 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Open-Vocabulary 3D Semantic Segmentation with Text-to-Image Diffusion Models
Jul 18, 2024



In this paper, we investigate the use of diffusion models which are pre-trained on large-scale image-caption pairs for open-vocabulary 3D semantic understanding. We propose a novel method, namely Diff2Scene, which leverages frozen representations from text-image generative models, along with salient-aware and geometric-aware masks, for open-vocabulary 3D semantic segmentation and visual grounding tasks. Diff2Scene gets rid of any labeled 3D data and effectively identifies objects, appearances, materials, locations and their compositions in 3D scenes. We show that it outperforms competitive baselines and achieves significant improvements over state-of-the-art methods. In particular, Diff2Scene improves the state-of-the-art method on ScanNet200 by 12%.
Building One-class Detector for Anything: Open-vocabulary Zero-shot OOD Detection Using Text-image Models
May 26, 2023



We focus on the challenge of out-of-distribution (OOD) detection in deep learning models, a crucial aspect in ensuring reliability. Despite considerable effort, the problem remains significantly challenging in deep learning models due to their propensity to output over-confident predictions for OOD inputs. We propose a novel one-class open-set OOD detector that leverages text-image pre-trained models in a zero-shot fashion and incorporates various descriptions of in-domain and OOD. Our approach is designed to detect anything not in-domain and offers the flexibility to detect a wide variety of OOD, defined via fine- or coarse-grained labels, or even in natural language. We evaluate our approach on challenging benchmarks including large-scale datasets containing fine-grained, semantically similar classes, distributionally shifted images, and multi-object images containing a mixture of in-domain and OOD objects. Our method shows superior performance over previous methods on all benchmarks. Code is available at https://github.com/gyhandy/One-Class-Anything
Improving Zero-shot Generalization and Robustness of Multi-modal Models
Dec 04, 2022



Multi-modal image-text models such as CLIP and LiT have demonstrated impressive performance on image classification benchmarks and their zero-shot generalization ability is particularly exciting. While the top-5 zero-shot accuracies of these models are very high, the top-1 accuracies are much lower (over 25% gap in some cases). We investigate the reasons for this performance gap and find that many of the failure cases are caused by ambiguity in the text prompts. First, we develop a simple and efficient zero-shot post-hoc method to identify images whose top-1 prediction is likely to be incorrect, by measuring consistency of the predictions w.r.t. multiple prompts and image transformations. We show that our procedure better predicts mistakes, outperforming the popular max logit baseline on selective prediction tasks. Next, we propose a simple and efficient way to improve accuracy on such uncertain images by making use of the WordNet hierarchy; specifically we augment the original class by incorporating its parent and children from the semantic label hierarchy, and plug the augmentation into text promts. We conduct experiments on both CLIP and LiT models with five different ImageNet-based datasets. For CLIP, our method improves the top-1 accuracy by 17.13% on the uncertain subset and 3.6% on the entire ImageNet validation set. We also show that our method improves across ImageNet shifted datasets and other model architectures such as LiT. Our proposed method is hyperparameter-free, requires no additional model training and can be easily scaled to other large multi-modal architectures.
Automatic Differentiation Variational Inference with Mixtures
Mar 05, 2020
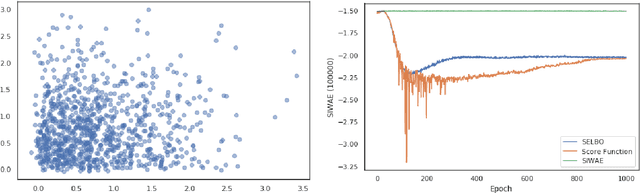
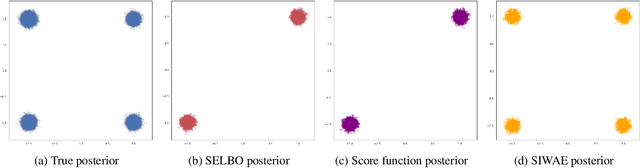
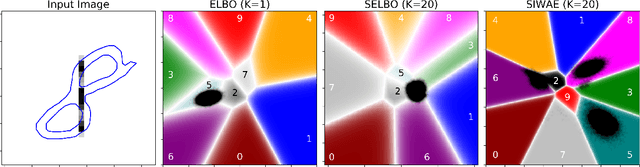
Automatic Differentiation Variational Inference (ADVI) is a useful tool for efficiently learning probabilistic models in machine learning. Generally approximate posteriors learned by ADVI are forced to be unimodal in order to facilitate use of the reparameterization trick. In this paper, we show how stratified sampling may be used to enable mixture distributions as the approximate posterior, and derive a new lower bound on the evidence analogous to the importance weighted autoencoder (IWAE). We show that this "SIWAE" is a tighter bound than both IWAE and the traditional ELBO, both of which are special instances of this bound. We verify empirically that the traditional ELBO objective disfavors the presence of multimodal posterior distributions and may therefore not be able to fully capture structure in the latent space. Our experiments show that using the SIWAE objective allows the encoder to learn more complex distributions which regularly contain multimodality, resulting in higher accuracy and better calibration in the presence of incomplete, limited, or corrupted data.
AVA-ActiveSpeaker: An Audio-Visual Dataset for Active Speaker Detection
Jan 05, 2019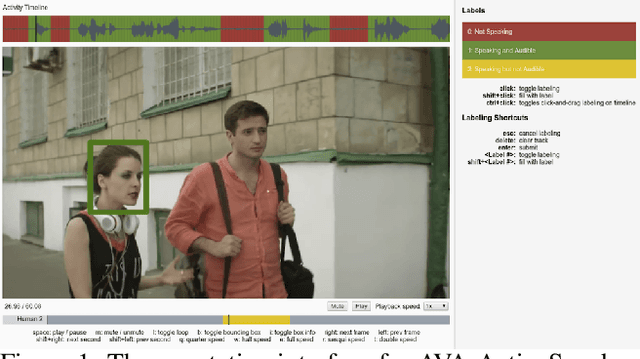
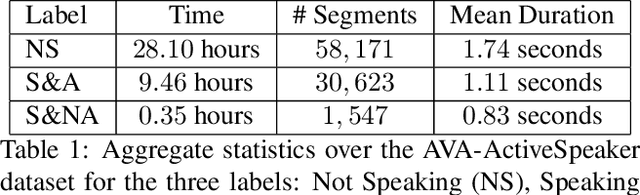

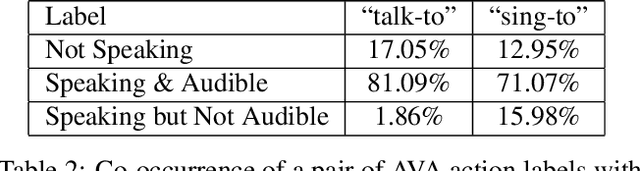
Active speaker detection is an important component in video analysis algorithms for applications such as speaker diarization, video re-targeting for meetings, speech enhancement, and human-robot interaction. The absence of a large, carefully labeled audio-visual dataset for this task has constrained algorithm evaluations with respect to data diversity, environments, and accuracy. This has made comparisons and improvements difficult. In this paper, we present the AVA Active Speaker detection dataset (AVA-ActiveSpeaker) that will be released publicly to facilitate algorithm development and enable comparisons. The dataset contains temporally labeled face tracks in video, where each face instance is labeled as speaking or not, and whether the speech is audible. This dataset contains about 3.65 million human labeled frames or about 38.5 hours of face tracks, and the corresponding audio. We also present a new audio-visual approach for active speaker detection, and analyze its performance, demonstrating both its strength and the contributions of the dataset.
Modeling Uncertainty with Hedged Instance Embedding
Oct 19, 2018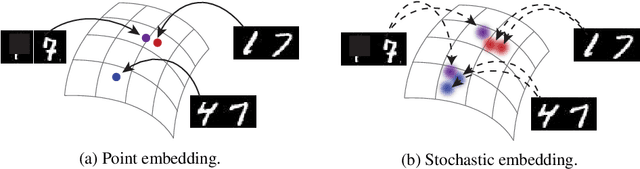
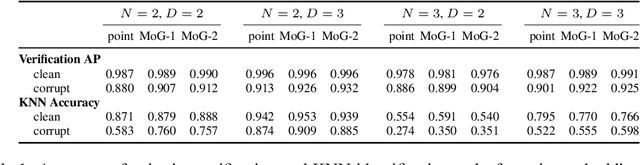
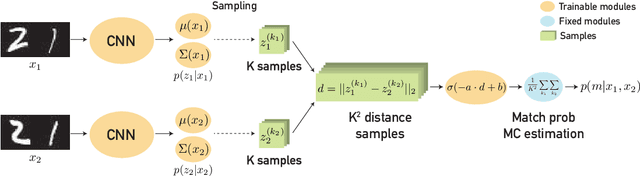
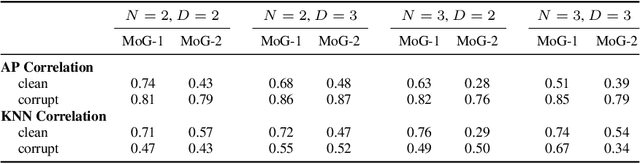
Instance embeddings are an efficient and versatile image representation that facilitates applications like recognition, verification, retrieval, and clustering. Many metric learning methods represent the input as a single point in the embedding space. Often the distance between points is used as a proxy for match confidence. However, this can fail to represent uncertainty arising when the input is ambiguous, e.g., due to occlusion or blurriness. This work addresses this issue and explicitly models the uncertainty by hedging the location of each input in the embedding space. We introduce the hedged instance embedding (HIB) in which embeddings are modeled as random variables and the model is trained under the variational information bottleneck principle. Empirical results on our new N-digit MNIST dataset show that our method leads to the desired behavior of hedging its bets across the embedding space upon encountering ambiguous inputs. This results in improved performance for image matching and classification tasks, more structure in the learned embedding space, and an ability to compute a per-exemplar uncertainty measure that is correlated with downstream performance.
Finding your Lookalike: Measuring Face Similarity Rather than Face Identity
Jun 13, 2018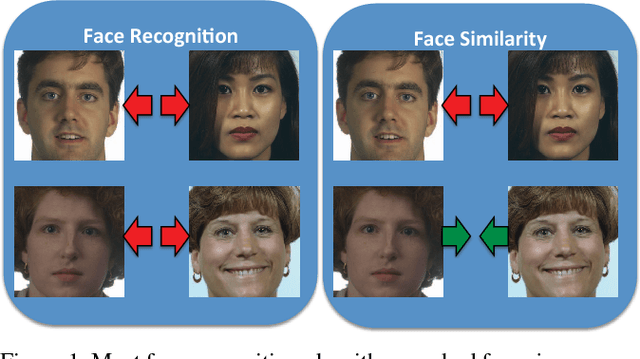
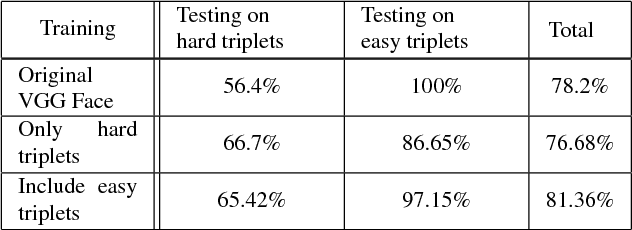

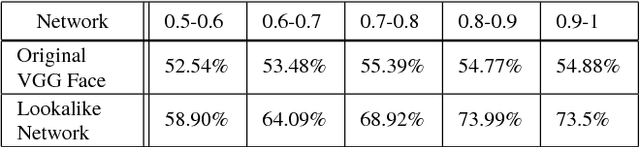
Face images are one of the main areas of focus for computer vision, receiving on a wide variety of tasks. Although face recognition is probably the most widely researched, many other tasks such as kinship detection, facial expression classification and facial aging have been examined. In this work we propose the new, subjective task of quantifying perceived face similarity between a pair of faces. That is, we predict the perceived similarity between facial images, given that they are not of the same person. Although this task is clearly correlated with face recognition, it is different and therefore justifies a separate investigation. Humans often remark that two persons look alike, even in cases where the persons are not actually confused with one another. In addition, because face similarity is different than traditional image similarity, there are challenges in data collection and labeling, and dealing with diverging subjective opinions between human labelers. We present evidence that finding facial look-alikes and recognizing faces are two distinct tasks. We propose a new dataset for facial similarity and introduce the Lookalike network, directed towards similar face classification, which outperforms the ad hoc usage of a face recognition network directed at the same task.