 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Omnimatte: Learning to Decompose Video into Layers
Nov 25, 2024



Given a video and a set of input object masks, an omnimatte method aims to decompose the video into semantically meaningful layers containing individual objects along with their associated effects, such as shadows and reflections. Existing omnimatte methods assume a static background or accurate pose and depth estimation and produce poor decompositions when these assumptions are violated. Furthermore, due to the lack of generative prior on natural videos, existing methods cannot complete dynamic occluded regions. We present a novel generative layered video decomposition framework to address the omnimatte problem. Our method does not assume a stationary scene or require camera pose or depth information and produces clean, complete layers, including convincing completions of occluded dynamic regions. Our core idea is to train a video diffusion model to identify and remove scene effects caused by a specific object. We show that this model can be finetuned from an existing video inpainting model with a small, carefully curated dataset, and demonstrate high-quality decompositions and editing results for a wide range of casually captured videos containing soft shadows, glossy reflections, splashing water, and more.
VidPanos: Generative Panoramic Videos from Casual Panning Videos
Oct 17, 2024



Panoramic image stitching provides a unified, wide-angle view of a scene that extends beyond the camera's field of view. Stitching frames of a panning video into a panoramic photograph is a well-understood problem for stationary scenes, but when objects are moving, a still panorama cannot capture the scene. We present a method for synthesizing a panoramic video from a casually-captured panning video, as if the original video were captured with a wide-angle camera. We pose panorama synthesis as a space-time outpainting problem, where we aim to create a full panoramic video of the same length as the input video. Consistent completion of the space-time volume requires a powerful, realistic prior over video content and motion, for which we adapt generative video models. Existing generative models do not, however, immediately extend to panorama completion, as we show. We instead apply video generation as a component of our panorama synthesis system, and demonstrate how to exploit the strengths of the models while minimizing their limitations. Our system can create video panoramas for a range of in-the-wild scenes including people, vehicles, and flowing water, as well as stationary background features.
ZipLoRA: Any Subject in Any Style by Effectively Merging LoRAs
Nov 22, 2023



Methods for finetuning generative models for concept-driven personalization generally achieve strong results for subject-driven or style-driven generation. Recently, low-rank adaptations (LoRA) have been proposed as a parameter-efficient way of achieving concept-driven personalization. While recent work explores the combination of separate LoRAs to achieve joint generation of learned styles and subjects, existing techniques do not reliably address the problem; they often compromise either subject fidelity or style fidelity. We propose ZipLoRA, a method to cheaply and effectively merge independently trained style and subject LoRAs in order to achieve generation of any user-provided subject in any user-provided style. Experiments on a wide range of subject and style combinations show that ZipLoRA can generate compelling results with meaningful improvements over baselines in subject and style fidelity while preserving the ability to recontextualize. Project page: https://ziplora.github.io
Self-supervised AutoFlow
Dec 08, 2022



Recently, AutoFlow has shown promising results on learning a training set for optical flow, but requires ground truth labels in the target domain to compute its search metric. Observing a strong correlation between the ground truth search metric and self-supervised losses, we introduce self-supervised AutoFlow to handle real-world videos without ground truth labels. Using self-supervised loss as the search metric, our self-supervised AutoFlow performs on par with AutoFlow on Sintel and KITTI where ground truth is available, and performs better on the real-world DAVIS dataset. We further explore using self-supervised AutoFlow in the (semi-)supervised setting and obtain competitive results against the state of the art.
Omnimatte: Associating Objects and Their Effects in Video
May 14, 2021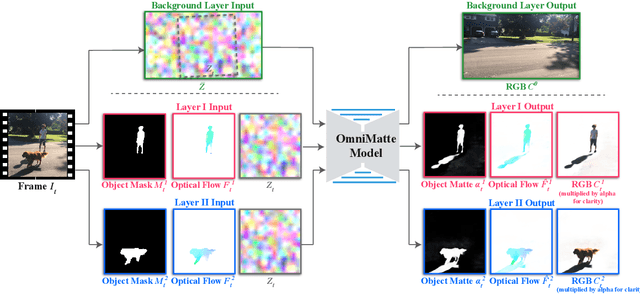



Computer vision is increasingly effective at segmenting objects in images and videos; however, scene effects related to the objects---shadows, reflections, generated smoke, etc---are typically overlooked. Identifying such scene effects and associating them with the objects producing them is important for improving our fundamental understanding of visual scenes, and can also assist a variety of applications such as removing, duplicating, or enhancing objects in video. In this work, we take a step towards solving this novel problem of automatically associating objects with their effects in video. Given an ordinary video and a rough segmentation mask over time of one or more subjects of interest, we estimate an omnimatte for each subject---an alpha matte and color image that includes the subject along with all its related time-varying scene elements. Our model is trained only on the input video in a self-supervised manner, without any manual labels, and is generic---it produces omnimattes automatically for arbitrary objects and a variety of effects. We show results on real-world videos containing interactions between different types of subjects (cars, animals, people) and complex effects, ranging from semi-transparent elements such as smoke and reflections, to fully opaque effects such as objects attached to the subject.
Self-supervised Video Object Segmentation by Motion Grouping
Apr 15, 2021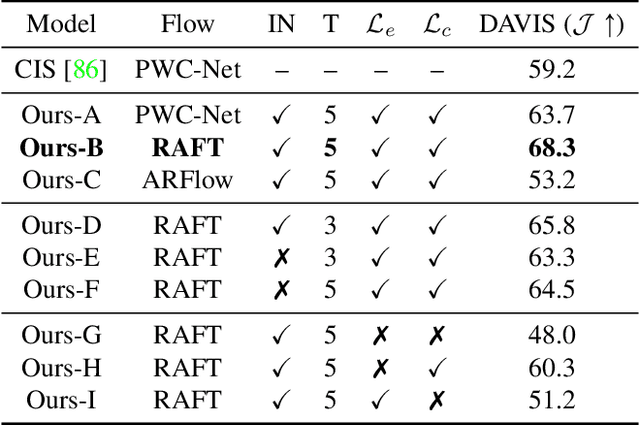
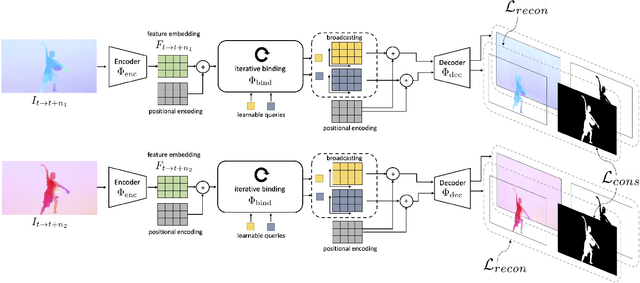
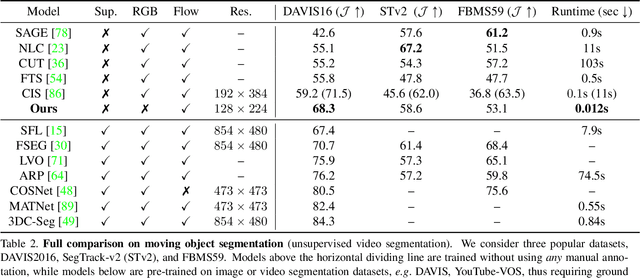
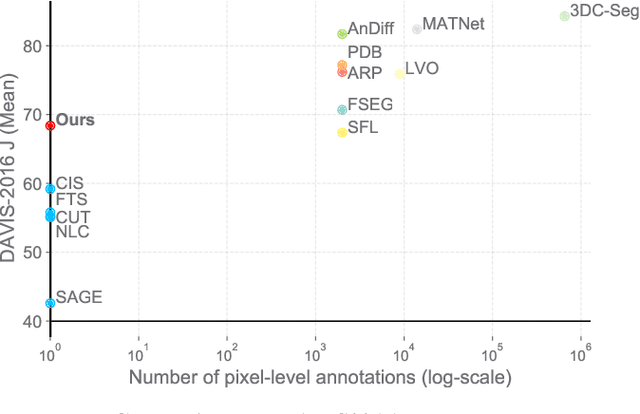
Animals have evolved highly functional visual systems to understand motion, assisting perception even under complex environments. In this paper, we work towards developing a computer vision system able to segment objects by exploiting motion cues, i.e. motion segmentation. We make the following contributions: First, we introduce a simple variant of the Transformer to segment optical flow frames into primary objects and the background. Second, we train the architecture in a self-supervised manner, i.e. without using any manual annotations. Third, we analyze several critical components of our method and conduct thorough ablation studies to validate their necessity. Fourth, we evaluate the proposed architecture on public benchmarks (DAVIS2016, SegTrackv2, and FBMS59). Despite using only optical flow as input, our approach achieves superior or comparable results to previous state-of-the-art self-supervised methods, while being an order of magnitude faster. We additionally evaluate on a challenging camouflage dataset (MoCA), significantly outperforming the other self-supervised approaches, and comparing favourably to the top supervised approach, highlighting the importance of motion cues, and the potential bias towards visual appearance in existing video segmentation models.
On the Origin of Species of Self-Supervised Learning
Mar 31, 2021

In the quiet backwaters of cs.CV, cs.LG and stat.ML, a cornucopia of new learning systems is emerging from a primordial soup of mathematics-learning systems with no need for external supervision. To date, little thought has been given to how these self-supervised learners have sprung into being or the principles that govern their continuing diversification. After a period of deliberate study and dispassionate judgement during which each author set their Zoom virtual background to a separate Galapagos island, we now entertain no doubt that each of these learning machines are lineal descendants of some older and generally extinct species. We make five contributions: (1) We gather and catalogue row-major arrays of machine learning specimens, each exhibiting heritable discriminative features; (2) We document a mutation mechanism by which almost imperceptible changes are introduced to the genotype of new systems, but their phenotype (birdsong in the form of tweets and vestigial plumage such as press releases) communicates dramatic changes; (3) We propose a unifying theory of self-supervised machine evolution and compare to other unifying theories on standard unifying theory benchmarks, where we establish a new (and unifying) state of the art; (4) We discuss the importance of digital biodiversity, in light of the endearingly optimistic Paris Agreement.
Layered Neural Rendering for Retiming People in Video
Sep 16, 2020
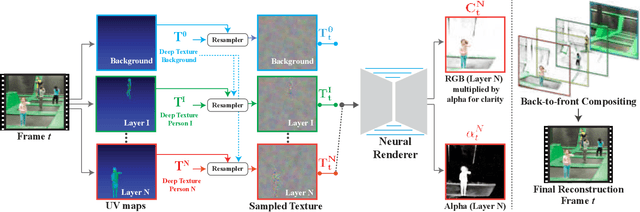

We present a method for retiming people in an ordinary, natural video---manipulating and editing the time in which different motions of individuals in the video occur. We can temporally align different motions, change the speed of certain actions (speeding up/slowing down, or entirely "freezing" people), or "erase" selected people from the video altogether. We achieve these effects computationally via a dedicated learning-based layered video representation, where each frame in the video is decomposed into separate RGBA layers, representing the appearance of different people in the video. A key property of our model is that it not only disentangles the direct motions of each person in the input video, but also correlates each person automatically with the scene changes they generate---e.g., shadows, reflections, and motion of loose clothing. The layers can be individually retimed and recombined into a new video, allowing us to achieve realistic, high-quality renderings of retiming effects for real-world videos depicting complex actions and involving multiple individuals, including dancing, trampoline jumping, or group running.
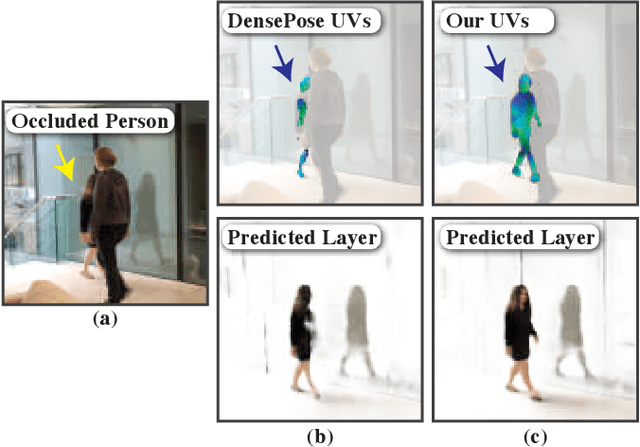
MAST: A Memory-Augmented Self-supervised Tracker
Feb 26, 2020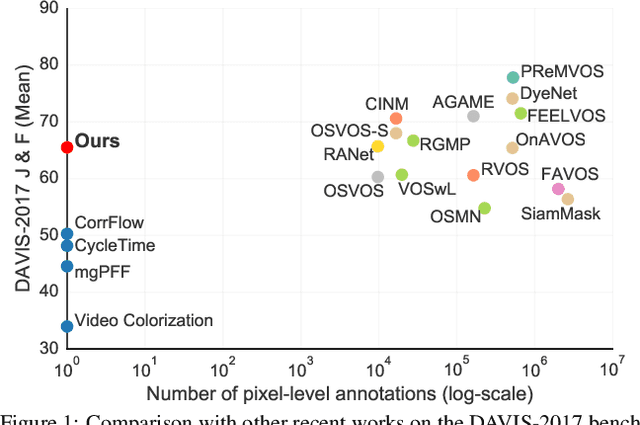
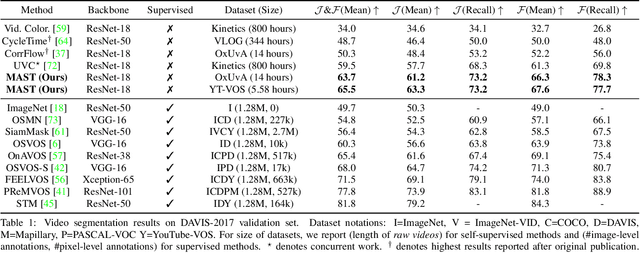

Recent interest in self-supervised dense tracking has yielded rapid progress, but performance still remains far from supervised methods. We propose a dense tracking model trained on videos without any annotations that surpasses previous self-supervised methods on existing benchmarks by a significant margin (+15%), and achieves performance comparable to supervised methods. In this paper, we first reassess the traditional choices used for self-supervised training and reconstruction loss by conducting thorough experiments that finally elucidate the optimal choices. Second, we further improve on existing methods by augmenting our architecture with a crucial memory component. Third, we benchmark on large-scale semi-supervised video object segmentation(aka. dense tracking), and propose a new metric: generalizability. Our first two contributions yield a self-supervised network that for the first time is competitive with supervised methods on standard evaluation metrics of dense tracking. When measuring generalizability, we show self-supervised approaches are actually superior to the majority of supervised methods. We believe this new generalizability metric can better capture the real-world use-cases for dense tracking, and will spur new interest in this research direction.
Class-Agnostic Counting
Nov 01, 2018
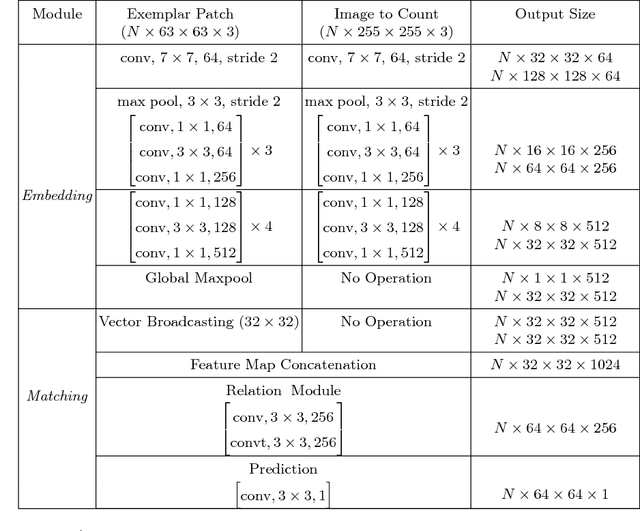
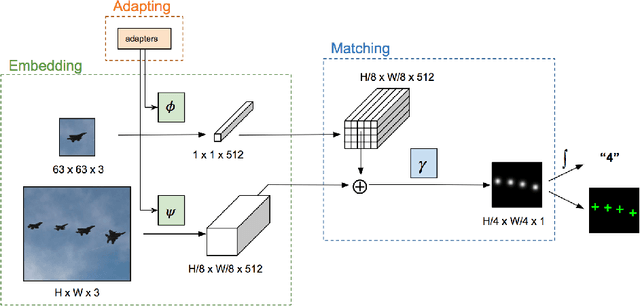
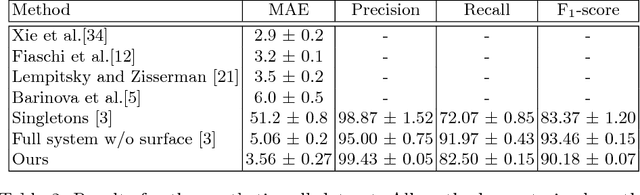
Nearly all existing counting methods are designed for a specific object class. Our work, however, aims to create a counting model able to count any class of object. To achieve this goal, we formulate counting as a matching problem, enabling us to exploit the image self-similarity property that naturally exists in object counting problems. We make the following three contributions: first, a Generic Matching Network (GMN) architecture that can potentially count any object in a class-agnostic manner; second, by reformulating the counting problem as one of matching objects, we can take advantage of the abundance of video data labeled for tracking, which contains natural repetitions suitable for training a counting model. Such data enables us to train the GMN. Third, to customize the GMN to different user requirements, an adapter module is used to specialize the model with minimal effort, i.e. using a few labeled examples, and adapting only a small fraction of the trained parameters. This is a form of few-shot learning, which is practical for domains where labels are limited due to requiring expert knowledge (e.g. microbiology). We demonstrate the flexibility of our method on a diverse set of existing counting benchmarks: specifically cells, cars, and human crowds. The model achieves competitive performance on cell and crowd counting datasets, and surpasses the state-of-the-art on the car dataset using only three training images. When training on the entire dataset, the proposed method outperforms all previous methods by a large margin.