 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Rubric System: Scaling Reinforcement Learning with Pairwise Adaptive Rubric
Feb 15, 2026Scalar reward models compress multi-dimensional human preferences into a single opaque score, creating an information bottleneck that often leads to brittleness and reward hacking in open-ended alignment. We argue that robust alignment for non-verifiable tasks is fundamentally a principle generalization problem: reward should not be a learned function internalized into a judge, but an explicit reasoning process executed under inspectable principles. To operationalize this view, we present the Open Rubric System (OpenRS), a plug-and-play, rubrics-based LLM-as-a-Judge framework built around Pairwise Adaptive Meta-Rubrics (PAMR) and lightweight Pointwise Verifiable Rubrics (PVRs), which provide both hard-constraint guardrails and verifiable reward components when ground-truth or programmatic checks are available. OpenRS uses an explicit meta-rubric -- a constitution-like specification that governs how rubrics are instantiated, weighted, and enforced -- and instantiates adaptive rubrics on the fly by conditioning on the semantic differences between two candidate responses. It then performs criterion-wise pairwise comparisons and aggregates criterion-level preferences externally, avoiding pointwise weighted scalarization while improving discriminability in open-ended settings. To keep principles consistent yet editable across various domains, we introduce a two-level meta-rubric refinement pipeline (automated evolutionary refinement for general principles and a reproducible human-in-the-loop procedure for domain principles), complemented with pointwise verifiable rubrics that act as both guardrails against degenerate behaviors and a source of verifiable reward for objective sub-tasks. Finally, we instantiate OpenRS as reward supervision in pairwise RL training.
Weights-Rotated Preference Optimization for Large Language Models
Aug 25, 2025Despite the efficacy of Direct Preference Optimization (DPO) in aligning Large Language Models (LLMs), reward hacking remains a pivotal challenge. This issue emerges when LLMs excessively reduce the probability of rejected completions to achieve high rewards, without genuinely meeting their intended goals. As a result, this leads to overly lengthy generation lacking diversity, as well as catastrophic forgetting of knowledge. We investigate the underlying reason behind this issue, which is representation redundancy caused by neuron collapse in the parameter space. Hence, we propose a novel Weights-Rotated Preference Optimization (RoPO) algorithm, which implicitly constrains the output layer logits with the KL divergence inherited from DPO and explicitly constrains the intermediate hidden states by fine-tuning on a multi-granularity orthogonal matrix. This design prevents the policy model from deviating too far from the reference model, thereby retaining the knowledge and expressive capabilities acquired during pre-training and SFT stages. Our RoPO achieves up to a 3.27-point improvement on AlpacaEval 2, and surpasses the best baseline by 6.2 to 7.5 points on MT-Bench with merely 0.015% of the trainable parameters, demonstrating its effectiveness in alleviating the reward hacking problem of DPO.
Neural Label Search for Zero-Shot Multi-Lingual Extractive Summarization
Apr 29, 2022
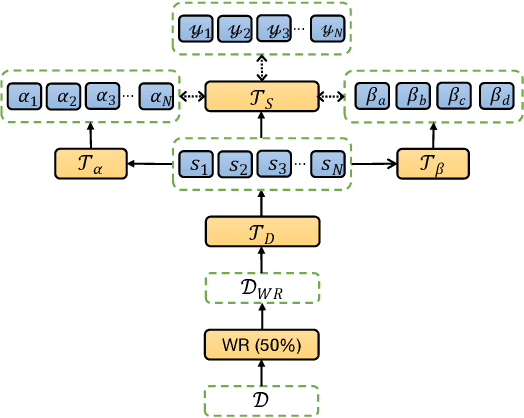
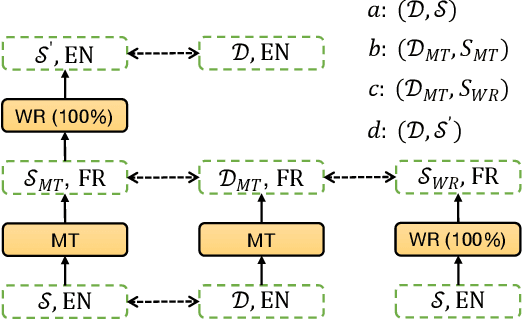
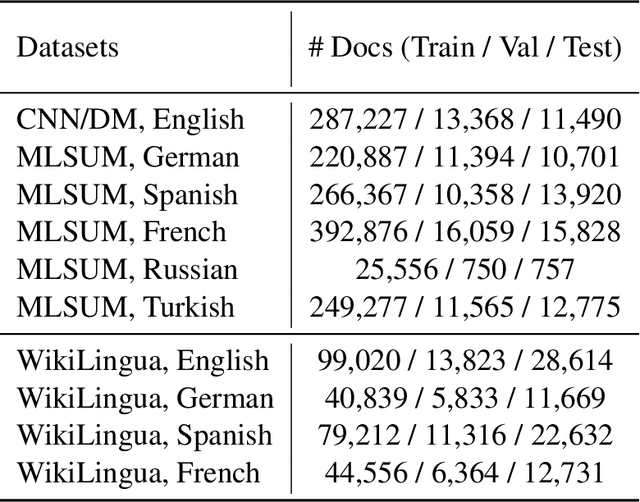
In zero-shot multilingual extractive text summarization, a model is typically trained on English summarization dataset and then applied on summarization datasets of other languages. Given English gold summaries and documents, sentence-level labels for extractive summarization are usually generated using heuristics. However, these monolingual labels created on English datasets may not be optimal on datasets of other languages, for that there is the syntactic or semantic discrepancy between different languages. In this way, it is possible to translate the English dataset to other languages and obtain different sets of labels again using heuristics. To fully leverage the information of these different sets of labels, we propose NLSSum (Neural Label Search for Summarization), which jointly learns hierarchical weights for these different sets of labels together with our summarization model. We conduct multilingual zero-shot summarization experiments on MLSUM and WikiLingua datasets, and we achieve state-of-the-art results using both human and automatic evaluations across these two datasets.