 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Zero-shot Generalization and Robustness of Multi-modal Models
Dec 04, 2022



Multi-modal image-text models such as CLIP and LiT have demonstrated impressive performance on image classification benchmarks and their zero-shot generalization ability is particularly exciting. While the top-5 zero-shot accuracies of these models are very high, the top-1 accuracies are much lower (over 25% gap in some cases). We investigate the reasons for this performance gap and find that many of the failure cases are caused by ambiguity in the text prompts. First, we develop a simple and efficient zero-shot post-hoc method to identify images whose top-1 prediction is likely to be incorrect, by measuring consistency of the predictions w.r.t. multiple prompts and image transformations. We show that our procedure better predicts mistakes, outperforming the popular max logit baseline on selective prediction tasks. Next, we propose a simple and efficient way to improve accuracy on such uncertain images by making use of the WordNet hierarchy; specifically we augment the original class by incorporating its parent and children from the semantic label hierarchy, and plug the augmentation into text promts. We conduct experiments on both CLIP and LiT models with five different ImageNet-based datasets. For CLIP, our method improves the top-1 accuracy by 17.13% on the uncertain subset and 3.6% on the entire ImageNet validation set. We also show that our method improves across ImageNet shifted datasets and other model architectures such as LiT. Our proposed method is hyperparameter-free, requires no additional model training and can be easily scaled to other large multi-modal architectures.
MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models
Oct 04, 2022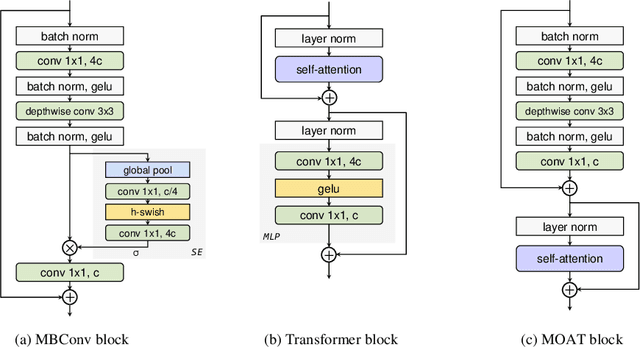

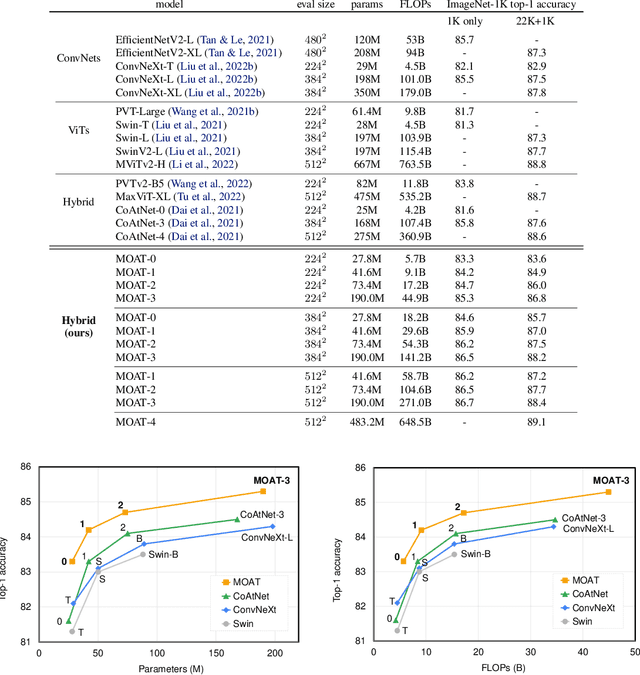
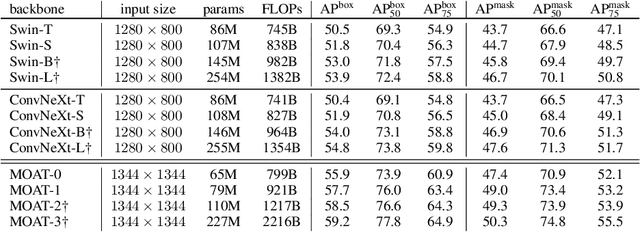
This paper presents MOAT, a family of neural networks that build on top of MObile convolution (i.e., inverted residual blocks) and ATtention. Unlike the current works that stack separate mobile convolution and transformer blocks, we effectively merge them into a MOAT block. Starting with a standard Transformer block, we replace its multi-layer perceptron with a mobile convolution block, and further reorder it before the self-attention operation. The mobile convolution block not only enhances the network representation capacity, but also produces better downsampled features. Our conceptually simple MOAT networks are surprisingly effective, achieving 89.1% top-1 accuracy on ImageNet-1K with ImageNet-22K pretraining. Additionally, MOAT can be seamlessly applied to downstream tasks that require large resolution inputs by simply converting the global attention to window attention. Thanks to the mobile convolution that effectively exchanges local information between pixels (and thus cross-windows), MOAT does not need the extra window-shifting mechanism. As a result, on COCO object detection, MOAT achieves 59.2% box AP with 227M model parameters (single-scale inference, and hard NMS), and on ADE20K semantic segmentation, MOAT attains 57.6% mIoU with 496M model parameters (single-scale inference). Finally, the tiny-MOAT family, obtained by simply reducing the channel sizes, also surprisingly outperforms several mobile-specific transformer-based models on ImageNet. We hope our simple yet effective MOAT will inspire more seamless integration of convolution and self-attention. Code is made publicly available.
Exploring Fine-Grained Audiovisual Categorization with the SSW60 Dataset
Jul 21, 2022
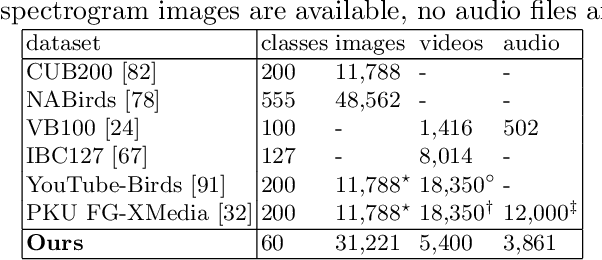
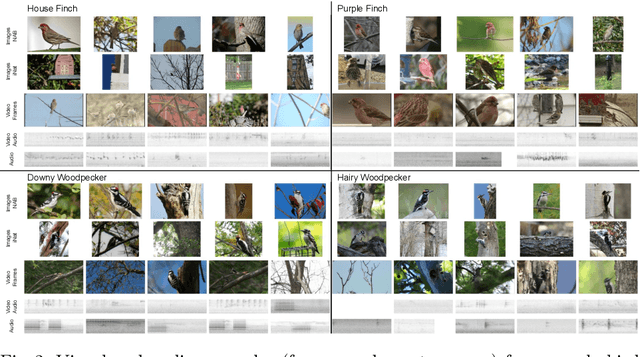
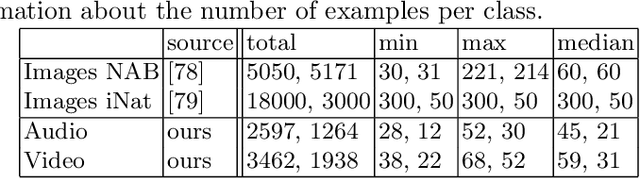
We present a new benchmark dataset, Sapsucker Woods 60 (SSW60), for advancing research on audiovisual fine-grained categorization. While our community has made great strides in fine-grained visual categorization on images, the counterparts in audio and video fine-grained categorization are relatively unexplored. To encourage advancements in this space, we have carefully constructed the SSW60 dataset to enable researchers to experiment with classifying the same set of categories in three different modalities: images, audio, and video. The dataset covers 60 species of birds and is comprised of images from existing datasets, and brand new, expert-curated audio and video datasets. We thoroughly benchmark audiovisual classification performance and modality fusion experiments through the use of state-of-the-art transformer methods. Our findings show that performance of audiovisual fusion methods is better than using exclusively image or audio based methods for the task of video classification. We also present interesting modality transfer experiments, enabled by the unique construction of SSW60 to encompass three different modalities. We hope the SSW60 dataset and accompanying baselines spur research in this fascinating area.
CMT-DeepLab: Clustering Mask Transformers for Panoptic Segmentation
Jun 17, 2022
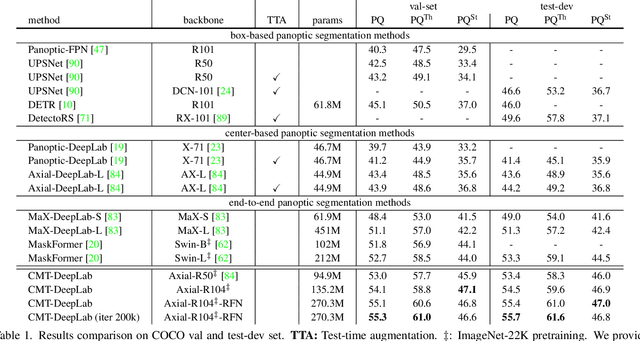
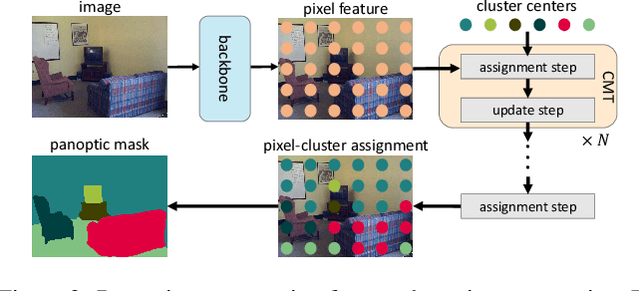

We propose Clustering Mask Transformer (CMT-DeepLab), a transformer-based framework for panoptic segmentation designed around clustering. It rethinks the existing transformer architectures used in segmentation and detection; CMT-DeepLab considers the object queries as cluster centers, which fill the role of grouping the pixels when applied to segmentation. The clustering is computed with an alternating procedure, by first assigning pixels to the clusters by their feature affinity, and then updating the cluster centers and pixel features. Together, these operations comprise the Clustering Mask Transformer (CMT) layer, which produces cross-attention that is denser and more consistent with the final segmentation task. CMT-DeepLab improves the performance over prior art significantly by 4.4% PQ, achieving a new state-of-the-art of 55.7% PQ on the COCO test-dev set.
TubeFormer-DeepLab: Video Mask Transformer
May 30, 2022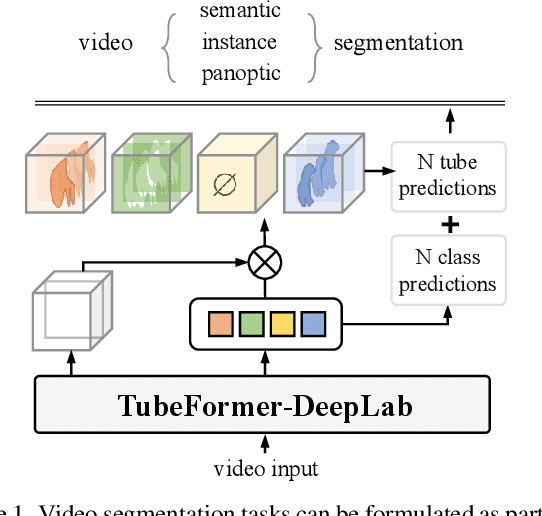
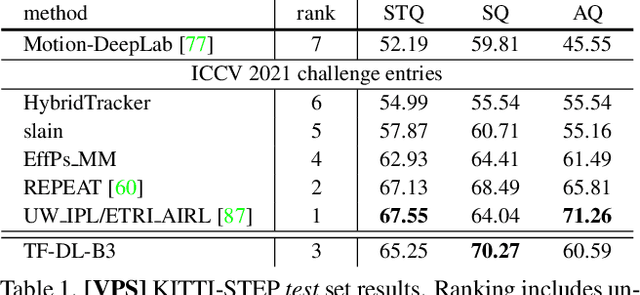
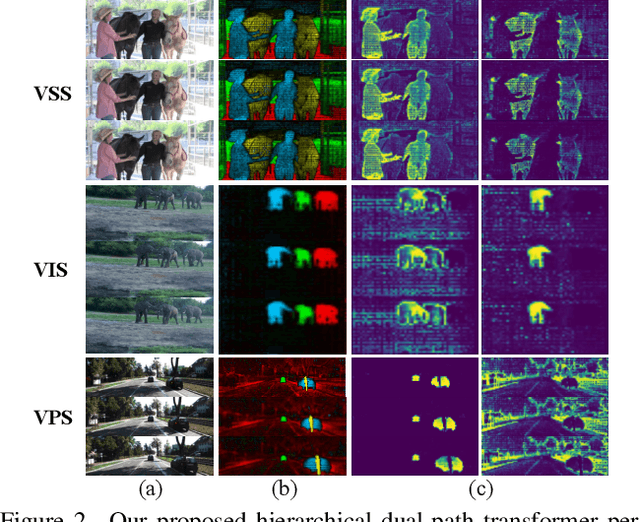
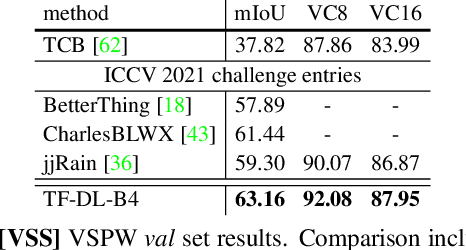
We present TubeFormer-DeepLab, the first attempt to tackle multiple core video segmentation tasks in a unified manner. Different video segmentation tasks (e.g., video semantic/instance/panoptic segmentation) are usually considered as distinct problems. State-of-the-art models adopted in the separate communities have diverged, and radically different approaches dominate in each task. By contrast, we make a crucial observation that video segmentation tasks could be generally formulated as the problem of assigning different predicted labels to video tubes (where a tube is obtained by linking segmentation masks along the time axis) and the labels may encode different values depending on the target task. The observation motivates us to develop TubeFormer-DeepLab, a simple and effective video mask transformer model that is widely applicable to multiple video segmentation tasks. TubeFormer-DeepLab directly predicts video tubes with task-specific labels (either pure semantic categories, or both semantic categories and instance identities), which not only significantly simplifies video segmentation models, but also advances state-of-the-art results on multiple video segmentation benchmarks
Adaptive Transformers for Robust Few-shot Cross-domain Face Anti-spoofing
Mar 23, 2022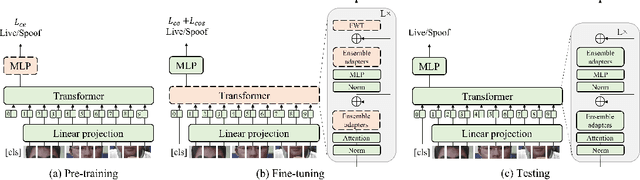
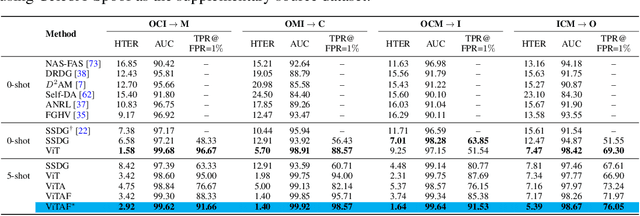
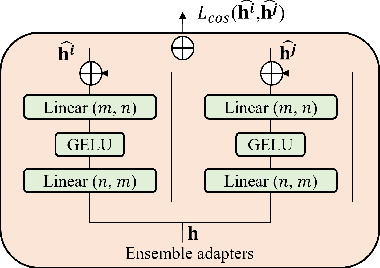
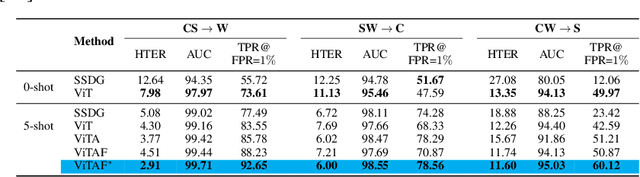
While recent face anti-spoofing methods perform well under the intra-domain setups, an effective approach needs to account for much larger appearance variations of images acquired in complex scenes with different sensors for robust performance. In this paper, we present adaptive vision transformers (ViT) for robust cross-domain face anti-spoofing. Specifically, we adopt ViT as a backbone to exploit its strength to account for long-range dependencies among pixels. We further introduce the ensemble adapters module and feature-wise transformation layers in the ViT to adapt to different domains for robust performance with a few samples. Experiments on several benchmark datasets show that the proposed models achieve both robust and competitive performance against the state-of-the-art methods.
Surrogate Gap Minimization Improves Sharpness-Aware Training
Mar 19, 2022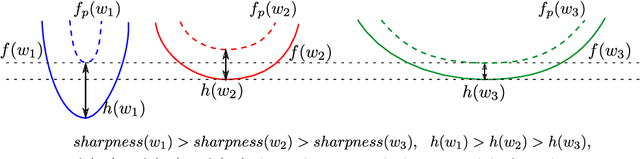
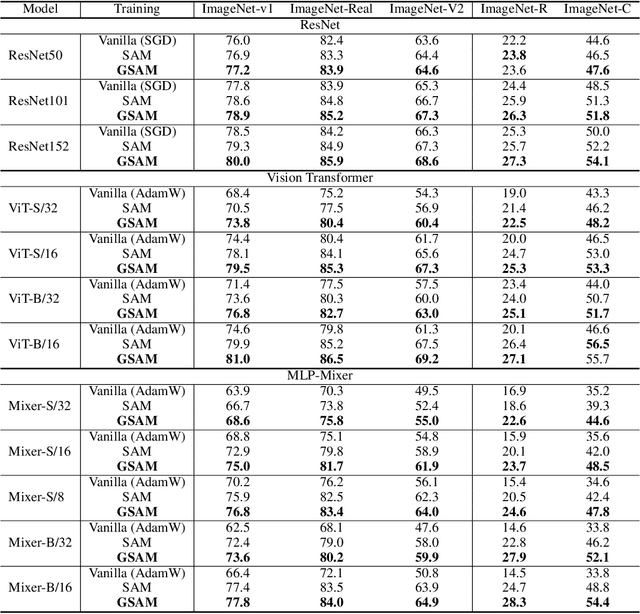


The recently proposed Sharpness-Aware Minimization (SAM) improves generalization by minimizing a \textit{perturbed loss} defined as the maximum loss within a neighborhood in the parameter space. However, we show that both sharp and flat minima can have a low perturbed loss, implying that SAM does not always prefer flat minima. Instead, we define a \textit{surrogate gap}, a measure equivalent to the dominant eigenvalue of Hessian at a local minimum when the radius of the neighborhood (to derive the perturbed loss) is small. The surrogate gap is easy to compute and feasible for direct minimization during training. Based on the above observations, we propose Surrogate \textbf{G}ap Guided \textbf{S}harpness-\textbf{A}ware \textbf{M}inimization (GSAM), a novel improvement over SAM with negligible computation overhead. Conceptually, GSAM consists of two steps: 1) a gradient descent like SAM to minimize the perturbed loss, and 2) an \textit{ascent} step in the \textit{orthogonal} direction (after gradient decomposition) to minimize the surrogate gap and yet not affect the perturbed loss. GSAM seeks a region with both small loss (by step 1) and low sharpness (by step 2), giving rise to a model with high generalization capabilities. Theoretically, we show the convergence of GSAM and provably better generalization than SAM. Empirically, GSAM consistently improves generalization (e.g., +3.2\% over SAM and +5.4\% over AdamW on ImageNet top-1 accuracy for ViT-B/32). Code is released at \url{ https://sites.google.com/view/gsam-iclr22/home}.
Contextualized Spatio-Temporal Contrastive Learning with Self-Supervision
Dec 09, 2021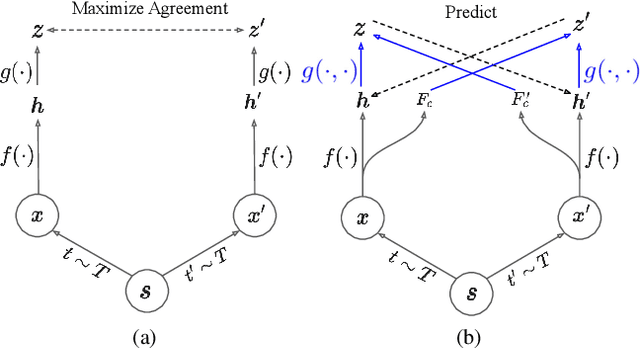
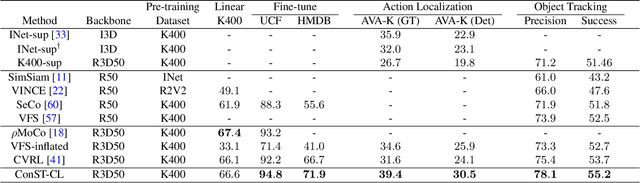
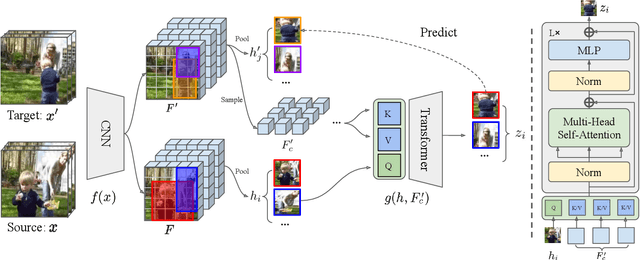
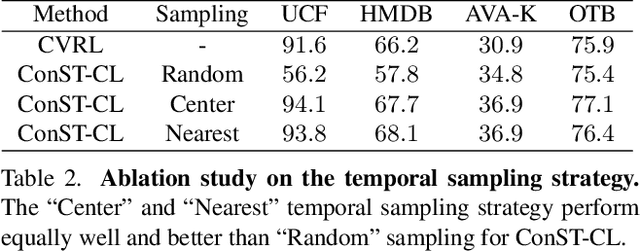
A modern self-supervised learning algorithm typically enforces persistency of the representations of an instance across views. While being very effective on learning holistic image and video representations, such an approach becomes sub-optimal for learning spatio-temporally fine-grained features in videos, where scenes and instances evolve through space and time. In this paper, we present the Contextualized Spatio-Temporal Contrastive Learning (ConST-CL) framework to effectively learn spatio-temporally fine-grained representations using self-supervision. We first design a region-based self-supervised pretext task which requires the model to learn to transform instance representations from one view to another guided by context features. Further, we introduce a simple network design that effectively reconciles the simultaneous learning process of both holistic and local representations. We evaluate our learned representations on a variety of downstream tasks and ConST-CL achieves state-of-the-art results on four datasets. For spatio-temporal action localization, ConST-CL achieves 39.4% mAP with ground-truth boxes and 30.5% mAP with detected boxes on the AVA-Kinetics validation set. For object tracking, ConST-CL achieves 78.1% precision and 55.2% success scores on OTB2015. Furthermore, ConST-CL achieves 94.8% and 71.9% top-1 fine-tuning accuracy on video action recognition datasets, UCF101 and HMDB51 respectively. We plan to release our code and models to the public.
Exploring Temporal Granularity in Self-Supervised Video Representation Learning
Dec 08, 2021



This work presents a self-supervised learning framework named TeG to explore Temporal Granularity in learning video representations. In TeG, we sample a long clip from a video and a short clip that lies inside the long clip. We then extract their dense temporal embeddings. The training objective consists of two parts: a fine-grained temporal learning objective to maximize the similarity between corresponding temporal embeddings in the short clip and the long clip, and a persistent temporal learning objective to pull together global embeddings of the two clips. Our study reveals the impact of temporal granularity with three major findings. 1) Different video tasks may require features of different temporal granularities. 2) Intriguingly, some tasks that are widely considered to require temporal awareness can actually be well addressed by temporally persistent features. 3) The flexibility of TeG gives rise to state-of-the-art results on 8 video benchmarks, outperforming supervised pre-training in most cases.
DeepLab2: A TensorFlow Library for Deep Labeling
Jun 17, 2021


DeepLab2 is a TensorFlow library for deep labeling, aiming to provide a state-of-the-art and easy-to-use TensorFlow codebase for general dense pixel prediction problems in computer vision. DeepLab2 includes all our recently developed DeepLab model variants with pretrained checkpoints as well as model training and evaluation code, allowing the community to reproduce and further improve upon the state-of-art systems. To showcase the effectiveness of DeepLab2, our Panoptic-DeepLab employing Axial-SWideRNet as network backbone achieves 68.0% PQ or 83.5% mIoU on Cityscaspes validation set, with only single-scale inference and ImageNet-1K pretrained checkpoints. We hope that publicly sharing our library could facilitate future research on dense pixel labeling tasks and envision new applications of this technology. Code is made publicly available at \url{https://github.com/google-research/deeplab2}.