 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSongCreator: Lyrics-based Universal Song Generation
Sep 09, 2024



Music is an integral part of human culture, embodying human intelligence and creativity, of which songs compose an essential part. While various aspects of song generation have been explored by previous works, such as singing voice, vocal composition and instrumental arrangement, etc., generating songs with both vocals and accompaniment given lyrics remains a significant challenge, hindering the application of music generation models in the real world. In this light, we propose SongCreator, a song-generation system designed to tackle this challenge. The model features two novel designs: a meticulously designed dual-sequence language model (DSLM) to capture the information of vocals and accompaniment for song generation, and an additional attention mask strategy for DSLM, which allows our model to understand, generate and edit songs, making it suitable for various song-related generation tasks. Extensive experiments demonstrate the effectiveness of SongCreator by achieving state-of-the-art or competitive performances on all eight tasks. Notably, it surpasses previous works by a large margin in lyrics-to-song and lyrics-to-vocals. Additionally, it is able to independently control the acoustic conditions of the vocals and accompaniment in the generated song through different prompts, exhibiting its potential applicability. Our samples are available at https://songcreator.github.io/.
SoCodec: A Semantic-Ordered Multi-Stream Speech Codec for Efficient Language Model Based Text-to-Speech Synthesis
Sep 02, 2024



The long speech sequence has been troubling language models (LM) based TTS approaches in terms of modeling complexity and efficiency. This work proposes SoCodec, a semantic-ordered multi-stream speech codec, to address this issue. It compresses speech into a shorter, multi-stream discrete semantic sequence with multiple tokens at each frame. Meanwhile, the ordered product quantization is proposed to constrain this sequence into an ordered representation. It can be applied with a multi-stream delayed LM to achieve better autoregressive generation along both time and stream axes in TTS. The experimental result strongly demonstrates the effectiveness of the proposed approach, achieving superior performance over baseline systems even if compressing the frameshift of speech from 20ms to 240ms (12x). The ablation studies further validate the importance of learning the proposed ordered multi-stream semantic representation in pursuing shorter speech sequences for efficient LM-based TTS.
Spontaneous Style Text-to-Speech Synthesis with Controllable Spontaneous Behaviors Based on Language Models
Jul 18, 2024



Spontaneous style speech synthesis, which aims to generate human-like speech, often encounters challenges due to the scarcity of high-quality data and limitations in model capabilities. Recent language model-based TTS systems can be trained on large, diverse, and low-quality speech datasets, resulting in highly natural synthesized speech. However, they are limited by the difficulty of simulating various spontaneous behaviors and capturing prosody variations in spontaneous speech. In this paper, we propose a novel spontaneous speech synthesis system based on language models. We systematically categorize and uniformly model diverse spontaneous behaviors. Moreover, fine-grained prosody modeling is introduced to enhance the model's ability to capture subtle prosody variations in spontaneous speech.Experimental results show that our proposed method significantly outperforms the baseline methods in terms of prosody naturalness and spontaneous behavior naturalness.
Large Language Model-based FMRI Encoding of Language Functions for Subjects with Neurocognitive Disorder
Jul 15, 2024Functional magnetic resonance imaging (fMRI) is essential for developing encoding models that identify functional changes in language-related brain areas of individuals with Neurocognitive Disorders (NCD). While large language model (LLM)-based fMRI encoding has shown promise, existing studies predominantly focus on healthy, young adults, overlooking older NCD populations and cognitive level correlations. This paper explores language-related functional changes in older NCD adults using LLM-based fMRI encoding and brain scores, addressing current limitations. We analyze the correlation between brain scores and cognitive scores at both whole-brain and language-related ROI levels. Our findings reveal that higher cognitive abilities correspond to better brain scores, with correlations peaking in the middle temporal gyrus. This study highlights the potential of fMRI encoding models and brain scores for detecting early functional changes in NCD patients.
Empowering Whisper as a Joint Multi-Talker and Target-Talker Speech Recognition System
Jul 13, 2024Multi-talker speech recognition and target-talker speech recognition, both involve transcription in multi-talker contexts, remain significant challenges. However, existing methods rarely attempt to simultaneously address both tasks. In this study, we propose a pioneering approach to empower Whisper, which is a speech foundation model, to tackle joint multi-talker and target-talker speech recognition tasks. Specifically, (i) we freeze Whisper and plug a Sidecar separator into its encoder to separate mixed embedding for multiple talkers; (ii) a Target Talker Identifier is introduced to identify the embedding flow of the target talker on the fly, requiring only three-second enrollment speech as a cue; (iii) soft prompt tuning for decoder is explored for better task adaptation. Our method outperforms previous methods on two- and three-talker LibriMix and LibriSpeechMix datasets for both tasks, and delivers acceptable zero-shot performance on multi-talker ASR on AishellMix Mandarin dataset.
Autoregressive Speech Synthesis without Vector Quantization
Jul 11, 2024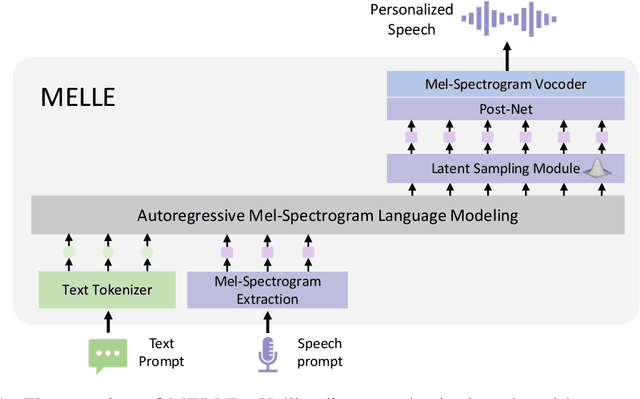



We present MELLE, a novel continuous-valued tokens based language modeling approach for text to speech synthesis (TTS). MELLE autoregressively generates continuous mel-spectrogram frames directly from text condition, bypassing the need for vector quantization, which are originally designed for audio compression and sacrifice fidelity compared to mel-spectrograms. Specifically, (i) instead of cross-entropy loss, we apply regression loss with a proposed spectrogram flux loss function to model the probability distribution of the continuous-valued tokens. (ii) we have incorporated variational inference into MELLE to facilitate sampling mechanisms, thereby enhancing the output diversity and model robustness. Experiments demonstrate that, compared to the two-stage codec language models VALL-E and its variants, the single-stage MELLE mitigates robustness issues by avoiding the inherent flaws of sampling discrete codes, achieves superior performance across multiple metrics, and, most importantly, offers a more streamlined paradigm. See https://aka.ms/melle for demos of our work.
Homogeneous Speaker Features for On-the-Fly Dysarthric and Elderly Speaker Adaptation
Jul 08, 2024



The application of data-intensive automatic speech recognition (ASR) technologies to dysarthric and elderly adult speech is confronted by their mismatch against healthy and nonaged voices, data scarcity and large speaker-level variability. To this end, this paper proposes two novel data-efficient methods to learn homogeneous dysarthric and elderly speaker-level features for rapid, on-the-fly test-time adaptation of DNN/TDNN and Conformer ASR models. These include: 1) speaker-level variance-regularized spectral basis embedding (VR-SBE) features that exploit a special regularization term to enforce homogeneity of speaker features in adaptation; and 2) feature-based learning hidden unit contributions (f-LHUC) transforms that are conditioned on VR-SBE features. Experiments are conducted on four tasks across two languages: the English UASpeech and TORGO dysarthric speech datasets, the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech corpora. The proposed on-the-fly speaker adaptation techniques consistently outperform baseline iVector and xVector adaptation by statistically significant word or character error rate reductions up to 5.32% absolute (18.57% relative) and batch-mode LHUC speaker adaptation by 2.24% absolute (9.20% relative), while operating with real-time factors speeding up to 33.6 times against xVectors during adaptation. The efficacy of the proposed adaptation techniques is demonstrated in a comparison against current ASR technologies including SSL pre-trained systems on UASpeech, where our best system produces a state-of-the-art WER of 23.33%. Analyses show VR-SBE features and f-LHUC transforms are insensitive to speaker-level data quantity in testtime adaptation. T-SNE visualization reveals they have stronger speaker-level homogeneity than baseline iVectors, xVectors and batch-mode LHUC transforms.
Purple-teaming LLMs with Adversarial Defender Training
Jul 01, 2024Existing efforts in safeguarding LLMs are limited in actively exposing the vulnerabilities of the target LLM and readily adapting to newly emerging safety risks. To address this, we present Purple-teaming LLMs with Adversarial Defender training (PAD), a pipeline designed to safeguard LLMs by novelly incorporating the red-teaming (attack) and blue-teaming (safety training) techniques. In PAD, we automatically collect conversational data that cover the vulnerabilities of an LLM around specific safety risks in a self-play manner, where the attacker aims to elicit unsafe responses and the defender generates safe responses to these attacks. We then update both modules in a generative adversarial network style by training the attacker to elicit more unsafe responses and updating the defender to identify them and explain the unsafe reason. Experimental results demonstrate that PAD significantly outperforms existing baselines in both finding effective attacks and establishing a robust safe guardrail. Furthermore, our findings indicate that PAD excels in striking a balance between safety and overall model quality. We also reveal key challenges in safeguarding LLMs, including defending multi-turn attacks and the need for more delicate strategies to identify specific risks.
Seamless Language Expansion: Enhancing Multilingual Mastery in Self-Supervised Models
Jun 20, 2024Self-supervised (SSL) models have shown great performance in various downstream tasks. However, they are typically developed for limited languages, and may encounter new languages in real-world. Developing a SSL model for each new language is costly. Thus, it is vital to figure out how to efficiently adapt existed SSL models to a new language without impairing its original abilities. We propose adaptation methods which integrate LoRA to existed SSL models to extend new language. We also develop preservation strategies which include data combination and re-clustering to retain abilities on existed languages. Applied to mHuBERT, we investigate their effectiveness on speech re-synthesis task. Experiments show that our adaptation methods enable mHuBERT to be applied to a new language (Mandarin) with MOS value increased about 1.6 and the relative value of WER reduced up to 61.72%. Also, our preservation strategies ensure that the performance on both existed and new languages remains intact.
Adaptive Query Rewriting: Aligning Rewriters through Marginal Probability of Conversational Answers
Jun 16, 2024Query rewriting is a crucial technique for passage retrieval in open-domain conversational question answering (CQA). It decontexualizes conversational queries into self-contained questions suitable for off-the-shelf retrievers. Existing methods attempt to incorporate retriever's preference during the training of rewriting models. However, these approaches typically rely on extensive annotations such as in-domain rewrites and/or relevant passage labels, limiting the models' generalization and adaptation capabilities. In this paper, we introduce AdaQR ($\textbf{Ada}$ptive $\textbf{Q}$uery $\textbf{R}$ewriting), a framework for training query rewriting models with limited rewrite annotations from seed datasets and completely no passage label. Our approach begins by fine-tuning compact large language models using only ~$10\%$ of rewrite annotations from the seed dataset training split. The models are then utilized to generate rewrite candidates for each query instance. A novel approach is then proposed to assess retriever's preference for these candidates by the probability of answers conditioned on the conversational query by marginalizing the Top-$K$ passages. This serves as the reward for optimizing the rewriter further using Direct Preference Optimization (DPO), a process free of rewrite and retrieval annotations. Experimental results on four open-domain CQA datasets demonstrate that AdaQR not only enhances the in-domain capabilities of the rewriter with limited annotation requirement, but also adapts effectively to out-of-domain datasets.