 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoGCL: Automated Graph Contrastive Learning via Learnable View Generators
Sep 21, 2021
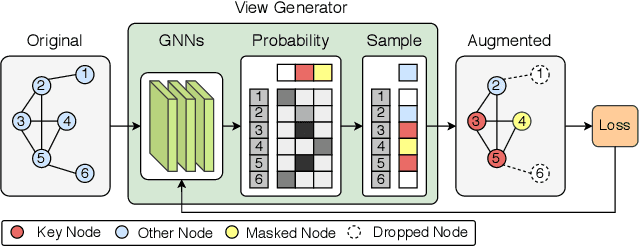
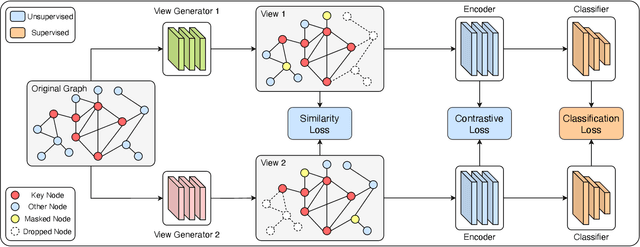
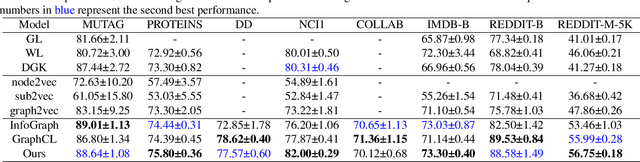
Contrastive learning has been widely applied to graph representation learning, where the view generators play a vital role in generating effective contrastive samples. Most of the existing contrastive learning methods employ pre-defined view generation methods, e.g., node drop or edge perturbation, which usually cannot adapt to input data or preserve the original semantic structures well. To address this issue, we propose a novel framework named Automated Graph Contrastive Learning (AutoGCL) in this paper. Specifically, AutoGCL employs a set of learnable graph view generators orchestrated by an auto augmentation strategy, where every graph view generator learns a probability distribution of graphs conditioned by the input. While the graph view generators in AutoGCL preserve the most representative structures of the original graph in generation of every contrastive sample, the auto augmentation learns policies to introduce adequate augmentation variances in the whole contrastive learning procedure. Furthermore, AutoGCL adopts a joint training strategy to train the learnable view generators, the graph encoder, and the classifier in an end-to-end manner, resulting in topological heterogeneity yet semantic similarity in the generation of contrastive samples. Extensive experiments on semi-supervised learning, unsupervised learning, and transfer learning demonstrate the superiority of our AutoGCL framework over the state-of-the-arts in graph contrastive learning. In addition, the visualization results further confirm that the learnable view generators can deliver more compact and semantically meaningful contrastive samples compared against the existing view generation methods.
Cross-Model Consensus of Explanations and Beyond for Image Classification Models: An Empirical Study
Sep 02, 2021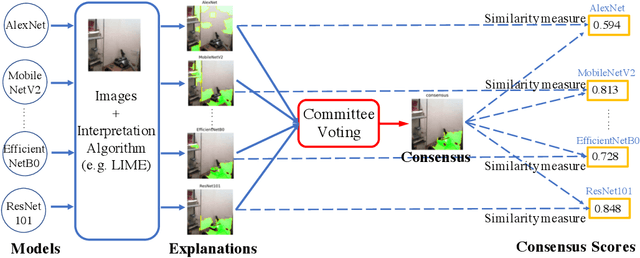

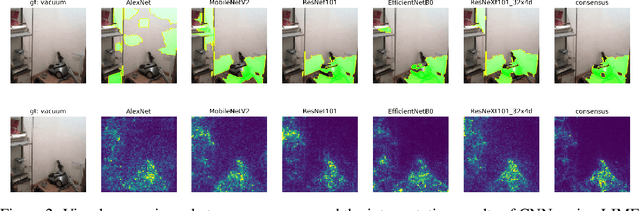
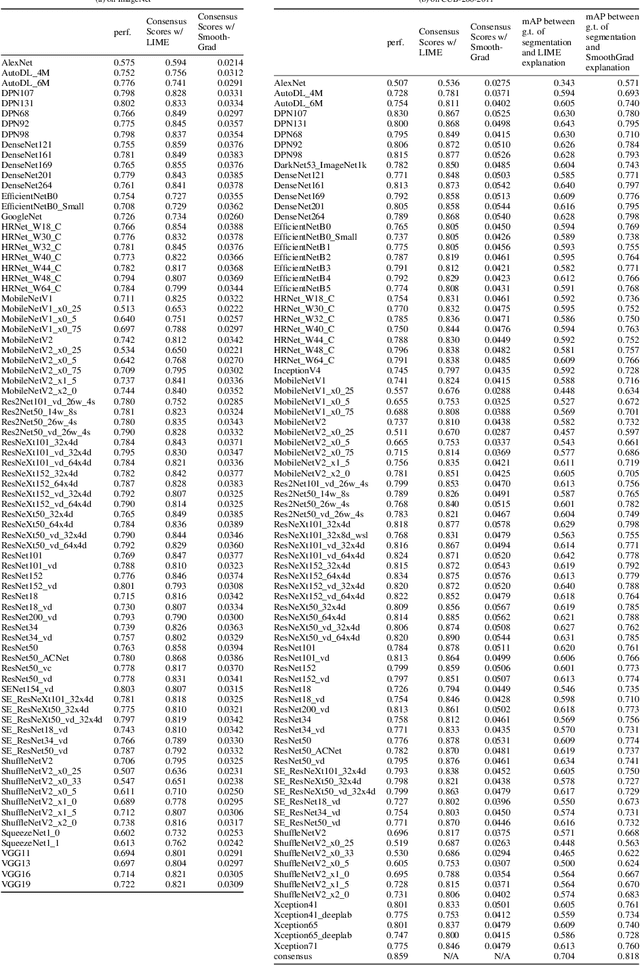
Existing interpretation algorithms have found that, even deep models make the same and right predictions on the same image, they might rely on different sets of input features for classification. However, among these sets of features, some common features might be used by the majority of models. In this paper, we are wondering what are the common features used by various models for classification and whether the models with better performance may favor those common features. For this purpose, our works uses an interpretation algorithm to attribute the importance of features (e.g., pixels or superpixels) as explanations, and proposes the cross-model consensus of explanations to capture the common features. Specifically, we first prepare a set of deep models as a committee, then deduce the explanation for every model, and obtain the consensus of explanations across the entire committee through voting. With the cross-model consensus of explanations, we conduct extensive experiments using 80+ models on 5 datasets/tasks. We find three interesting phenomena as follows: (1) the consensus obtained from image classification models is aligned with the ground truth of semantic segmentation; (2) we measure the similarity of the explanation result of each model in the committee to the consensus (namely consensus score), and find positive correlations between the consensus score and model performance; and (3) the consensus score coincidentally correlates to the interpretability.
Semi-Supervised Active Learning with Temporal Output Discrepancy
Jul 29, 2021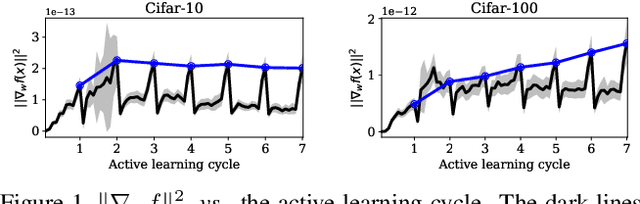
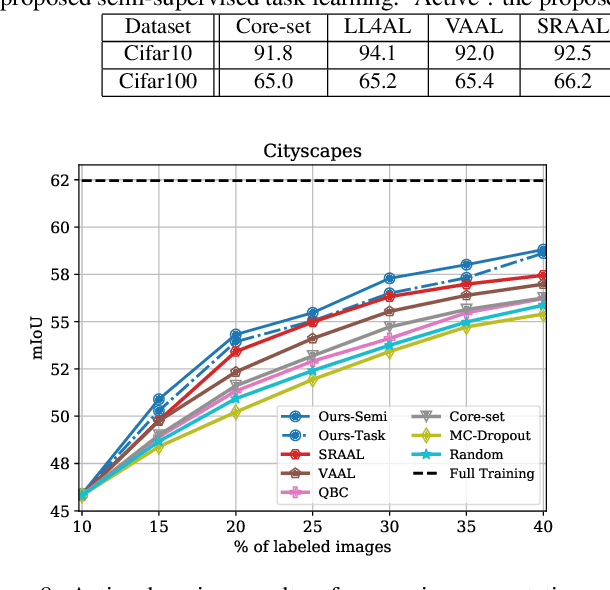


While deep learning succeeds in a wide range of tasks, it highly depends on the massive collection of annotated data which is expensive and time-consuming. To lower the cost of data annotation, active learning has been proposed to interactively query an oracle to annotate a small proportion of informative samples in an unlabeled dataset. Inspired by the fact that the samples with higher loss are usually more informative to the model than the samples with lower loss, in this paper we present a novel deep active learning approach that queries the oracle for data annotation when the unlabeled sample is believed to incorporate high loss. The core of our approach is a measurement Temporal Output Discrepancy (TOD) that estimates the sample loss by evaluating the discrepancy of outputs given by models at different optimization steps. Our theoretical investigation shows that TOD lower-bounds the accumulated sample loss thus it can be used to select informative unlabeled samples. On basis of TOD, we further develop an effective unlabeled data sampling strategy as well as an unsupervised learning criterion that enhances model performance by incorporating the unlabeled data. Due to the simplicity of TOD, our active learning approach is efficient, flexible, and task-agnostic. Extensive experimental results demonstrate that our approach achieves superior performances than the state-of-the-art active learning methods on image classification and semantic segmentation tasks.
Structure-aware Interactive Graph Neural Networks for the Prediction of Protein-Ligand Binding Affinity
Jul 21, 2021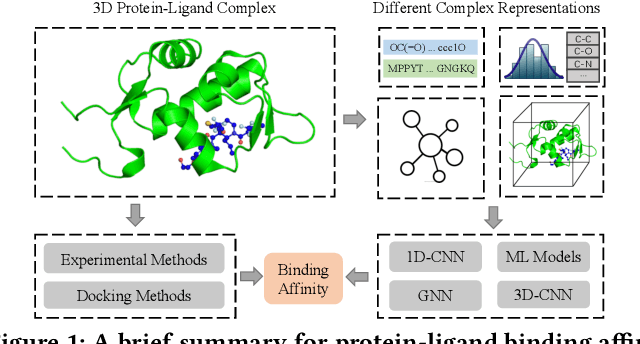
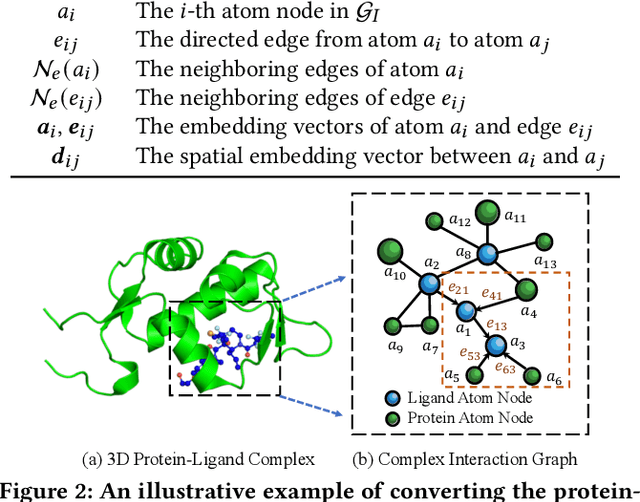
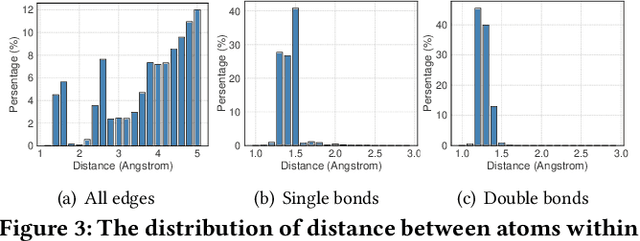
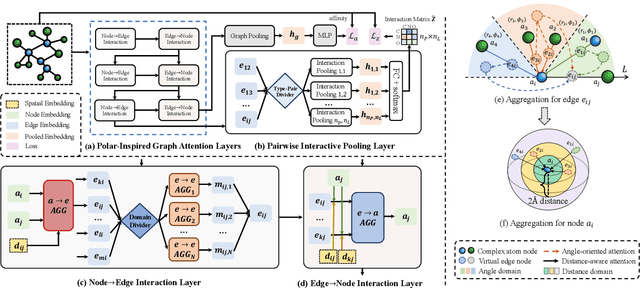
Drug discovery often relies on the successful prediction of protein-ligand binding affinity. Recent advances have shown great promise in applying graph neural networks (GNNs) for better affinity prediction by learning the representations of protein-ligand complexes. However, existing solutions usually treat protein-ligand complexes as topological graph data, thus the biomolecular structural information is not fully utilized. The essential long-range interactions among atoms are also neglected in GNN models. To this end, we propose a structure-aware interactive graph neural network (SIGN) which consists of two components: polar-inspired graph attention layers (PGAL) and pairwise interactive pooling (PiPool). Specifically, PGAL iteratively performs the node-edge aggregation process to update embeddings of nodes and edges while preserving the distance and angle information among atoms. Then, PiPool is adopted to gather interactive edges with a subsequent reconstruction loss to reflect the global interactions. Exhaustive experimental study on two benchmarks verifies the superiority of SIGN.
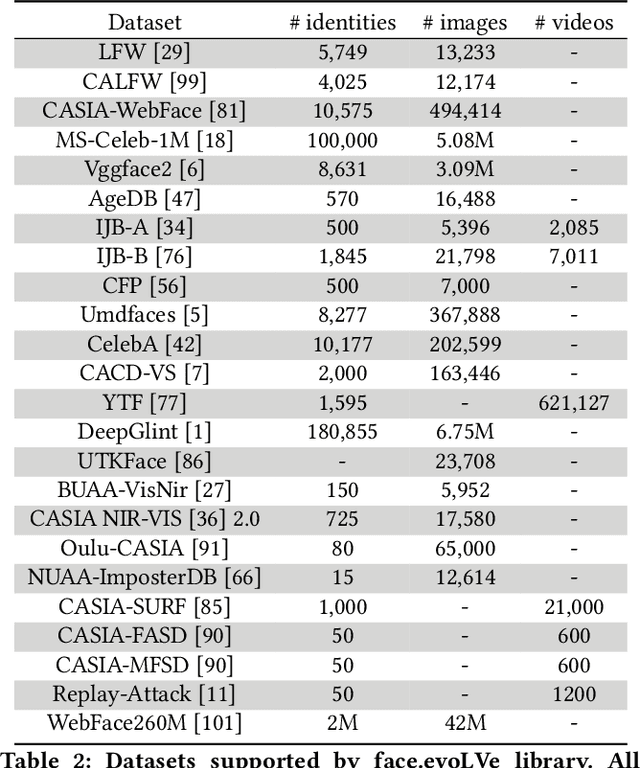
Face.evoLVe: A High-Performance Face Recognition Library
Jul 20, 2021

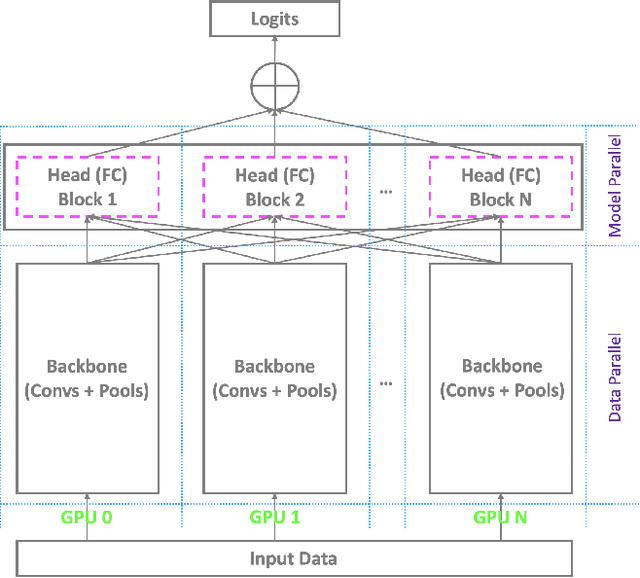
In this paper, we develop face.evoLVe -- a comprehensive library that collects and implements a wide range of popular deep learning-based methods for face recognition. First of all, face.evoLVe is composed of key components that cover the full process of face analytics, including face alignment, data processing, various backbones, losses, and alternatives with bags of tricks for improving performance. Later, face.evoLVe supports multi-GPU training on top of different deep learning platforms, such as PyTorch and PaddlePaddle, which facilitates researchers to work on both large-scale datasets with millions of images and low-shot counterparts with limited well-annotated data. More importantly, along with face.evoLVe, images before & after alignment in the common benchmark datasets are released with source codes and trained models provided. All these efforts lower the technical burdens in reproducing the existing methods for comparison, while users of our library could focus on developing advanced approaches more efficiently. Last but not least, face.evoLVe is well designed and vibrantly evolving, so that new face recognition approaches can be easily plugged into our framework. Note that we have used face.evoLVe to participate in a number of face recognition competitions and secured the first place. The version that supports PyTorch is publicly available at https://github.com/ZhaoJ9014/face.evoLVe.PyTorch and the PaddlePaddle version is available at https://github.com/ZhaoJ9014/face.evoLVe.PyTorch/tree/master/paddle. Face.evoLVe has been widely used for face analytics, receiving 2.4K stars and 622 forks.
Robust Matrix Factorization with Grouping Effect
Jul 08, 2021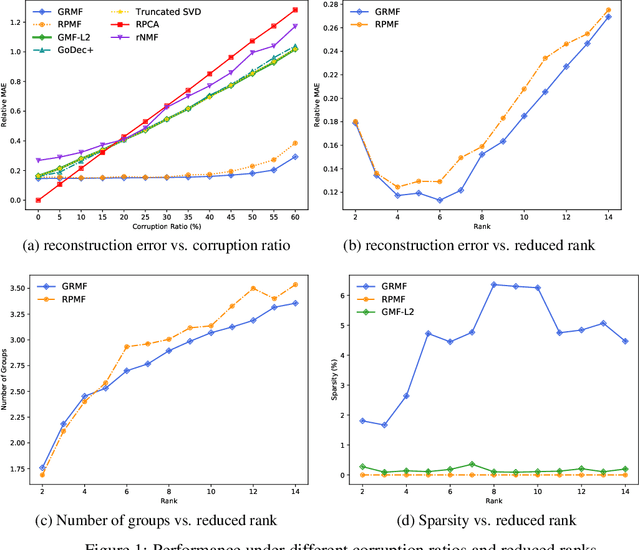

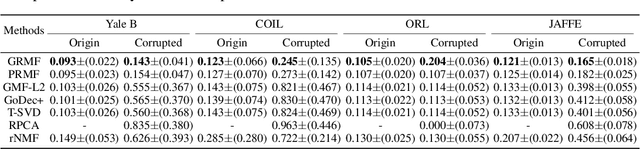

Although many techniques have been applied to matrix factorization (MF), they may not fully exploit the feature structure. In this paper, we incorporate the grouping effect into MF and propose a novel method called Robust Matrix Factorization with Grouping effect (GRMF). The grouping effect is a generalization of the sparsity effect, which conducts denoising by clustering similar values around multiple centers instead of just around 0. Compared with existing algorithms, the proposed GRMF can automatically learn the grouping structure and sparsity in MF without prior knowledge, by introducing a naturally adjustable non-convex regularization to achieve simultaneous sparsity and grouping effect. Specifically, GRMF uses an efficient alternating minimization framework to perform MF, in which the original non-convex problem is first converted into a convex problem through Difference-of-Convex (DC) programming, and then solved by Alternating Direction Method of Multipliers (ADMM). In addition, GRMF can be easily extended to the Non-negative Matrix Factorization (NMF) settings. Extensive experiments have been conducted using real-world data sets with outliers and contaminated noise, where the experimental results show that GRMF has promoted performance and robustness, compared to five benchmark algorithms.
From Personalized Medicine to Population Health: A Survey of mHealth Sensing Techniques
Jul 02, 2021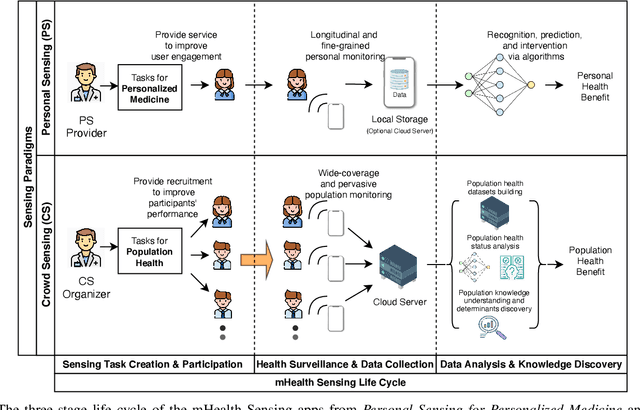
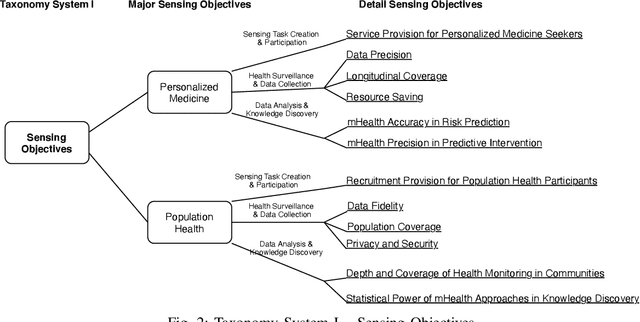
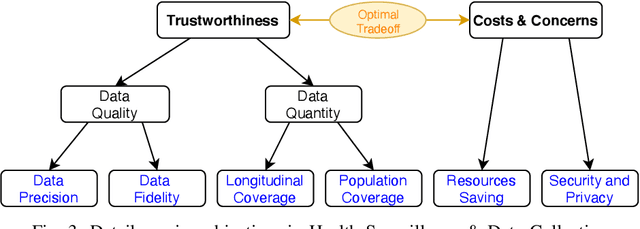
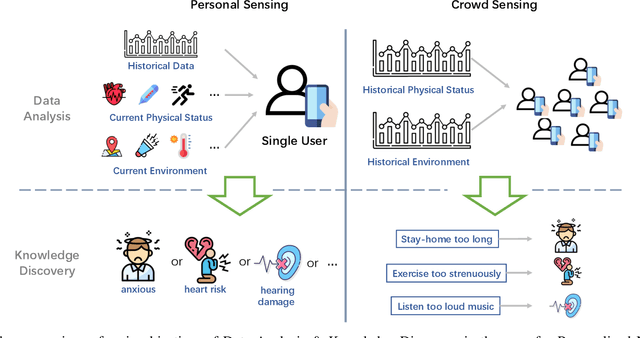
Mobile Sensing Apps have been widely used as a practical approach to collect behavioral and health-related information from individuals and provide timely intervention to promote health and well-beings, such as mental health and chronic cares. As the objectives of mobile sensing could be either \emph{(a) personalized medicine for individuals} or \emph{(b) public health for populations}, in this work we review the design of these mobile sensing apps, and propose to categorize the design of these apps/systems in two paradigms -- \emph{(i) Personal Sensing} and \emph{(ii) Crowd Sensing} paradigms. While both sensing paradigms might incorporate with common ubiquitous sensing technologies, such as wearable sensors, mobility monitoring, mobile data offloading, and/or cloud-based data analytics to collect and process sensing data from individuals, we present a novel taxonomy system with two major components that can specify and classify apps/systems from aspects of the life-cycle of mHealth Sensing: \emph{(1) Sensing Task Creation \& Participation}, \emph{(2) Health Surveillance \& Data Collection}, and \emph{(3) Data Analysis \& Knowledge Discovery}. With respect to different goals of the two paradigms, this work systematically reviews this field, and summarizes the design of typical apps/systems in the view of the configurations and interactions between these two components. In addition to summarization, the proposed taxonomy system also helps figure out the potential directions of mobile sensing for health from both personalized medicines and population health perspectives.
Practical Assessment of Generalization Performance Robustness for Deep Networks via Contrastive Examples
Jun 20, 2021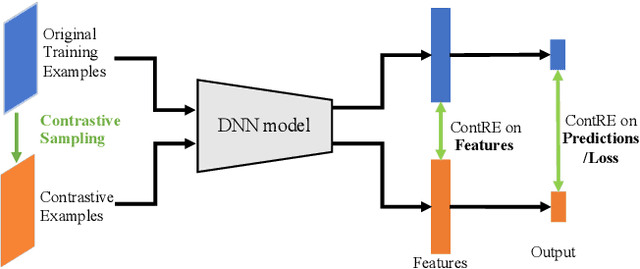
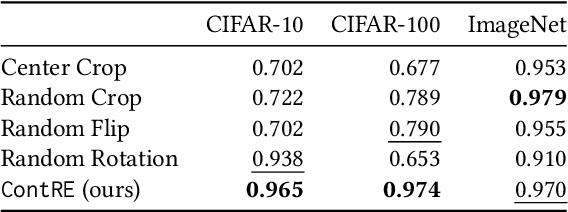
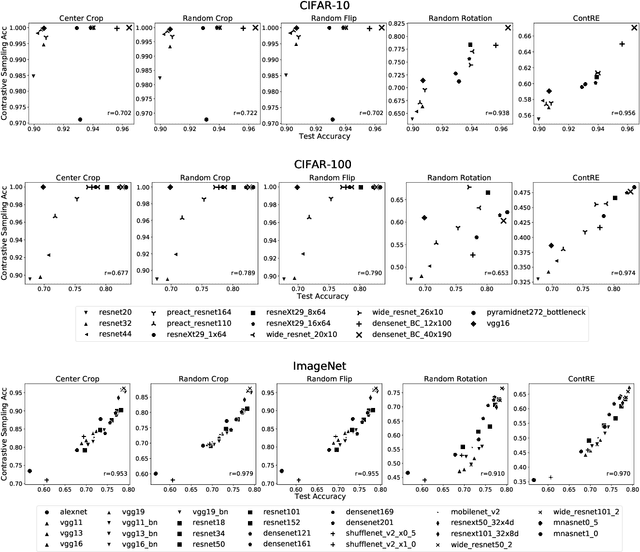
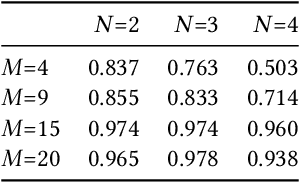
Training images with data transformations have been suggested as contrastive examples to complement the testing set for generalization performance evaluation of deep neural networks (DNNs). In this work, we propose a practical framework ContRE (The word "contre" means "against" or "versus" in French.) that uses Contrastive examples for DNN geneRalization performance Estimation. Specifically, ContRE follows the assumption in contrastive learning that robust DNN models with good generalization performance are capable of extracting a consistent set of features and making consistent predictions from the same image under varying data transformations. Incorporating with a set of randomized strategies for well-designed data transformations over the training set, ContRE adopts classification errors and Fisher ratios on the generated contrastive examples to assess and analyze the generalization performance of deep models in complement with a testing set. To show the effectiveness and the efficiency of ContRE, extensive experiments have been done using various DNN models on three open source benchmark datasets with thorough ablation studies and applicability analyses. Our experiment results confirm that (1) behaviors of deep models on contrastive examples are strongly correlated to what on the testing set, and (2) ContRE is a robust measure of generalization performance complementing to the testing set in various settings.
Optimization Variance: Exploring Generalization Properties of DNNs
Jun 03, 2021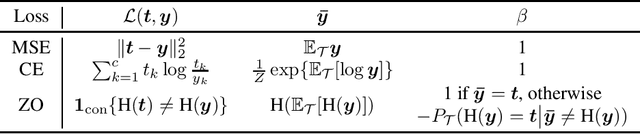
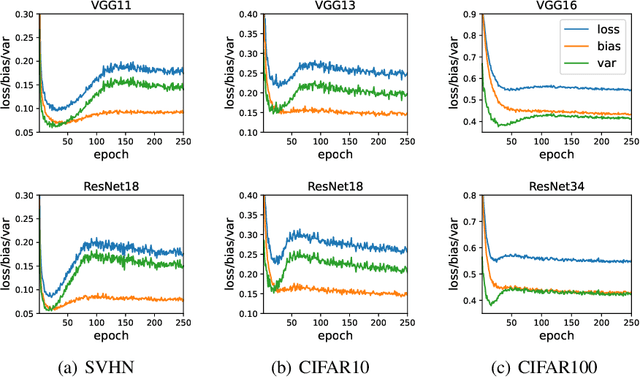
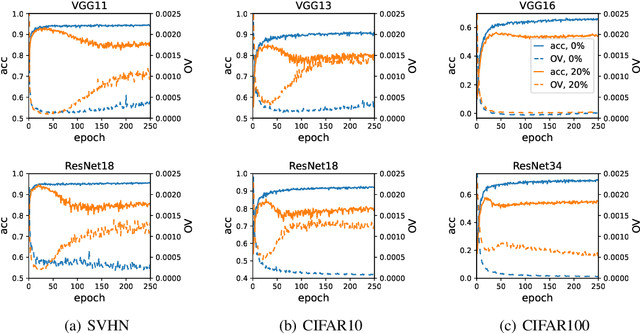
Unlike the conventional wisdom in statistical learning theory, the test error of a deep neural network (DNN) often demonstrates double descent: as the model complexity increases, it first follows a classical U-shaped curve and then shows a second descent. Through bias-variance decomposition, recent studies revealed that the bell-shaped variance is the major cause of model-wise double descent (when the DNN is widened gradually). This paper investigates epoch-wise double descent, i.e., the test error of a DNN also shows double descent as the number of training epoches increases. By extending the bias-variance analysis to epoch-wise double descent of the zero-one loss, we surprisingly find that the variance itself, without the bias, varies consistently with the test error. Inspired by this result, we propose a novel metric, optimization variance (OV), to measure the diversity of model updates caused by the stochastic gradients of random training batches drawn in the same iteration. OV can be estimated using samples from the training set only but correlates well with the (unknown) \emph{test} error, and hence early stopping may be achieved without using a validation set.
JIZHI: A Fast and Cost-Effective Model-As-A-Service System for Web-Scale Online Inference at Baidu
Jun 03, 2021
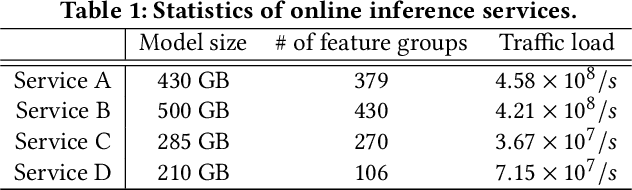
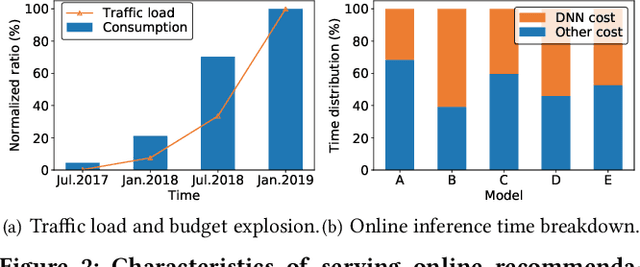
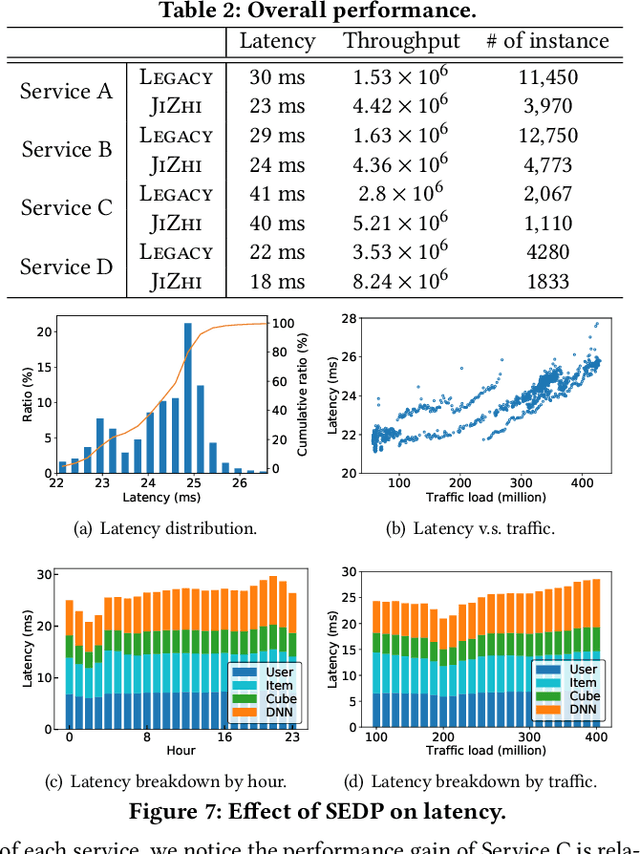
In modern internet industries, deep learning based recommender systems have became an indispensable building block for a wide spectrum of applications, such as search engine, news feed, and short video clips. However, it remains challenging to carry the well-trained deep models for online real-time inference serving, with respect to the time-varying web-scale traffics from billions of users, in a cost-effective manner. In this work, we present JIZHI - a Model-as-a-Service system - that per second handles hundreds of millions of online inference requests to huge deep models with more than trillions of sparse parameters, for over twenty real-time recommendation services at Baidu, Inc. In JIZHI, the inference workflow of every recommendation request is transformed to a Staged Event-Driven Pipeline (SEDP), where each node in the pipeline refers to a staged computation or I/O intensive task processor. With traffics of real-time inference requests arrived, each modularized processor can be run in a fully asynchronized way and managed separately. Besides, JIZHI introduces heterogeneous and hierarchical storage to further accelerate the online inference process by reducing unnecessary computations and potential data access latency induced by ultra-sparse model parameters. Moreover, an intelligent resource manager has been deployed to maximize the throughput of JIZHI over the shared infrastructure by searching the optimal resource allocation plan from historical logs and fine-tuning the load shedding policies over intermediate system feedback. Extensive experiments have been done to demonstrate the advantages of JIZHI from the perspectives of end-to-end service latency, system-wide throughput, and resource consumption. JIZHI has helped Baidu saved more than ten million US dollars in hardware and utility costs while handling 200% more traffics without sacrificing inference efficiency.