteratively refines representations via Residual Thinking Connections, and distinguishes reasoning phases using Thinking Step Encoding. ITT enables deeper processing of critical tokens without parameter expansion. Evaluations across 162M-466M parameter models show ITT achieves 96.5\% performance of a 466M Transformer using only 162M parameters, reduces training data by 43.2\%, and outperforms Transformer/Loop variants in 11 benchmarks. By enabling elastic computation allocation during inference, ITT balances performance and efficiency through architecture-aware optimization of implicit thinking pathways.
Shall Your Data Strategy Work? Perform a Swift Study
Feb 19, 2025This work presents a swift method to assess the efficacy of particular types of instruction-tuning data, utilizing just a handful of probe examples and eliminating the need for model retraining. This method employs the idea of gradient-based data influence estimation, analyzing the gradient projections of probe examples from the chosen strategy onto evaluation examples to assess its advantages. Building upon this method, we conducted three swift studies to investigate the potential of Chain-of-thought (CoT) data, query clarification data, and response evaluation data in enhancing model generalization. Subsequently, we embarked on a validation study to corroborate the findings of these swift studies. In this validation study, we developed training datasets tailored to each studied strategy and compared model performance with and without the use of these datasets. The results of the validation study aligned with the findings of the swift studies, validating the efficacy of our proposed method.