 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Practical Large-scale Dynamical Heterogeneous Graph Embedding: Cold-start Resilient Recommendation
Dec 15, 2025Deploying dynamic heterogeneous graph embeddings in production faces key challenges of scalability, data freshness, and cold-start. This paper introduces a practical, two-stage solution that balances deep graph representation with low-latency incremental updates. Our framework combines HetSGFormer, a scalable graph transformer for static learning, with Incremental Locally Linear Embedding (ILLE), a lightweight, CPU-based algorithm for real-time updates. HetSGFormer captures global structure with linear scalability, while ILLE provides rapid, targeted updates to incorporate new data, thus avoiding costly full retraining. This dual approach is cold-start resilient, leveraging the graph to create meaningful embeddings from sparse data. On billion-scale graphs, A/B tests show HetSGFormer achieved up to a 6.11% lift in Advertiser Value over previous methods, while the ILLE module added another 3.22% lift and improved embedding refresh timeliness by 83.2%. Our work provides a validated framework for deploying dynamic graph learning in production environments.
SAGA: Source Attribution of Generative AI Videos
Nov 16, 2025The proliferation of generative AI has led to hyper-realistic synthetic videos, escalating misuse risks and outstripping binary real/fake detectors. We introduce SAGA (Source Attribution of Generative AI videos), the first comprehensive framework to address the urgent need for AI-generated video source attribution at a large scale. Unlike traditional detection, SAGA identifies the specific generative model used. It uniquely provides multi-granular attribution across five levels: authenticity, generation task (e.g., T2V/I2V), model version, development team, and the precise generator, offering far richer forensic insights. Our novel video transformer architecture, leveraging features from a robust vision foundation model, effectively captures spatio-temporal artifacts. Critically, we introduce a data-efficient pretrain-and-attribute strategy, enabling SAGA to achieve state-of-the-art attribution using only 0.5\% of source-labeled data per class, matching fully supervised performance. Furthermore, we propose Temporal Attention Signatures (T-Sigs), a novel interpretability method that visualizes learned temporal differences, offering the first explanation for why different video generators are distinguishable. Extensive experiments on public datasets, including cross-domain scenarios, demonstrate that SAGA sets a new benchmark for synthetic video provenance, providing crucial, interpretable insights for forensic and regulatory applications.
Is Fine-Tuning an Effective Solution? Reassessing Knowledge Editing for Unstructured Data
Jun 11, 2025



Unstructured Knowledge Editing (UKE) is crucial for updating the relevant knowledge of large language models (LLMs). It focuses on unstructured inputs, such as long or free-form texts, which are common forms of real-world knowledge. Although previous studies have proposed effective methods and tested them, some issues exist: (1) Lack of Locality evaluation for UKE, and (2) Abnormal failure of fine-tuning (FT) based methods for UKE. To address these issues, we first construct two datasets, UnKEBench-Loc and AKEW-Loc (CF), by extending two existing UKE datasets with locality test data from the unstructured and structured views. This enables a systematic evaluation of the Locality of post-edited models. Furthermore, we identify four factors that may affect the performance of FT-based methods. Based on these factors, we conduct experiments to determine how the well-performing FT-based methods should be trained for the UKE task, providing a training recipe for future research. Our experimental results indicate that the FT-based method with the optimal setting (FT-UKE) is surprisingly strong, outperforming the existing state-of-the-art (SOTA). In batch editing scenarios, FT-UKE shows strong performance as well, with its advantage over SOTA methods increasing as the batch size grows, expanding the average metric lead from +6.78% to +10.80%
UAQFact: Evaluating Factual Knowledge Utilization of LLMs on Unanswerable Questions
May 29, 2025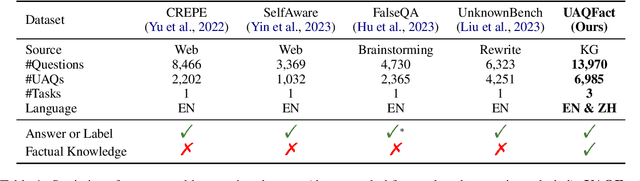



Handling unanswerable questions (UAQ) is crucial for LLMs, as it helps prevent misleading responses in complex situations. While previous studies have built several datasets to assess LLMs' performance on UAQ, these datasets lack factual knowledge support, which limits the evaluation of LLMs' ability to utilize their factual knowledge when handling UAQ. To address the limitation, we introduce a new unanswerable question dataset UAQFact, a bilingual dataset with auxiliary factual knowledge created from a Knowledge Graph. Based on UAQFact, we further define two new tasks to measure LLMs' ability to utilize internal and external factual knowledge, respectively. Our experimental results across multiple LLM series show that UAQFact presents significant challenges, as LLMs do not consistently perform well even when they have factual knowledge stored. Additionally, we find that incorporating external knowledge may enhance performance, but LLMs still cannot make full use of the knowledge which may result in incorrect responses.
AutoMat: Enabling Automated Crystal Structure Reconstruction from Microscopy via Agentic Tool Use
May 19, 2025



Machine learning-based interatomic potentials and force fields depend critically on accurate atomic structures, yet such data are scarce due to the limited availability of experimentally resolved crystals. Although atomic-resolution electron microscopy offers a potential source of structural data, converting these images into simulation-ready formats remains labor-intensive and error-prone, creating a bottleneck for model training and validation. We introduce AutoMat, an end-to-end, agent-assisted pipeline that automatically transforms scanning transmission electron microscopy (STEM) images into atomic crystal structures and predicts their physical properties. AutoMat combines pattern-adaptive denoising, physics-guided template retrieval, symmetry-aware atomic reconstruction, fast relaxation and property prediction via MatterSim, and coordinated orchestration across all stages. We propose the first dedicated STEM2Mat-Bench for this task and evaluate performance using lattice RMSD, formation energy MAE, and structure-matching success rate. By orchestrating external tool calls, AutoMat enables a text-only LLM to outperform vision-language models in this domain, achieving closed-loop reasoning throughout the pipeline. In large-scale experiments over 450 structure samples, AutoMat substantially outperforms existing multimodal large language models and tools. These results validate both AutoMat and STEM2Mat-Bench, marking a key step toward bridging microscopy and atomistic simulation in materials science.The code and dataset are publicly available at https://github.com/yyt-2378/AutoMat and https://huggingface.co/datasets/yaotianvector/STEM2Mat.
Towards a Universal Synthetic Video Detector: From Face or Background Manipulations to Fully AI-Generated Content
Dec 16, 2024



Existing DeepFake detection techniques primarily focus on facial manipulations, such as face-swapping or lip-syncing. However, advancements in text-to-video (T2V) and image-to-video (I2V) generative models now allow fully AI-generated synthetic content and seamless background alterations, challenging face-centric detection methods and demanding more versatile approaches. To address this, we introduce the \underline{U}niversal \underline{N}etwork for \underline{I}dentifying \underline{T}ampered and synth\underline{E}tic videos (\texttt{UNITE}) model, which, unlike traditional detectors, captures full-frame manipulations. \texttt{UNITE} extends detection capabilities to scenarios without faces, non-human subjects, and complex background modifications. It leverages a transformer-based architecture that processes domain-agnostic features extracted from videos via the SigLIP-So400M foundation model. Given limited datasets encompassing both facial/background alterations and T2V/I2V content, we integrate task-irrelevant data alongside standard DeepFake datasets in training. We further mitigate the model's tendency to over-focus on faces by incorporating an attention-diversity (AD) loss, which promotes diverse spatial attention across video frames. Combining AD loss with cross-entropy improves detection performance across varied contexts. Comparative evaluations demonstrate that \texttt{UNITE} outperforms state-of-the-art detectors on datasets (in cross-data settings) featuring face/background manipulations and fully synthetic T2V/I2V videos, showcasing its adaptability and generalizable detection capabilities.
Can Uncertainty Quantification Enable Better Learning-based Index Tuning?
Oct 23, 2024Index tuning is crucial for optimizing database performance by selecting optimal indexes based on workload. The key to this process lies in an accurate and efficient benefit estimator. Traditional methods relying on what-if tools often suffer from inefficiency and inaccuracy. In contrast, learning-based models provide a promising alternative but face challenges such as instability, lack of interpretability, and complex management. To overcome these limitations, we adopt a novel approach: quantifying the uncertainty in learning-based models' results, thereby combining the strengths of both traditional and learning-based methods for reliable index tuning. We propose Beauty, the first uncertainty-aware framework that enhances learning-based models with uncertainty quantification and uses what-if tools as a complementary mechanism to improve reliability and reduce management complexity. Specifically, we introduce a novel method that combines AutoEncoder and Monte Carlo Dropout to jointly quantify uncertainty, tailored to the characteristics of benefit estimation tasks. In experiments involving sixteen models, our approach outperformed existing uncertainty quantification methods in the majority of cases. We also conducted index tuning tests on six datasets. By applying the Beauty framework, we eliminated worst-case scenarios and more than tripled the occurrence of best-case scenarios.
NesTools: A Dataset for Evaluating Nested Tool Learning Abilities of Large Language Models
Oct 15, 2024Large language models (LLMs) combined with tool learning have gained impressive results in real-world applications. During tool learning, LLMs may call multiple tools in nested orders, where the latter tool call may take the former response as its input parameters. However, current research on the nested tool learning capabilities is still under-explored, since the existing benchmarks lack of relevant data instances. To address this problem, we introduce NesTools to bridge the current gap in comprehensive nested tool learning evaluations. NesTools comprises a novel automatic data generation method to construct large-scale nested tool calls with different nesting structures. With manual review and refinement, the dataset is in high quality and closely aligned with real-world scenarios. Therefore, NesTools can serve as a new benchmark to evaluate the nested tool learning abilities of LLMs. We conduct extensive experiments on 22 LLMs, and provide in-depth analyses with NesTools, which shows that current LLMs still suffer from the complex nested tool learning task.
CSS: Overcoming Pose and Scene Challenges in Crowd-Sourced 3D Gaussian Splatting
Sep 13, 2024


We introduce Crowd-Sourced Splatting (CSS), a novel 3D Gaussian Splatting (3DGS) pipeline designed to overcome the challenges of pose-free scene reconstruction using crowd-sourced imagery. The dream of reconstructing historically significant but inaccessible scenes from collections of photographs has long captivated researchers. However, traditional 3D techniques struggle with missing camera poses, limited viewpoints, and inconsistent lighting. CSS addresses these challenges through robust geometric priors and advanced illumination modeling, enabling high-quality novel view synthesis under complex, real-world conditions. Our method demonstrates clear improvements over existing approaches, paving the way for more accurate and flexible applications in AR, VR, and large-scale 3D reconstruction.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.