 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndusAgent: Reinforcing Open-Vocabulary Industrial Anomaly Detection with Agentic Tools
May 20, 2026Multimodal large language models (MLLMs) have shown remarkable capability in bridging visual perception and textual reasoning, enabling zero-shot understanding across diverse industrial scenarios. However, their performance in open-vocabulary industrial anomaly detection (IAD) is often limited by domain-misaligned reasoning and hallucinated structural inferences. To address these challenges, we propose \textbf{IndusAgent}, a tool-augmented agentic framework for open-vocabulary IAD. Specifically, we first construct \textbf{Indus-CoT}, a structured dataset that integrates global visual observations, high-resolution local patches, and expert normalcy priors, providing supervision for fine-tuning the model on rigorous industrial inspection trajectories. Building on this, IndusAgent dynamically orchestrates a set of external tools, including dynamic region cropping, high-frequency feature enhancement, and prior retrieval, thus enabling the agent to actively resolve visual ambiguities and disentangle subtle anomalies. Furthermore, we introduce a gated reinforcement learning objective that jointly optimizes anomaly classification, localization accuracy, anomaly type reasoning, and efficient tool usage, ensuring that tool invocation occurs only when beneficial. Extensive evaluations on five industrial anomaly benchmarks, including MVTec-AD, VisA, MPDD, DTD, and SDD, demonstrate that IndusAgent achieves state-of-the-art zero-shot performance among all existing methods, validating our robustness and generalization capacity.
BalanceRAG: Joint Risk Calibration for Cascaded Retrieval-Augmented Generation
May 19, 2026Large language models (LLMs) can enhance factuality via retrieval-augmented generation (RAG), but applying RAG to every query is unnecessary when the model-only answer is reliable. This motivates cascaded RAG: each query is first handled by an LLM-only branch, escalated to a RAG fallback only if the primary branch is uncertain, and abstained from when neither branch is sufficiently trustworthy. However, calibrating such cascades stage by stage may be conservative, since the final utility depends on joint uncertainty thresholding of LLM-only and RAG. In this work, we develop BalanceRAG to certify threshold pairs at a target risk level. Given uncertainty scores from the two branches, BalanceRAG frames each threshold pair as an operating point on a two-dimensional lattice and identifies safe operating points using sequential graphical testing. This enables risk-adaptive threshold calibration, controlling the system-level error rate among accepted points, while retaining more examples. Furthermore, BalanceRAG extends to multi-risk calibration, allowing retrieval usage to be bounded together with the selection-conditioned risk. Experiments on three open-domain question answering (QA) benchmarks across multiple LLM backbones demonstrate that BalanceRAG meets prescribed risk levels, preserves higher coverage and more accepted correct examples, and reduces unnecessary retrieval calls compared with always-on RAG.
PSI: Shared State as the Missing Layer for Coherent AI-Generated Instruments in Personal AI Agents
Apr 09, 2026Personal AI tools can now be generated from natural-language requests, but they often remain isolated after creation. We present PSI, a shared-state architecture that turns independently generated modules into coherent instruments: persistent, connected, and chat-complementary artifacts accessible through both GUIs and a generic chat agent. By publishing current state and write-back affordances to a shared personal-context bus, modules enable cross-module reasoning and synchronized actions across interfaces. We study PSI through a three-week autobiographical deployment in a self-developed personal AI environment and show that later-generated instruments can be integrated automatically through the same contract. PSI identifies shared state as the missing systems layer that transforms AI-generated personal software from isolated apps into coherent personal computing environments.
Set-Valued Prediction for Large Language Models with Feasibility-Aware Coverage Guarantees
Mar 24, 2026Large language models (LLMs) inherently operate over a large generation space, yet conventional usage typically reports the most likely generation (MLG) as a point prediction, which underestimates the model's capability: although the top-ranked response can be incorrect, valid answers may still exist within the broader output space and can potentially be discovered through repeated sampling. This observation motivates moving from point prediction to set-valued prediction, where the model produces a set of candidate responses rather than a single MLG. In this paper, we propose a principled framework for set-valued prediction, which provides feasibility-aware coverage guarantees. We show that, given the finite-sampling nature of LLM generation, coverage is not always achievable: even with multiple samplings, LLMs may fail to yield an acceptable response for certain questions within the sampled candidate set. To address this, we establish a minimum achievable risk level (MRL), below which statistical coverage guarantees cannot be satisfied. Building on this insight, we then develop a data-driven calibration procedure that constructs prediction sets from sampled responses by estimating a rigorous threshold, ensuring that the resulting set contains a correct answer with a desired probability whenever the target risk level is feasible. Extensive experiments on six language generation tasks with five LLMs demonstrate both the statistical validity and the predictive efficiency of our framework.
Towards Efficient and Robust Linguistic Emotion Diagnosis for Mental Health via Multi-Agent Instruction Refinement
Jan 20, 2026Linguistic expressions of emotions such as depression, anxiety, and trauma-related states are pervasive in clinical notes, counseling dialogues, and online mental health communities, and accurate recognition of these emotions is essential for clinical triage, risk assessment, and timely intervention. Although large language models (LLMs) have demonstrated strong generalization ability in emotion analysis tasks, their diagnostic reliability in high-stakes, context-intensive medical settings remains highly sensitive to prompt design. Moreover, existing methods face two key challenges: emotional comorbidity, in which multiple intertwined emotional states complicate prediction, and inefficient exploration of clinically relevant cues. To address these challenges, we propose APOLO (Automated Prompt Optimization for Linguistic Emotion Diagnosis), a framework that systematically explores a broader and finer-grained prompt space to improve diagnostic efficiency and robustness. APOLO formulates instruction refinement as a Partially Observable Markov Decision Process and adopts a multi-agent collaboration mechanism involving Planner, Teacher, Critic, Student, and Target roles. Within this closed-loop framework, the Planner defines an optimization trajectory, while the Teacher-Critic-Student agents iteratively refine prompts to enhance reasoning stability and effectiveness, and the Target agent determines whether to continue optimization based on performance evaluation. Experimental results show that APOLO consistently improves diagnostic accuracy and robustness across domain-specific and stratified benchmarks, demonstrating a scalable and generalizable paradigm for trustworthy LLM applications in mental healthcare.
$A^3$-Bench: Benchmarking Memory-Driven Scientific Reasoning via Anchor and Attractor Activation
Jan 14, 2026Scientific reasoning relies not only on logical inference but also on activating prior knowledge and experiential structures. Memory can efficiently reuse knowledge and enhance reasoning consistency and stability. However, existing benchmarks mainly evaluate final answers or step-by-step coherence, overlooking the \textit{memory-driven} mechanisms that underlie human reasoning, which involves activating anchors and attractors, then integrating them into multi-step inference. To address this gap, we propose $A^3$-Bench~ https://a3-bench.github.io, a benchmark designed to evaluate scientific reasoning through dual-scale memory-driven activation, grounded in Anchor and Attractor Activation. First, we annotate 2,198 science reasoning problems across domains using the SAPM process(subject, anchor & attractor, problem, and memory developing). Second, we introduce a dual-scale memory evaluation framework utilizing anchors and attractors, along with the AAUI(Anchor--Attractor Utilization Index) metric to measure memory activation rates. Finally, through experiments with various base models and paradigms, we validate $A^3$-Bench and analyze how memory activation impacts reasoning performance, providing insights into memory-driven scientific reasoning.
MAXS: Meta-Adaptive Exploration with LLM Agents
Jan 14, 2026Large Language Model (LLM) Agents exhibit inherent reasoning abilities through the collaboration of multiple tools. However, during agent inference, existing methods often suffer from (i) locally myopic generation, due to the absence of lookahead, and (ii) trajectory instability, where minor early errors can escalate into divergent reasoning paths. These issues make it difficult to balance global effectiveness and computational efficiency. To address these two issues, we propose meta-adaptive exploration with LLM agents https://github.com/exoskeletonzj/MAXS, a meta-adaptive reasoning framework based on LLM Agents that flexibly integrates tool execution and reasoning planning. MAXS employs a lookahead strategy to extend reasoning paths a few steps ahead, estimating the advantage value of tool usage, and combines step consistency variance and inter-step trend slopes to jointly select stable, consistent, and high-value reasoning steps. Additionally, we introduce a trajectory convergence mechanism that controls computational cost by halting further rollouts once path consistency is achieved, enabling a balance between resource efficiency and global effectiveness in multi-tool reasoning. We conduct extensive empirical studies across three base models (MiMo-VL-7B, Qwen2.5-VL-7B, Qwen2.5-VL-32B) and five datasets, demonstrating that MAXS consistently outperforms existing methods in both performance and inference efficiency. Further analysis confirms the effectiveness of our lookahead strategy and tool usage.
Risk-Aware Financial Forecasting Enhanced by Machine Learning and Intuitionistic Fuzzy Multi-Criteria Decision-Making
Dec 11, 2025In the face of increasing financial uncertainty and market complexity, this study presents a novel risk-aware financial forecasting framework that integrates advanced machine learning techniques with intuitionistic fuzzy multi-criteria decision-making (MCDM). Tailored to the BIST 100 index and validated through a case study of a major defense company in Türkiye, the framework fuses structured financial data, unstructured text data, and macroeconomic indicators to enhance predictive accuracy and robustness. It incorporates a hybrid suite of models, including extreme gradient boosting (XGBoost), long short-term memory (LSTM) network, graph neural network (GNN), to deliver probabilistic forecasts with quantified uncertainty. The empirical results demonstrate high forecasting accuracy, with a net profit mean absolute percentage error (MAPE) of 3.03% and narrow 95% confidence intervals for key financial indicators. The risk-aware analysis indicates a favorable risk-return profile, with a Sharpe ratio of 1.25 and a higher Sortino ratio of 1.80, suggesting relatively low downside volatility and robust performance under market fluctuations. Sensitivity analysis shows that the key financial indicator predictions are highly sensitive to variations of inflation, interest rates, sentiment, and exchange rates. Additionally, using an intuitionistic fuzzy MCDM approach, combining entropy weighting, evaluation based on distance from the average solution (EDAS), and the measurement of alternatives and ranking according to compromise solution (MARCOS) methods, the tabular data learning network (TabNet) outperforms the other models and is identified as the most suitable candidate for deployment. Overall, the findings of this work highlight the importance of integrating advanced machine learning, risk quantification, and fuzzy MCDM methodologies in financial forecasting, particularly in emerging markets.
Video-LMM Post-Training: A Deep Dive into Video Reasoning with Large Multimodal Models
Oct 06, 2025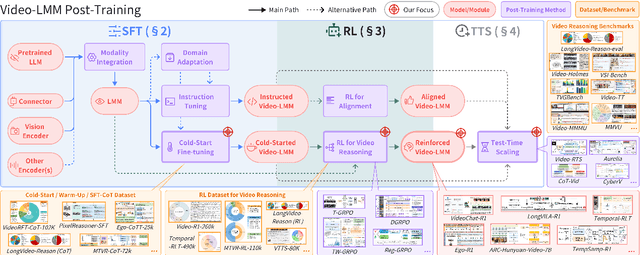
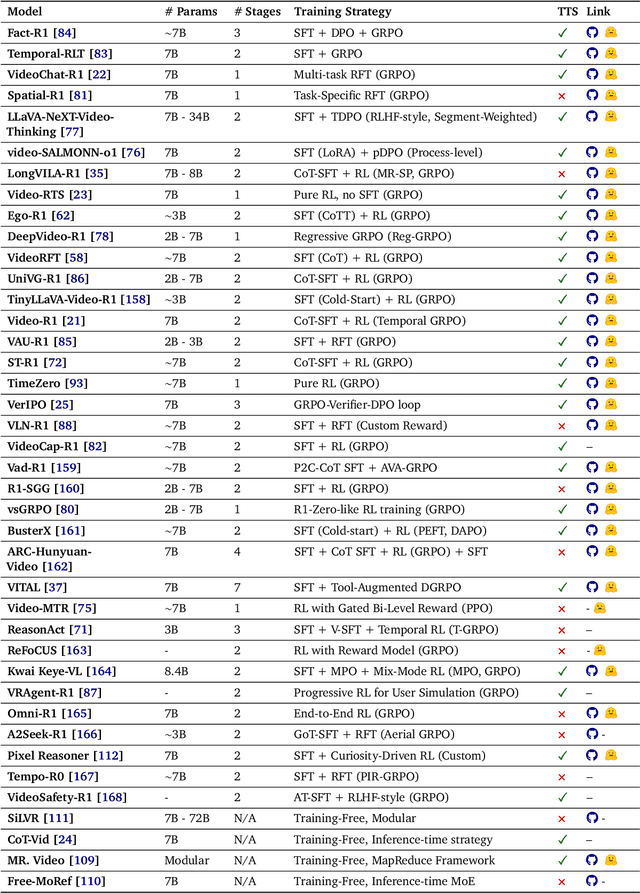
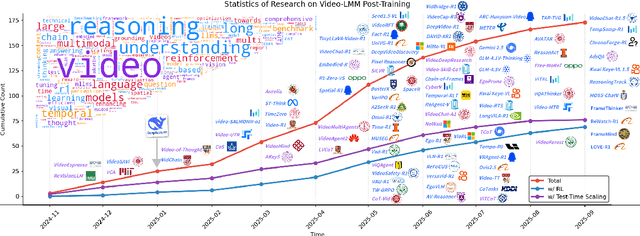
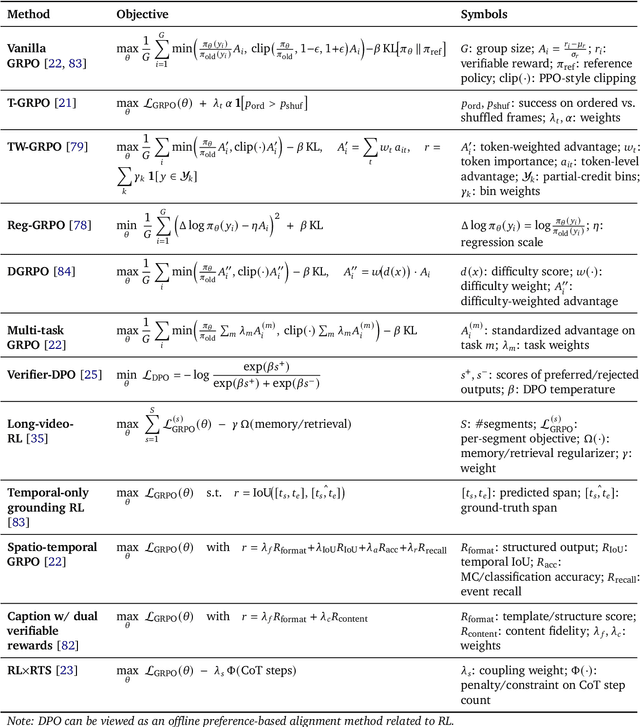
Video understanding represents the most challenging frontier in computer vision, requiring models to reason about complex spatiotemporal relationships, long-term dependencies, and multimodal evidence. The recent emergence of Video-Large Multimodal Models (Video-LMMs), which integrate visual encoders with powerful decoder-based language models, has demonstrated remarkable capabilities in video understanding tasks. However, the critical phase that transforms these models from basic perception systems into sophisticated reasoning engines, post-training, remains fragmented across the literature. This survey provides the first comprehensive examination of post-training methodologies for Video-LMMs, encompassing three fundamental pillars: supervised fine-tuning (SFT) with chain-of-thought, reinforcement learning (RL) from verifiable objectives, and test-time scaling (TTS) through enhanced inference computation. We present a structured taxonomy that clarifies the roles, interconnections, and video-specific adaptations of these techniques, addressing unique challenges such as temporal localization, spatiotemporal grounding, long video efficiency, and multimodal evidence integration. Through systematic analysis of representative methods, we synthesize key design principles, insights, and evaluation protocols while identifying critical open challenges in reward design, scalability, and cost-performance optimization. We further curate essential benchmarks, datasets, and metrics to facilitate rigorous assessment of post-training effectiveness. This survey aims to provide researchers and practitioners with a unified framework for advancing Video-LMM capabilities. Additional resources and updates are maintained at: https://github.com/yunlong10/Awesome-Video-LMM-Post-Training
Machine Learning-Assisted Surrogate Modeling with Multi-Objective Optimization and Decision-Making of a Steam Methane Reforming Reactor
Jul 10, 2025This study presents an integrated modeling and optimization framework for a steam methane reforming (SMR) reactor, combining a mathematical model, artificial neural network (ANN)-based hybrid modeling, advanced multi-objective optimization (MOO) and multi-criteria decision-making (MCDM) techniques. A one-dimensional fixed-bed reactor model accounting for internal mass transfer resistance was employed to simulate reactor performance. To reduce the high computational cost of the mathematical model, a hybrid ANN surrogate was constructed, achieving a 93.8% reduction in average simulation time while maintaining high predictive accuracy. The hybrid model was then embedded into three MOO scenarios using the non-dominated sorting genetic algorithm II (NSGA-II) solver: 1) maximizing methane conversion and hydrogen output; 2) maximizing hydrogen output while minimizing carbon dioxide emissions; and 3) a combined three-objective case. The optimal trade-off solutions were further ranked and selected using two MCDM methods: technique for order of preference by similarity to ideal solution (TOPSIS) and simplified preference ranking on the basis of ideal-average distance (sPROBID). Optimal results include a methane conversion of 0.863 with 4.556 mol/s hydrogen output in the first case, and 0.988 methane conversion with 3.335 mol/s hydrogen and 0.781 mol/s carbon dioxide in the third. This comprehensive methodology offers a scalable and effective strategy for optimizing complex catalytic reactor systems with multiple, often conflicting, objectives.