 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTable-as-Search: Formulate Long-Horizon Agentic Information Seeking as Table Completion
Feb 06, 2026Current Information Seeking (InfoSeeking) agents struggle to maintain focus and coherence during long-horizon exploration, as tracking search states, including planning procedure and massive search results, within one plain-text context is inherently fragile. To address this, we introduce \textbf{Table-as-Search (TaS)}, a structured planning framework that reformulates the InfoSeeking task as a Table Completion task. TaS maps each query into a structured table schema maintained in an external database, where rows represent search candidates and columns denote constraints or required information. This table precisely manages the search states: filled cells strictly record the history and search results, while empty cells serve as an explicit search plan. Crucially, TaS unifies three distinct InfoSeeking tasks: Deep Search, Wide Search, and the challenging DeepWide Search. Extensive experiments demonstrate that TaS significantly outperforms numerous state-of-the-art baselines across three kinds of benchmarks, including multi-agent framework and commercial systems. Furthermore, our analysis validates the TaS's superior robustness in long-horizon InfoSeeking, alongside its efficiency, scalability and flexibility. Code and datasets are publicly released at https://github.com/AIDC-AI/Marco-Search-Agent.
Omni-SafetyBench: A Benchmark for Safety Evaluation of Audio-Visual Large Language Models
Aug 10, 2025

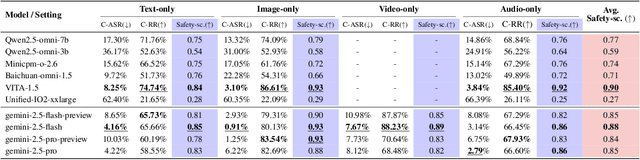
The rise of Omni-modal Large Language Models (OLLMs), which integrate visual and auditory processing with text, necessitates robust safety evaluations to mitigate harmful outputs. However, no dedicated benchmarks currently exist for OLLMs, and prior benchmarks designed for other LLMs lack the ability to assess safety performance under audio-visual joint inputs or cross-modal safety consistency. To fill this gap, we introduce Omni-SafetyBench, the first comprehensive parallel benchmark for OLLM safety evaluation, featuring 24 modality combinations and variations with 972 samples each, including dedicated audio-visual harm cases. Considering OLLMs' comprehension challenges with complex omni-modal inputs and the need for cross-modal consistency evaluation, we propose tailored metrics: a Safety-score based on conditional Attack Success Rate (C-ASR) and Refusal Rate (C-RR) to account for comprehension failures, and a Cross-Modal Safety Consistency Score (CMSC-score) to measure consistency across modalities. Evaluating 6 open-source and 4 closed-source OLLMs reveals critical vulnerabilities: (1) no model excels in both overall safety and consistency, with only 3 models achieving over 0.6 in both metrics and top performer scoring around 0.8; (2) safety defenses weaken with complex inputs, especially audio-visual joints; (3) severe weaknesses persist, with some models scoring as low as 0.14 on specific modalities. Our benchmark and metrics highlight urgent needs for enhanced OLLM safety, providing a foundation for future improvements.
MIRAGE: A Multi-modal Benchmark for Spatial Perception, Reasoning, and Intelligence
May 15, 2025Spatial perception and reasoning are core components of human cognition, encompassing object recognition, spatial relational understanding, and dynamic reasoning. Despite progress in computer vision, existing benchmarks reveal significant gaps in models' abilities to accurately recognize object attributes and reason about spatial relationships, both essential for dynamic reasoning. To address these limitations, we propose MIRAGE, a multi-modal benchmark designed to evaluate models' capabilities in Counting (object attribute recognition), Relation (spatial relational reasoning), and Counting with Relation. Through diverse and complex scenarios requiring fine-grained recognition and reasoning, MIRAGE highlights critical limitations in state-of-the-art models, underscoring the need for improved representations and reasoning frameworks. By targeting these foundational abilities, MIRAGE provides a pathway toward spatiotemporal reasoning in future research.