 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMining Attribute Subspaces for Efficient Fine-tuning of 3D Foundation Models
Apr 11, 2026With the emergence of 3D foundation models, there is growing interest in fine-tuning them for downstream tasks, where LoRA is the dominant fine-tuning paradigm. As 3D datasets exhibit distinct variations in texture, geometry, camera motion, and lighting, there are interesting fundamental questions: 1) Are there LoRA subspaces associated with each type of variation? 2) Are these subspaces disentangled (i.e., orthogonal to each other)? 3) How do we compute them effectively? This paper provides answers to all these questions. We introduce a robust approach that generates synthetic datasets with controlled variations, fine-tunes a LoRA adapter on each dataset, and extracts a LoRA sub-space associated with each type of variation. We show that these subspaces are approximately disentangled. Integrating them leads to a reduced LoRA subspace that enables efficient LoRA fine-tuning with improved prediction accuracy for downstream tasks. In particular, we show that such a reduced LoRA subspace, despite being derived entirely from synthetic data, generalizes to real datasets. An ablation study validates the effectiveness of the choices in our approach.
Differences That Matter: Auditing Models for Capability Gap Discovery and Rectification
Dec 18, 2025



Conventional evaluation methods for multimodal LLMs (MLLMs) lack interpretability and are often insufficient to fully disclose significant capability gaps across models. To address this, we introduce AuditDM, an automated framework that actively discovers and rectifies MLLM failure modes by auditing their divergence. AuditDM fine-tunes an MLLM as an auditor via reinforcement learning to generate challenging questions and counterfactual images that maximize disagreement among target models. Once trained, the auditor uncovers diverse, interpretable exemplars that reveal model weaknesses and serve as annotation-free data for rectification. When applied to SoTA models like Gemma-3 and PaliGemma-2, AuditDM discovers more than 20 distinct failure types. Fine-tuning on these discoveries consistently improves all models across 16 benchmarks, and enables a 3B model to surpass its 28B counterpart. Our results suggest that as data scaling hits diminishing returns, targeted model auditing offers an effective path to model diagnosis and improvement.
Mull-Tokens: Modality-Agnostic Latent Thinking
Dec 11, 2025



Reasoning goes beyond language; the real world requires reasoning about space, time, affordances, and much more that words alone cannot convey. Existing multimodal models exploring the potential of reasoning with images are brittle and do not scale. They rely on calling specialist tools, costly generation of images, or handcrafted reasoning data to switch between text and image thoughts. Instead, we offer a simpler alternative -- Mull-Tokens -- modality-agnostic latent tokens pre-trained to hold intermediate information in either image or text modalities to let the model think free-form towards the correct answer. We investigate best practices to train Mull-Tokens inspired by latent reasoning frameworks. We first train Mull-Tokens using supervision from interleaved text-image traces, and then fine-tune without any supervision by only using the final answers. Across four challenging spatial reasoning benchmarks involving tasks such as solving puzzles and taking different perspectives, we demonstrate that Mull-Tokens improve upon several baselines utilizing text-only reasoning or interleaved image-text reasoning, achieving a +3% average improvement and up to +16% on a puzzle solving reasoning-heavy split compared to our strongest baseline. Adding to conversations around challenges in grounding textual and visual reasoning, Mull-Tokens offers a simple solution to abstractly think in multiple modalities.
SEAL: Semantic Attention Learning for Long Video Representation
Dec 02, 2024Long video understanding presents challenges due to the inherent high computational complexity and redundant temporal information. An effective representation for long videos must process such redundancy efficiently while preserving essential contents for downstream tasks. This paper introduces SEmantic Attention Learning (SEAL), a novel unified representation for long videos. To reduce computational complexity, long videos are decomposed into three distinct types of semantic entities: scenes, objects, and actions, allowing models to operate on a handful of entities rather than a large number of frames or pixels. To further address redundancy, we propose an attention learning module that balances token relevance with diversity formulated as a subset selection optimization problem. Our representation is versatile, enabling applications across various long video understanding tasks. Extensive experiments show that SEAL significantly outperforms state-of-the-art methods in video question answering and temporal grounding tasks and benchmarks including LVBench, MovieChat-1K, and Ego4D.
Semantic Image Inversion and Editing using Rectified Stochastic Differential Equations
Oct 14, 2024



Generative models transform random noise into images; their inversion aims to transform images back to structured noise for recovery and editing. This paper addresses two key tasks: (i) inversion and (ii) editing of a real image using stochastic equivalents of rectified flow models (such as Flux). Although Diffusion Models (DMs) have recently dominated the field of generative modeling for images, their inversion presents faithfulness and editability challenges due to nonlinearities in drift and diffusion. Existing state-of-the-art DM inversion approaches rely on training of additional parameters or test-time optimization of latent variables; both are expensive in practice. Rectified Flows (RFs) offer a promising alternative to diffusion models, yet their inversion has been underexplored. We propose RF inversion using dynamic optimal control derived via a linear quadratic regulator. We prove that the resulting vector field is equivalent to a rectified stochastic differential equation. Additionally, we extend our framework to design a stochastic sampler for Flux. Our inversion method allows for state-of-the-art performance in zero-shot inversion and editing, outperforming prior works in stroke-to-image synthesis and semantic image editing, with large-scale human evaluations confirming user preference.
RB-Modulation: Training-Free Personalization of Diffusion Models using Stochastic Optimal Control
May 27, 2024



We propose Reference-Based Modulation (RB-Modulation), a new plug-and-play solution for training-free personalization of diffusion models. Existing training-free approaches exhibit difficulties in (a) style extraction from reference images in the absence of additional style or content text descriptions, (b) unwanted content leakage from reference style images, and (c) effective composition of style and content. RB-Modulation is built on a novel stochastic optimal controller where a style descriptor encodes the desired attributes through a terminal cost. The resulting drift not only overcomes the difficulties above, but also ensures high fidelity to the reference style and adheres to the given text prompt. We also introduce a cross-attention-based feature aggregation scheme that allows RB-Modulation to decouple content and style from the reference image. With theoretical justification and empirical evidence, our framework demonstrates precise extraction and control of content and style in a training-free manner. Further, our method allows a seamless composition of content and style, which marks a departure from the dependency on external adapters or ControlNets.
Beyond First-Order Tweedie: Solving Inverse Problems using Latent Diffusion
Dec 01, 2023



Sampling from the posterior distribution poses a major computational challenge in solving inverse problems using latent diffusion models. Common methods rely on Tweedie's first-order moments, which are known to induce a quality-limiting bias. Existing second-order approximations are impractical due to prohibitive computational costs, making standard reverse diffusion processes intractable for posterior sampling. This paper introduces Second-order Tweedie sampler from Surrogate Loss (STSL), a novel sampler that offers efficiency comparable to first-order Tweedie with a tractable reverse process using second-order approximation. Our theoretical results reveal that the second-order approximation is lower bounded by our surrogate loss that only requires $O(1)$ compute using the trace of the Hessian, and by the lower bound we derive a new drift term to make the reverse process tractable. Our method surpasses SoTA solvers PSLD and P2L, achieving 4X and 8X reduction in neural function evaluations, respectively, while notably enhancing sampling quality on FFHQ, ImageNet, and COCO benchmarks. In addition, we show STSL extends to text-guided image editing and addresses residual distortions present from corrupted images in leading text-guided image editing methods. To our best knowledge, this is the first work to offer an efficient second-order approximation in solving inverse problems using latent diffusion and editing real-world images with corruptions.
Distributionally Robust Post-hoc Classifiers under Prior Shifts
Sep 16, 2023



The generalization ability of machine learning models degrades significantly when the test distribution shifts away from the training distribution. We investigate the problem of training models that are robust to shifts caused by changes in the distribution of class-priors or group-priors. The presence of skewed training priors can often lead to the models overfitting to spurious features. Unlike existing methods, which optimize for either the worst or the average performance over classes or groups, our work is motivated by the need for finer control over the robustness properties of the model. We present an extremely lightweight post-hoc approach that performs scaling adjustments to predictions from a pre-trained model, with the goal of minimizing a distributionally robust loss around a chosen target distribution. These adjustments are computed by solving a constrained optimization problem on a validation set and applied to the model during test time. Our constrained optimization objective is inspired by a natural notion of robustness to controlled distribution shifts. Our method comes with provable guarantees and empirically makes a strong case for distributional robust post-hoc classifiers. An empirical implementation is available at https://github.com/weijiaheng/Drops.
Rethinking Domain Generalization for Face Anti-spoofing: Separability and Alignment
Mar 23, 2023This work studies the generalization issue of face anti-spoofing (FAS) models on domain gaps, such as image resolution, blurriness and sensor variations. Most prior works regard domain-specific signals as a negative impact, and apply metric learning or adversarial losses to remove them from feature representation. Though learning a domain-invariant feature space is viable for the training data, we show that the feature shift still exists in an unseen test domain, which backfires on the generalizability of the classifier. In this work, instead of constructing a domain-invariant feature space, we encourage domain separability while aligning the live-to-spoof transition (i.e., the trajectory from live to spoof) to be the same for all domains. We formulate this FAS strategy of separability and alignment (SA-FAS) as a problem of invariant risk minimization (IRM), and learn domain-variant feature representation but domain-invariant classifier. We demonstrate the effectiveness of SA-FAS on challenging cross-domain FAS datasets and establish state-of-the-art performance.
Adaptive Transformers for Robust Few-shot Cross-domain Face Anti-spoofing
Mar 23, 2022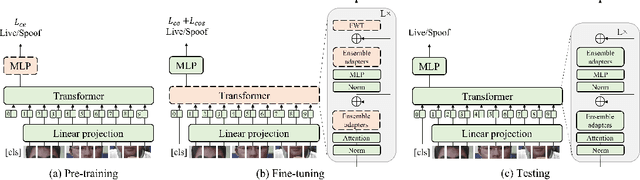
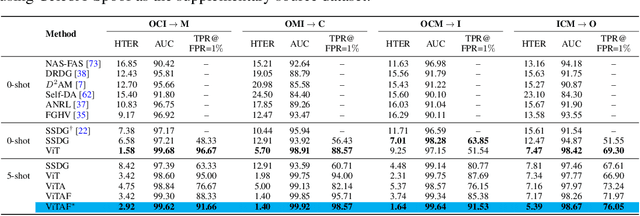
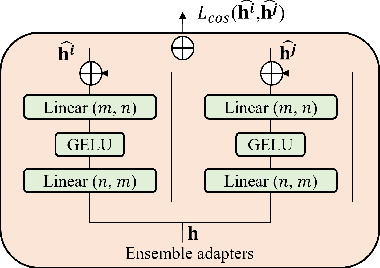
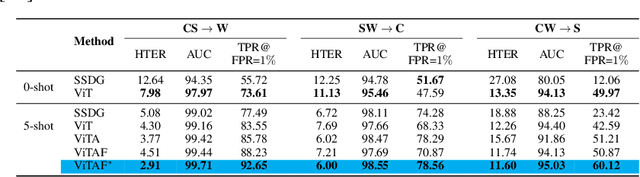
While recent face anti-spoofing methods perform well under the intra-domain setups, an effective approach needs to account for much larger appearance variations of images acquired in complex scenes with different sensors for robust performance. In this paper, we present adaptive vision transformers (ViT) for robust cross-domain face anti-spoofing. Specifically, we adopt ViT as a backbone to exploit its strength to account for long-range dependencies among pixels. We further introduce the ensemble adapters module and feature-wise transformation layers in the ViT to adapt to different domains for robust performance with a few samples. Experiments on several benchmark datasets show that the proposed models achieve both robust and competitive performance against the state-of-the-art methods.