 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClick-through Rate Prediction with Auto-Quantized Contrastive Learning
Sep 27, 2021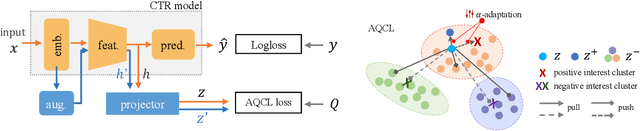
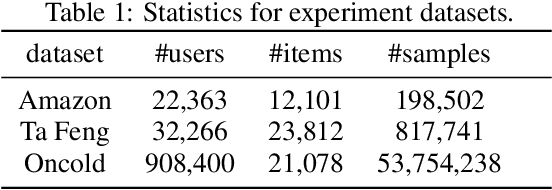
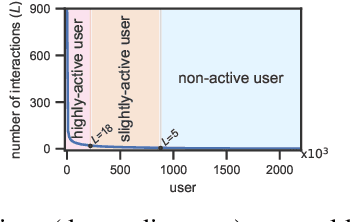
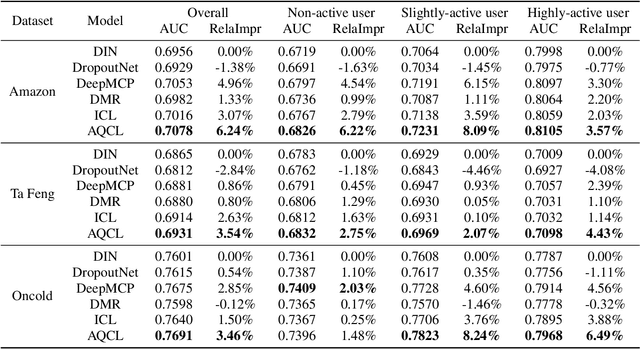
Click-through rate (CTR) prediction becomes indispensable in ubiquitous web recommendation applications. Nevertheless, the current methods are struggling under the cold-start scenarios where the user interactions are extremely sparse. We consider this problem as an automatic identification about whether the user behaviors are rich enough to capture the interests for prediction, and propose an Auto-Quantized Contrastive Learning (AQCL) loss to regularize the model. Different from previous methods, AQCL explores both the instance-instance and the instance-cluster similarity to robustify the latent representation, and automatically reduces the information loss to the active users due to the quantization. The proposed framework is agnostic to different model architectures and can be trained in an end-to-end fashion. Extensive results show that it consistently improves the current state-of-the-art CTR models.
Dynamic Sequential Graph Learning for Click-Through Rate Prediction
Sep 26, 2021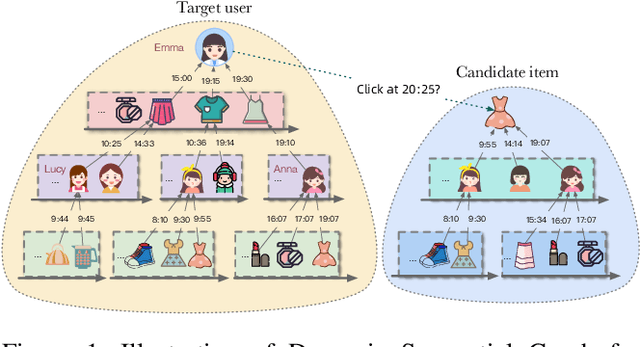
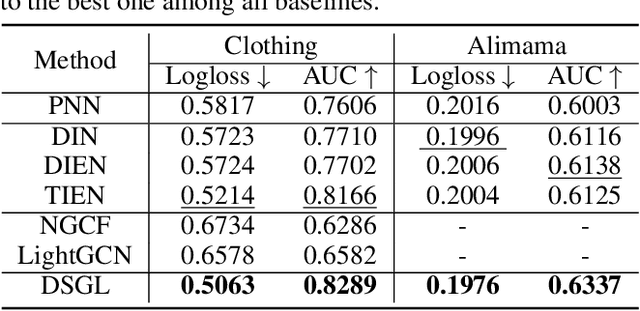
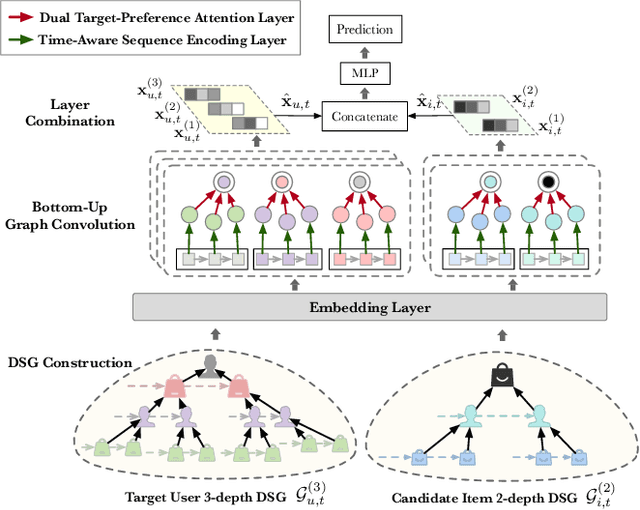
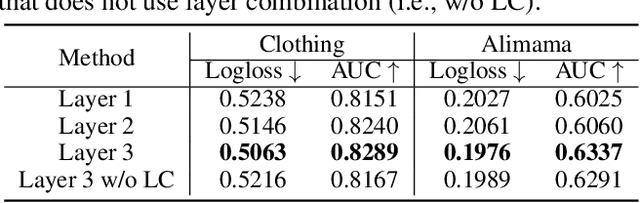
Click-through rate prediction plays an important role in the field of recommender system and many other applications. Existing methods mainly extract user interests from user historical behaviors. However, behavioral sequences only contain users' directly interacted items, which are limited by the system's exposure, thus they are often not rich enough to reflect all the potential interests. In this paper, we propose a novel method, named Dynamic Sequential Graph Learning (DSGL), to enhance users or items' representations by utilizing collaborative information from the local sub-graphs associated with users or items. Specifically, we design the Dynamic Sequential Graph (DSG), i.e., a lightweight ego subgraph with timestamps induced from historical interactions. At every scoring moment, we construct DSGs for the target user and the candidate item respectively. Based on the DSGs, we perform graph convolutional operations iteratively in a bottom-up manner to obtain the final representations of the target user and the candidate item. As for the graph convolution, we design a Time-aware Sequential Encoding Layer that leverages the interaction time information as well as temporal dependencies to learn evolutionary user and item dynamics. Besides, we propose a Target-Preference Dual Attention Layer, composed of a preference-aware attention module and a target-aware attention module, to automatically search for parts of behaviors that are relevant to the target and alleviate the noise from unreliable neighbors. Results on real-world CTR prediction benchmarks demonstrate the improvements brought by DSGL.
MC$^2$-SF: Slow-Fast Learning for Mobile-Cloud Collaborative Recommendation
Sep 25, 2021
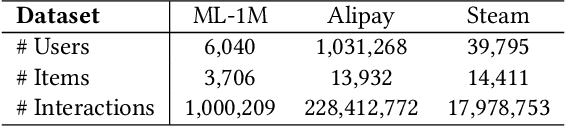
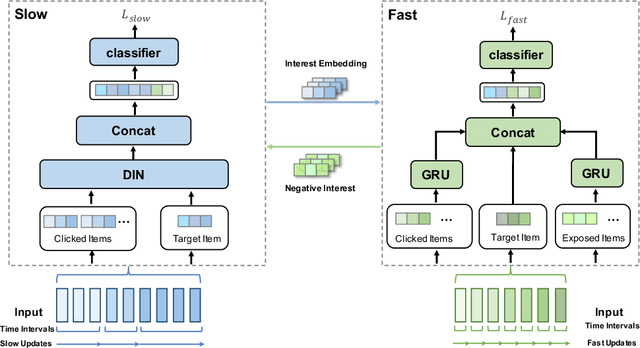
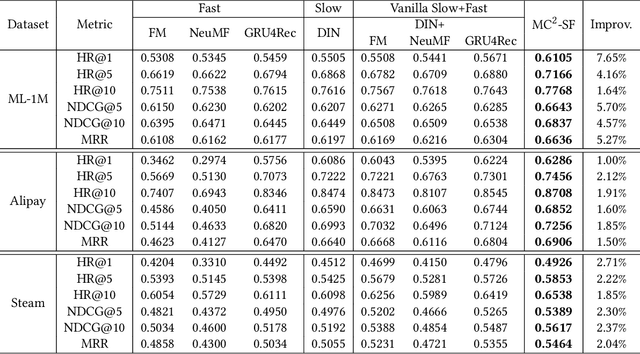
With the hardware development of mobile devices, it is possible to build the recommendation models on the mobile side to utilize the fine-grained features and the real-time feedbacks. Compared to the straightforward mobile-based modeling appended to the cloud-based modeling, we propose a Slow-Fast learning mechanism to make the Mobile-Cloud Collaborative recommendation (MC$^2$-SF) mutual benefit. Specially, in our MC$^2$-SF, the cloud-based model and the mobile-based model are respectively treated as the slow component and the fast component, according to their interaction frequency in real-world scenarios. During training and serving, they will communicate the prior/privileged knowledge to each other to help better capture the user interests about the candidates, resembling the role of System I and System II in the human cognition. We conduct the extensive experiments on three benchmark datasets and demonstrate the proposed MC$^2$-SF outperforms several state-of-the-art methods.
Reinforcement Learning to Optimize Lifetime Value in Cold-Start Recommendation
Aug 20, 2021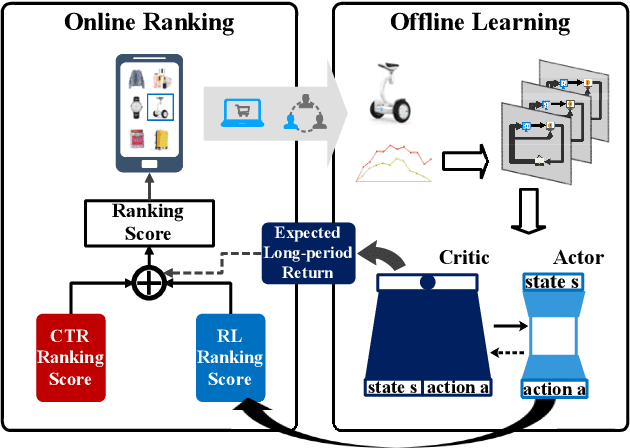
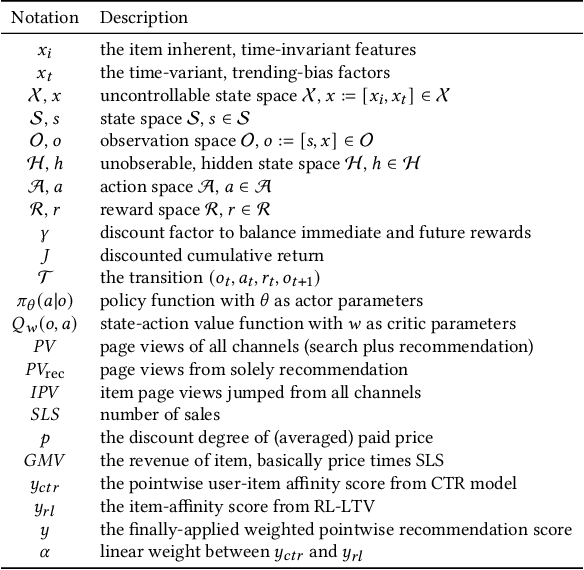
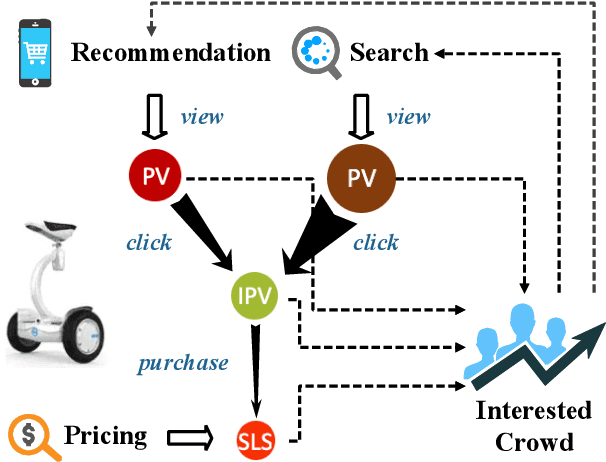
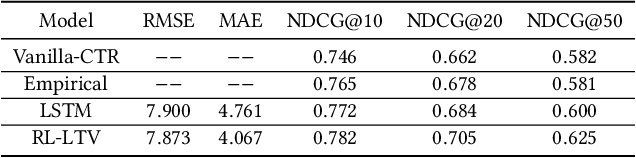
Recommender system plays a crucial role in modern E-commerce platform. Due to the lack of historical interactions between users and items, cold-start recommendation is a challenging problem. In order to alleviate the cold-start issue, most existing methods introduce content and contextual information as the auxiliary information. Nevertheless, these methods assume the recommended items behave steadily over time, while in a typical E-commerce scenario, items generally have very different performances throughout their life period. In such a situation, it would be beneficial to consider the long-term return from the item perspective, which is usually ignored in conventional methods. Reinforcement learning (RL) naturally fits such a long-term optimization problem, in which the recommender could identify high potential items, proactively allocate more user impressions to boost their growth, therefore improve the multi-period cumulative gains. Inspired by this idea, we model the process as a Partially Observable and Controllable Markov Decision Process (POC-MDP), and propose an actor-critic RL framework (RL-LTV) to incorporate the item lifetime values (LTV) into the recommendation. In RL-LTV, the critic studies historical trajectories of items and predict the future LTV of fresh item, while the actor suggests a score-based policy which maximizes the future LTV expectation. Scores suggested by the actor are then combined with classical ranking scores in a dual-rank framework, therefore the recommendation is balanced with the LTV consideration. Our method outperforms the strong live baseline with a relative improvement of 8.67% and 18.03% on IPV and GMV of cold-start items, on one of the largest E-commerce platform.
Exploring Sparse Expert Models and Beyond
Jun 14, 2021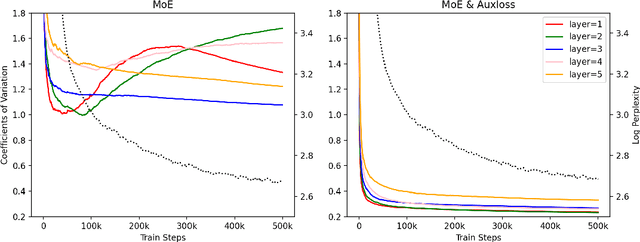

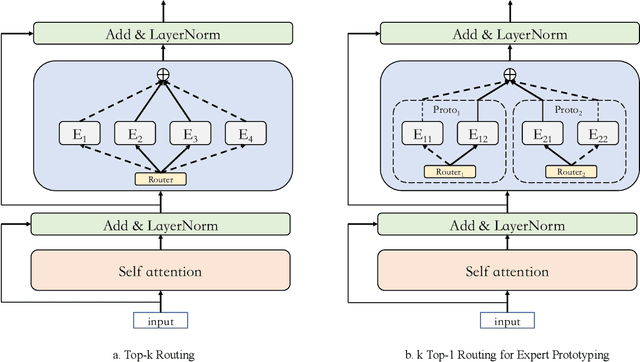
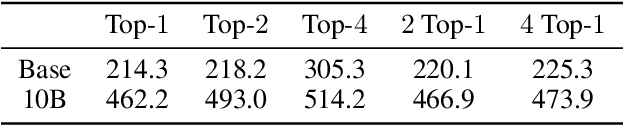
Mixture-of-Experts (MoE) models can achieve promising results with outrageous large amount of parameters but constant computation cost, and thus it has become a trend in model scaling. Still it is a mystery how MoE layers bring quality gains by leveraging the parameters with sparse activation. In this work, we investigate several key factors in sparse expert models. We observe that load imbalance may not be a significant problem affecting model quality, contrary to the perspectives of recent studies, while the number of sparsely activated experts $k$ and expert capacity $C$ in top-$k$ routing can significantly make a difference in this context. Furthermore, we take a step forward to propose a simple method called expert prototyping that splits experts into different prototypes and applies $k$ top-$1$ routing. This strategy improves the model quality but maintains constant computational costs, and our further exploration on extremely large-scale models reflects that it is more effective in training larger models. We push the model scale to over $1$ trillion parameters and implement it on solely $480$ NVIDIA V100-32GB GPUs, in comparison with the recent SOTAs on $2048$ TPU cores. The proposed giant model achieves substantial speedup in convergence over the same-size baseline.
Reliable Adversarial Distillation with Unreliable Teachers
Jun 09, 2021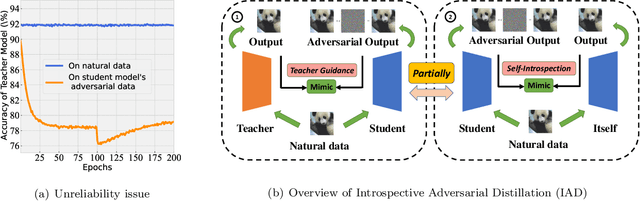
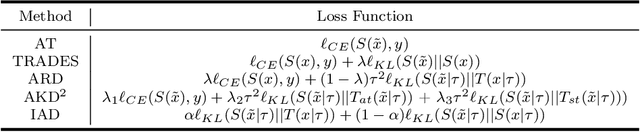
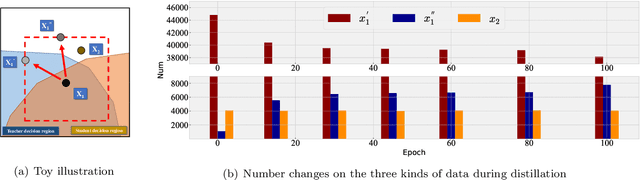
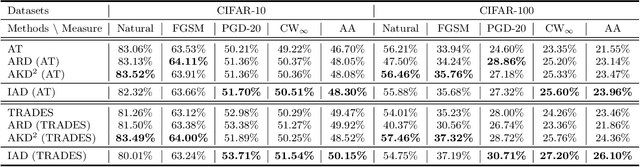
In ordinary distillation, student networks are trained with soft labels (SLs) given by pretrained teacher networks, and students are expected to improve upon teachers since SLs are stronger supervision than the original hard labels. However, when considering adversarial robustness, teachers may become unreliable and adversarial distillation may not work: teachers are pretrained on their own adversarial data, and it is too demanding to require that teachers are also good at every adversarial data queried by students. Therefore, in this paper, we propose reliable introspective adversarial distillation (IAD) where students partially instead of fully trust their teachers. Specifically, IAD distinguishes between three cases given a query of a natural data (ND) and the corresponding adversarial data (AD): (a) if a teacher is good at AD, its SL is fully trusted; (b) if a teacher is good at ND but not AD, its SL is partially trusted and the student also takes its own SL into account; (c) otherwise, the student only relies on its own SL. Experiments demonstrate the effectiveness of IAD for improving upon teachers in terms of adversarial robustness.
Learning to Rehearse in Long Sequence Memorization
Jun 02, 2021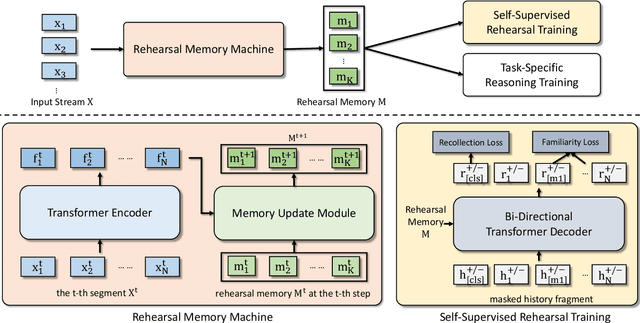
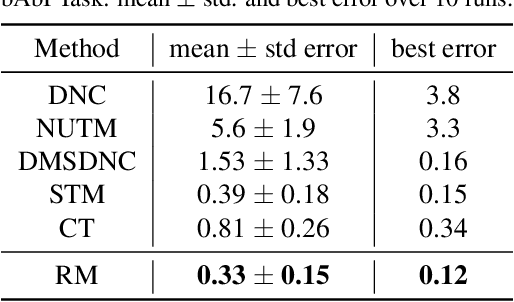
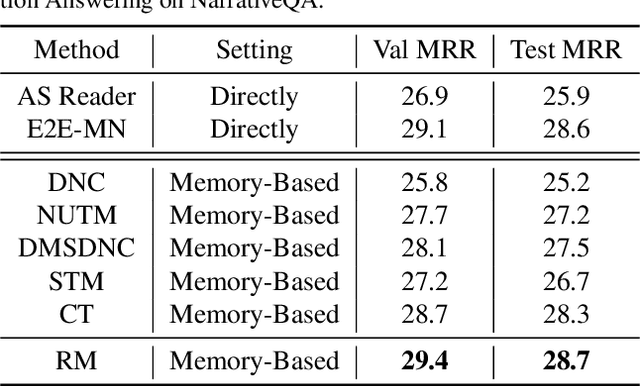
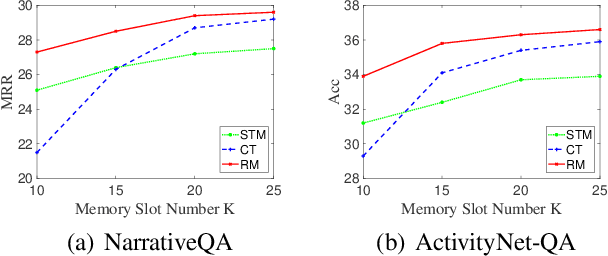
Existing reasoning tasks often have an important assumption that the input contents can be always accessed while reasoning, requiring unlimited storage resources and suffering from severe time delay on long sequences. To achieve efficient reasoning on long sequences with limited storage resources, memory augmented neural networks introduce a human-like write-read memory to compress and memorize the long input sequence in one pass, trying to answer subsequent queries only based on the memory. But they have two serious drawbacks: 1) they continually update the memory from current information and inevitably forget the early contents; 2) they do not distinguish what information is important and treat all contents equally. In this paper, we propose the Rehearsal Memory (RM) to enhance long-sequence memorization by self-supervised rehearsal with a history sampler. To alleviate the gradual forgetting of early information, we design self-supervised rehearsal training with recollection and familiarity tasks. Further, we design a history sampler to select informative fragments for rehearsal training, making the memory focus on the crucial information. We evaluate the performance of our rehearsal memory by the synthetic bAbI task and several downstream tasks, including text/video question answering and recommendation on long sequences.
Learning Relation Alignment for Calibrated Cross-modal Retrieval
Jun 01, 2021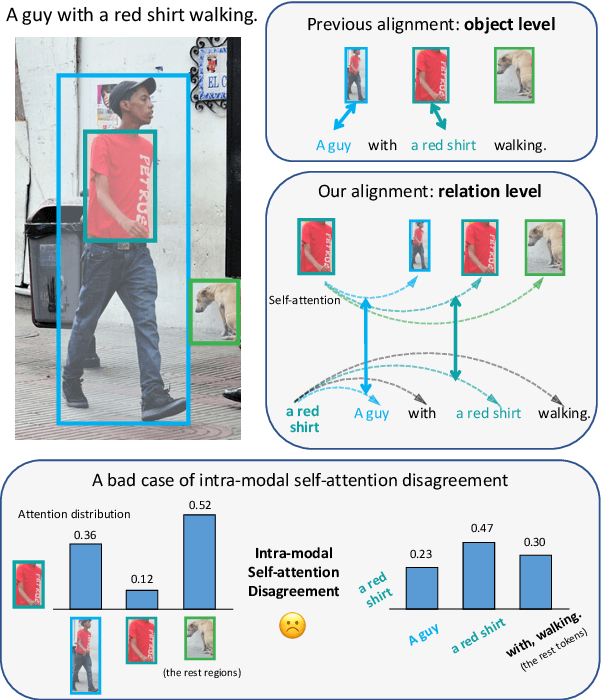
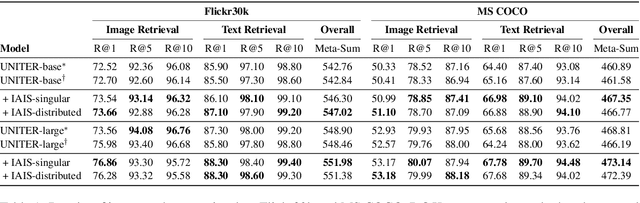
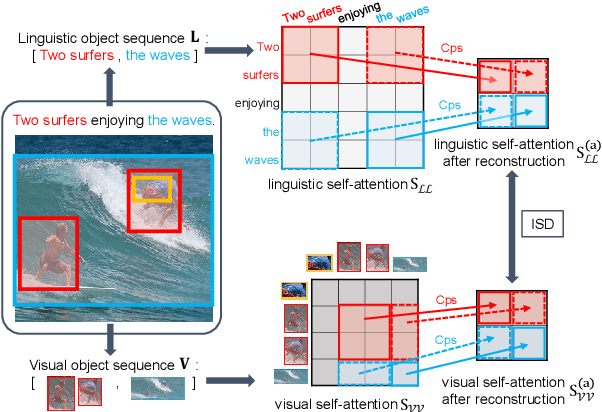
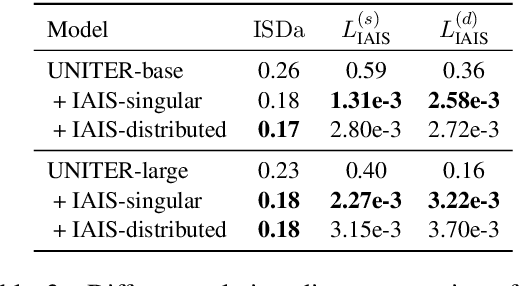
Despite the achievements of large-scale multimodal pre-training approaches, cross-modal retrieval, e.g., image-text retrieval, remains a challenging task. To bridge the semantic gap between the two modalities, previous studies mainly focus on word-region alignment at the object level, lacking the matching between the linguistic relation among the words and the visual relation among the regions. The neglect of such relation consistency impairs the contextualized representation of image-text pairs and hinders the model performance and the interpretability. In this paper, we first propose a novel metric, Intra-modal Self-attention Distance (ISD), to quantify the relation consistency by measuring the semantic distance between linguistic and visual relations. In response, we present Inter-modal Alignment on Intra-modal Self-attentions (IAIS), a regularized training method to optimize the ISD and calibrate intra-modal self-attentions from the two modalities mutually via inter-modal alignment. The IAIS regularizer boosts the performance of prevailing models on Flickr30k and MS COCO datasets by a considerable margin, which demonstrates the superiority of our approach.
Controllable Gradient Item Retrieval
May 31, 2021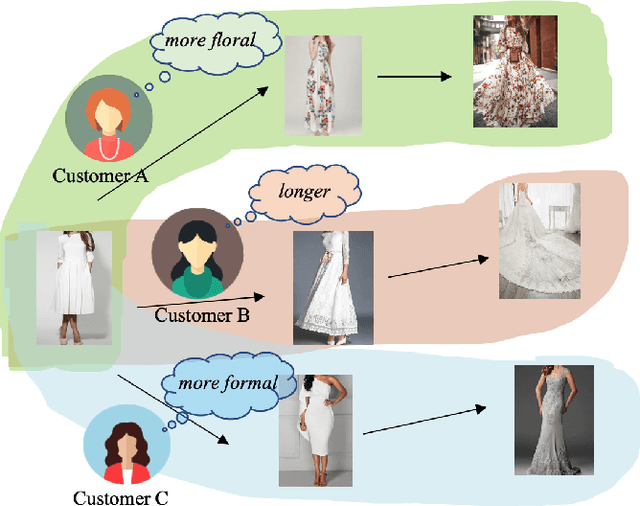

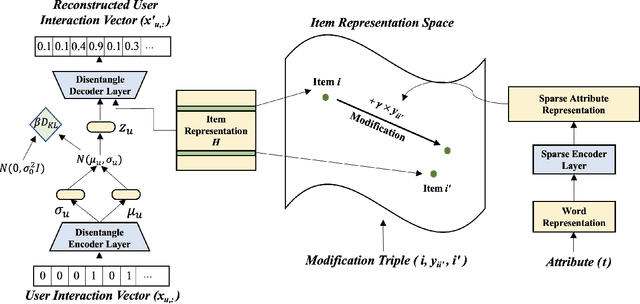
In this paper, we identify and study an important problem of gradient item retrieval. We define the problem as retrieving a sequence of items with a gradual change on a certain attribute, given a reference item and a modification text. For example, after a customer saw a white dress, she/he wants to buy a similar one but more floral on it. The extent of "more floral" is subjective, thus prompting one floral dress is hard to satisfy the customer's needs. A better way is to present a sequence of products with increasingly floral attributes based on the white dress, and allow the customer to select the most satisfactory one from the sequence. Existing item retrieval methods mainly focus on whether the target items appear at the top of the retrieved sequence, but ignore the demand for retrieving a sequence of products with gradual change on a certain attribute. To deal with this problem, we propose a weakly-supervised method that can learn a disentangled item representation from user-item interaction data and ground the semantic meaning of attributes to dimensions of the item representation. Our method takes a reference item and a modification as a query. During inference, we start from the reference item and "walk" along the direction of the modification in the item representation space to retrieve a sequence of items in a gradient manner. We demonstrate our proposed method can achieve disentanglement through weak supervision. Besides, we empirically show that an item sequence retrieved by our method is gradually changed on an indicated attribute and, in the item retrieval task, our method outperforms existing approaches on three different datasets.
Connecting Language and Vision for Natural Language-Based Vehicle Retrieval
May 31, 2021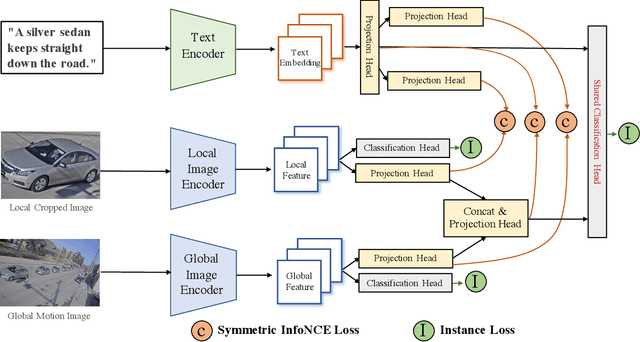
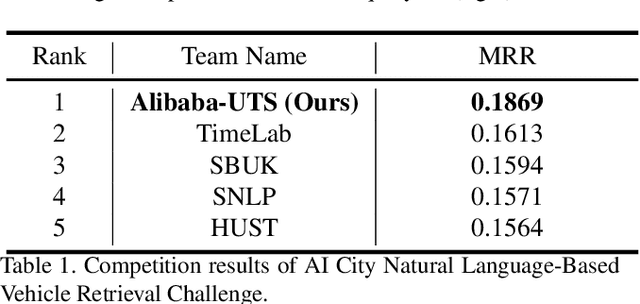
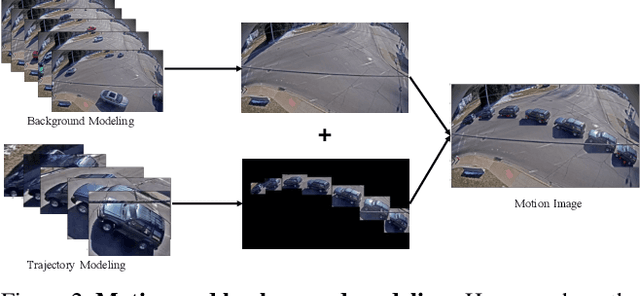
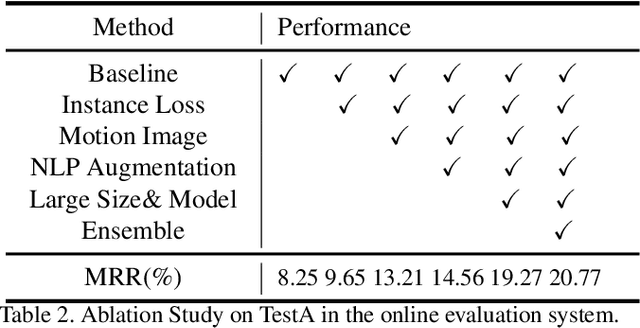
Vehicle search is one basic task for the efficient traffic management in terms of the AI City. Most existing practices focus on the image-based vehicle matching, including vehicle re-identification and vehicle tracking. In this paper, we apply one new modality, i.e., the language description, to search the vehicle of interest and explore the potential of this task in the real-world scenario. The natural language-based vehicle search poses one new challenge of fine-grained understanding of both vision and language modalities. To connect language and vision, we propose to jointly train the state-of-the-art vision models with the transformer-based language model in an end-to-end manner. Except for the network structure design and the training strategy, several optimization objectives are also re-visited in this work. The qualitative and quantitative experiments verify the effectiveness of the proposed method. Our proposed method has achieved the 1st place on the 5th AI City Challenge, yielding competitive performance 18.69% MRR accuracy on the private test set. We hope this work can pave the way for the future study on using language description effectively and efficiently for real-world vehicle retrieval systems. The code will be available at https://github.com/ShuaiBai623/AIC2021-T5-CLV.