 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General Discrete Speech Codec for Complex Acoustic Environments: A Study of Reconstruction and Downstream Task Consistency
May 28, 2025Neural speech codecs excel in reconstructing clean speech signals; however, their efficacy in complex acoustic environments and downstream signal processing tasks remains underexplored. In this study, we introduce a novel benchmark named Environment-Resilient Speech Codec Benchmark (ERSB) to systematically evaluate whether neural speech codecs are environment-resilient. Specifically, we assess two key capabilities: (1) robust reconstruction, which measures the preservation of both speech and non-speech acoustic details, and (2) downstream task consistency, which ensures minimal deviation in downstream signal processing tasks when using reconstructed speech instead of the original. Our comprehensive experiments reveal that complex acoustic environments significantly degrade signal reconstruction and downstream task consistency. This work highlights the limitations of current speech codecs and raises a future direction that improves them for greater environmental resilience.
RUSplatting: Robust 3D Gaussian Splatting for Sparse-View Underwater Scene Reconstruction
May 21, 2025Reconstructing high-fidelity underwater scenes remains a challenging task due to light absorption, scattering, and limited visibility inherent in aquatic environments. This paper presents an enhanced Gaussian Splatting-based framework that improves both the visual quality and geometric accuracy of deep underwater rendering. We propose decoupled learning for RGB channels, guided by the physics of underwater attenuation, to enable more accurate colour restoration. To address sparse-view limitations and improve view consistency, we introduce a frame interpolation strategy with a novel adaptive weighting scheme. Additionally, we introduce a new loss function aimed at reducing noise while preserving edges, which is essential for deep-sea content. We also release a newly collected dataset, Submerged3D, captured specifically in deep-sea environments. Experimental results demonstrate that our framework consistently outperforms state-of-the-art methods with PSNR gains up to 1.90dB, delivering superior perceptual quality and robustness, and offering promising directions for marine robotics and underwater visual analytics.
A Unified Gradient-based Framework for Task-agnostic Continual Learning-Unlearning
May 21, 2025Recent advancements in deep models have highlighted the need for intelligent systems that combine continual learning (CL) for knowledge acquisition with machine unlearning (MU) for data removal, forming the Continual Learning-Unlearning (CLU) paradigm. While existing work treats CL and MU as separate processes, we reveal their intrinsic connection through a unified optimization framework based on Kullback-Leibler divergence minimization. This framework decomposes gradient updates for approximate CLU into four components: learning new knowledge, unlearning targeted data, preserving existing knowledge, and modulation via weight saliency. A critical challenge lies in balancing knowledge update and retention during sequential learning-unlearning cycles. To resolve this stability-plasticity dilemma, we introduce a remain-preserved manifold constraint to induce a remaining Hessian compensation for CLU iterations. A fast-slow weight adaptation mechanism is designed to efficiently approximate the second-order optimization direction, combined with adaptive weighting coefficients and a balanced weight saliency mask, proposing a unified implementation framework for gradient-based CLU. Furthermore, we pioneer task-agnostic CLU scenarios that support fine-grained unlearning at the cross-task category and random sample levels beyond the traditional task-aware setups. Experiments demonstrate that the proposed UG-CLU framework effectively coordinates incremental learning, precise unlearning, and knowledge stability across multiple datasets and model architectures, providing a theoretical foundation and methodological support for dynamic, compliant intelligent systems.
MIRAGE: A Multi-modal Benchmark for Spatial Perception, Reasoning, and Intelligence
May 15, 2025Spatial perception and reasoning are core components of human cognition, encompassing object recognition, spatial relational understanding, and dynamic reasoning. Despite progress in computer vision, existing benchmarks reveal significant gaps in models' abilities to accurately recognize object attributes and reason about spatial relationships, both essential for dynamic reasoning. To address these limitations, we propose MIRAGE, a multi-modal benchmark designed to evaluate models' capabilities in Counting (object attribute recognition), Relation (spatial relational reasoning), and Counting with Relation. Through diverse and complex scenarios requiring fine-grained recognition and reasoning, MIRAGE highlights critical limitations in state-of-the-art models, underscoring the need for improved representations and reasoning frameworks. By targeting these foundational abilities, MIRAGE provides a pathway toward spatiotemporal reasoning in future research.
GroverGPT-2: Simulating Grover's Algorithm via Chain-of-Thought Reasoning and Quantum-Native Tokenization
May 08, 2025Quantum computing offers theoretical advantages over classical computing for specific tasks, yet the boundary of practical quantum advantage remains an open question. To investigate this boundary, it is crucial to understand whether, and how, classical machines can learn and simulate quantum algorithms. Recent progress in large language models (LLMs) has demonstrated strong reasoning abilities, prompting exploration into their potential for this challenge. In this work, we introduce GroverGPT-2, an LLM-based method for simulating Grover's algorithm using Chain-of-Thought (CoT) reasoning and quantum-native tokenization. Building on its predecessor, GroverGPT-2 performs simulation directly from quantum circuit representations while producing logically structured and interpretable outputs. Our results show that GroverGPT-2 can learn and internalize quantum circuit logic through efficient processing of quantum-native tokens, providing direct evidence that classical models like LLMs can capture the structure of quantum algorithms. Furthermore, GroverGPT-2 outputs interleave circuit data with natural language, embedding explicit reasoning into the simulation. This dual capability positions GroverGPT-2 as a prototype for advancing machine understanding of quantum algorithms and modeling quantum circuit logic. We also identify an empirical scaling law for GroverGPT-2 with increasing qubit numbers, suggesting a path toward scalable classical simulation. These findings open new directions for exploring the limits of classical simulatability, enhancing quantum education and research, and laying groundwork for future foundation models in quantum computing.
Visual enhancement and 3D representation for underwater scenes: a review
May 03, 2025
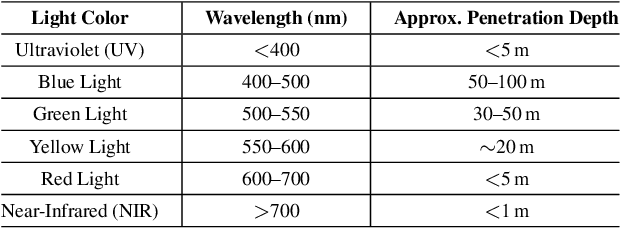


Underwater visual enhancement (UVE) and underwater 3D reconstruction pose significant challenges in computer vision and AI-based tasks due to complex imaging conditions in aquatic environments. Despite the development of numerous enhancement algorithms, a comprehensive and systematic review covering both UVE and underwater 3D reconstruction remains absent. To advance research in these areas, we present an in-depth review from multiple perspectives. First, we introduce the fundamental physical models, highlighting the peculiarities that challenge conventional techniques. We survey advanced methods for visual enhancement and 3D reconstruction specifically designed for underwater scenarios. The paper assesses various approaches from non-learning methods to advanced data-driven techniques, including Neural Radiance Fields and 3D Gaussian Splatting, discussing their effectiveness in handling underwater distortions. Finally, we conduct both quantitative and qualitative evaluations of state-of-the-art UVE and underwater 3D reconstruction algorithms across multiple benchmark datasets. Finally, we highlight key research directions for future advancements in underwater vision.
LLGS: Unsupervised Gaussian Splatting for Image Enhancement and Reconstruction in Pure Dark Environment
Mar 24, 20253D Gaussian Splatting has shown remarkable capabilities in novel view rendering tasks and exhibits significant potential for multi-view optimization.However, the original 3D Gaussian Splatting lacks color representation for inputs in low-light environments. Simply using enhanced images as inputs would lead to issues with multi-view consistency, and current single-view enhancement systems rely on pre-trained data, lacking scene generalization. These problems limit the application of 3D Gaussian Splatting in low-light conditions in the field of robotics, including high-fidelity modeling and feature matching. To address these challenges, we propose an unsupervised multi-view stereoscopic system based on Gaussian Splatting, called Low-Light Gaussian Splatting (LLGS). This system aims to enhance images in low-light environments while reconstructing the scene. Our method introduces a decomposable Gaussian representation called M-Color, which separately characterizes color information for targeted enhancement. Furthermore, we propose an unsupervised optimization method with zero-knowledge priors, using direction-based enhancement to ensure multi-view consistency. Experiments conducted on real-world datasets demonstrate that our system outperforms state-of-the-art methods in both low-light enhancement and 3D Gaussian Splatting.
Understanding the Generalization of In-Context Learning in Transformers: An Empirical Study
Mar 19, 2025Large language models (LLMs) like GPT-4 and LLaMA-3 utilize the powerful in-context learning (ICL) capability of Transformer architecture to learn on the fly from limited examples. While ICL underpins many LLM applications, its full potential remains hindered by a limited understanding of its generalization boundaries and vulnerabilities. We present a systematic investigation of transformers' generalization capability with ICL relative to training data coverage by defining a task-centric framework along three dimensions: inter-problem, intra-problem, and intra-task generalization. Through extensive simulation and real-world experiments, encompassing tasks such as function fitting, API calling, and translation, we find that transformers lack inter-problem generalization with ICL, but excel in intra-task and intra-problem generalization. When the training data includes a greater variety of mixed tasks, it significantly enhances the generalization ability of ICL on unseen tasks and even on known simple tasks. This guides us in designing training data to maximize the diversity of tasks covered and to combine different tasks whenever possible, rather than solely focusing on the target task for testing.
Understanding Driver Cognition and Decision-Making Behaviors in High-Risk Scenarios: A Drift Diffusion Perspective
Mar 16, 2025



Ensuring safe interactions between autonomous vehicles (AVs) and human drivers in mixed traffic systems remains a major challenge, particularly in complex, high-risk scenarios. This paper presents a cognition-decision framework that integrates individual variability and commonalities in driver behavior to quantify risk cognition and model dynamic decision-making. First, a risk sensitivity model based on a multivariate Gaussian distribution is developed to characterize individual differences in risk cognition. Then, a cognitive decision-making model based on the drift diffusion model (DDM) is introduced to capture common decision-making mechanisms in high-risk environments. The DDM dynamically adjusts decision thresholds by integrating initial bias, drift rate, and boundary parameters, adapting to variations in speed, relative distance, and risk sensitivity to reflect diverse driving styles and risk preferences. By simulating high-risk scenarios with lateral, longitudinal, and multidimensional risk sources in a driving simulator, the proposed model accurately predicts cognitive responses and decision behaviors during emergency maneuvers. Specifically, by incorporating driver-specific risk sensitivity, the model enables dynamic adjustments of key DDM parameters, allowing for personalized decision-making representations in diverse scenarios. Comparative analysis with IDM, Gipps, and MOBIL demonstrates that DDM more precisely captures human cognitive processes and adaptive decision-making in high-risk scenarios. These findings provide a theoretical basis for modeling human driving behavior and offer critical insights for enhancing AV-human interaction in real-world traffic environments.
WeakMedSAM: Weakly-Supervised Medical Image Segmentation via SAM with Sub-Class Exploration and Prompt Affinity Mining
Mar 06, 2025



We have witnessed remarkable progress in foundation models in vision tasks. Currently, several recent works have utilized the segmenting anything model (SAM) to boost the segmentation performance in medical images, where most of them focus on training an adaptor for fine-tuning a large amount of pixel-wise annotated medical images following a fully supervised manner. In this paper, to reduce the labeling cost, we investigate a novel weakly-supervised SAM-based segmentation model, namely WeakMedSAM. Specifically, our proposed WeakMedSAM contains two modules: 1) to mitigate severe co-occurrence in medical images, a sub-class exploration module is introduced to learn accurate feature representations. 2) to improve the quality of the class activation maps, our prompt affinity mining module utilizes the prompt capability of SAM to obtain an affinity map for random-walk refinement. Our method can be applied to any SAM-like backbone, and we conduct experiments with SAMUS and EfficientSAM. The experimental results on three popularly-used benchmark datasets, i.e., BraTS 2019, AbdomenCT-1K, and MSD Cardiac dataset, show the promising results of our proposed WeakMedSAM. Our code is available at https://github.com/wanghr64/WeakMedSAM.