 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Learning for Arcing Detection in Pantograph-Catenary Systems
Feb 09, 2026The pantograph-catenary interface is essential for ensuring uninterrupted and reliable power delivery in electrified rail systems. However, electrical arcing at this interface poses serious risks, including accelerated wear of contact components, degraded system performance, and potential service disruptions. Detecting arcing events at the pantograph-catenary interface is challenging due to their transient nature, noisy operating environment, data scarcity, and the difficulty of distinguishing arcs from other similar transient phenomena. To address these challenges, we propose a novel multimodal framework that combines high-resolution image data with force measurements to more accurately and robustly detect arcing events. First, we construct two arcing detection datasets comprising synchronized visual and force measurements. One dataset is built from data provided by the Swiss Federal Railways (SBB), and the other is derived from publicly available videos of arcing events in different railway systems and synthetic force data that mimic the characteristics observed in the real dataset. Leveraging these datasets, we propose MultiDeepSAD, an extension of the DeepSAD algorithm for multiple modalities with a new loss formulation. Additionally, we introduce tailored pseudo-anomaly generation techniques specific to each data type, such as synthetic arc-like artifacts in images and simulated force irregularities, to augment training data and improve the discriminative ability of the model. Through extensive experiments and ablation studies, we demonstrate that our framework significantly outperforms baseline approaches, exhibiting enhanced sensitivity to real arcing events even under domain shifts and limited availability of real arcing observations.
User-Centric Object Navigation: A Benchmark with Integrated User Habits for Personalized Embodied Object Search
Feb 06, 2026In the evolving field of robotics, the challenge of Object Navigation (ON) in household environments has attracted significant interest. Existing ON benchmarks typically place objects in locations guided by general scene priors, without accounting for the specific placement habits of individual users. This omission limits the adaptability of navigation agents in personalized household environments. To address this, we introduce User-centric Object Navigation (UcON), a new benchmark that incorporates user-specific object placement habits, referred to as user habits. This benchmark requires agents to leverage these user habits for more informed decision-making during navigation. UcON encompasses approximately 22,600 user habits across 489 object categories. UcON is, to our knowledge, the first benchmark that explicitly formalizes and evaluates habit-conditioned object navigation at scale and covers the widest range of target object categories. Additionally, we propose a habit retrieval module to extract and utilize habits related to target objects, enabling agents to infer their likely locations more effectively. Experimental results demonstrate that current SOTA methods exhibit substantial performance degradation under habit-driven object placement, while integrating user habits consistently improves success rates. Code is available at https://github.com/whcpumpkin/User-Centric-Object-Navigation.
CADGrasp: Learning Contact and Collision Aware General Dexterous Grasping in Cluttered Scenes
Jan 21, 2026Dexterous grasping in cluttered environments presents substantial challenges due to the high degrees of freedom of dexterous hands, occlusion, and potential collisions arising from diverse object geometries and complex layouts. To address these challenges, we propose CADGrasp, a two-stage algorithm for general dexterous grasping using single-view point cloud inputs. In the first stage, we predict sparse IBS, a scene-decoupled, contact- and collision-aware representation, as the optimization target. Sparse IBS compactly encodes the geometric and contact relationships between the dexterous hand and the scene, enabling stable and collision-free dexterous grasp pose optimization. To enhance the prediction of this high-dimensional representation, we introduce an occupancy-diffusion model with voxel-level conditional guidance and force closure score filtering. In the second stage, we develop several energy functions and ranking strategies for optimization based on sparse IBS to generate high-quality dexterous grasp poses. Extensive experiments in both simulated and real-world settings validate the effectiveness of our approach, demonstrating its capability to mitigate collisions while maintaining a high grasp success rate across diverse objects and complex scenes.
A3D: Adaptive Affordance Assembly with Dual-Arm Manipulation
Jan 16, 2026Furniture assembly is a crucial yet challenging task for robots, requiring precise dual-arm coordination where one arm manipulates parts while the other provides collaborative support and stabilization. To accomplish this task more effectively, robots need to actively adapt support strategies throughout the long-horizon assembly process, while also generalizing across diverse part geometries. We propose A3D, a framework which learns adaptive affordances to identify optimal support and stabilization locations on furniture parts. The method employs dense point-level geometric representations to model part interaction patterns, enabling generalization across varied geometries. To handle evolving assembly states, we introduce an adaptive module that uses interaction feedback to dynamically adjust support strategies during assembly based on previous interactions. We establish a simulation environment featuring 50 diverse parts across 8 furniture types, designed for dual-arm collaboration evaluation. Experiments demonstrate that our framework generalizes effectively to diverse part geometries and furniture categories in both simulation and real-world settings.
ChemBART: A Pre-trained BART Model Assisting Organic Chemistry Analysis
Jan 06, 2026Recent advances in large language models (LLMs) have demonstrated transformative potential across diverse fields. While LLMs have been applied to molecular simplified molecular input line entry system (SMILES) in computer-aided synthesis planning (CASP), existing methodologies typically address single tasks, such as precursor prediction. We introduce ChemBART, a SMILES-based LLM pre-trained on chemical reactions, which enables a unified model for multiple downstream chemical tasks--achieving the paradigm of "one model, one pre-training, multiple tasks." By leveraging outputs from a mask-filling pre-training task on reaction expressions, ChemBART effectively solves a variety of chemical problems, including precursor/reagent generation, temperature-yield regression, molecular property classification, and optimizing the policy and value functions within a reinforcement learning framework, integrated with Monte Carlo tree search for multi-step synthesis route design. Unlike single-molecule pre-trained LLMs constrained to specific applications, ChemBART addresses broader chemical challenges and integrates them for comprehensive synthesis planning. Crucially, ChemBART-designed multi-step synthesis routes and reaction conditions directly inspired wet-lab validation, which confirmed shorter pathways with ~30% yield improvement over literature benchmarks. Our work validates the power of reaction-focused pre-training and showcases the broad utility of ChemBART in advancing the complete synthesis planning cycle.
TwinAligner: Visual-Dynamic Alignment Empowers Physics-aware Real2Sim2Real for Robotic Manipulation
Dec 22, 2025The robotics field is evolving towards data-driven, end-to-end learning, inspired by multimodal large models. However, reliance on expensive real-world data limits progress. Simulators offer cost-effective alternatives, but the gap between simulation and reality challenges effective policy transfer. This paper introduces TwinAligner, a novel Real2Sim2Real system that addresses both visual and dynamic gaps. The visual alignment module achieves pixel-level alignment through SDF reconstruction and editable 3DGS rendering, while the dynamic alignment module ensures dynamic consistency by identifying rigid physics from robot-object interaction. TwinAligner improves robot learning by providing scalable data collection and establishing a trustworthy iterative cycle, accelerating algorithm development. Quantitative evaluations highlight TwinAligner's strong capabilities in visual and dynamic real-to-sim alignment. This system enables policies trained in simulation to achieve strong zero-shot generalization to the real world. The high consistency between real-world and simulated policy performance underscores TwinAligner's potential to advance scalable robot learning. Code and data will be released on https://twin-aligner.github.io
Real2Edit2Real: Generating Robotic Demonstrations via a 3D Control Interface
Dec 22, 2025Recent progress in robot learning has been driven by large-scale datasets and powerful visuomotor policy architectures, yet policy robustness remains limited by the substantial cost of collecting diverse demonstrations, particularly for spatial generalization in manipulation tasks. To reduce repetitive data collection, we present Real2Edit2Real, a framework that generates new demonstrations by bridging 3D editability with 2D visual data through a 3D control interface. Our approach first reconstructs scene geometry from multi-view RGB observations with a metric-scale 3D reconstruction model. Based on the reconstructed geometry, we perform depth-reliable 3D editing on point clouds to generate new manipulation trajectories while geometrically correcting the robot poses to recover physically consistent depth, which serves as a reliable condition for synthesizing new demonstrations. Finally, we propose a multi-conditional video generation model guided by depth as the primary control signal, together with action, edge, and ray maps, to synthesize spatially augmented multi-view manipulation videos. Experiments on four real-world manipulation tasks demonstrate that policies trained on data generated from only 1-5 source demonstrations can match or outperform those trained on 50 real-world demonstrations, improving data efficiency by up to 10-50x. Moreover, experimental results on height and texture editing demonstrate the framework's flexibility and extensibility, indicating its potential to serve as a unified data generation framework.
UniTac2Pose: A Unified Approach Learned in Simulation for Category-level Visuotactile In-hand Pose Estimation
Sep 19, 2025



Accurate estimation of the in-hand pose of an object based on its CAD model is crucial in both industrial applications and everyday tasks, ranging from positioning workpieces and assembling components to seamlessly inserting devices like USB connectors. While existing methods often rely on regression, feature matching, or registration techniques, achieving high precision and generalizability to unseen CAD models remains a significant challenge. In this paper, we propose a novel three-stage framework for in-hand pose estimation. The first stage involves sampling and pre-ranking pose candidates, followed by iterative refinement of these candidates in the second stage. In the final stage, post-ranking is applied to identify the most likely pose candidates. These stages are governed by a unified energy-based diffusion model, which is trained solely on simulated data. This energy model simultaneously generates gradients to refine pose estimates and produces an energy scalar that quantifies the quality of the pose estimates. Additionally, borrowing the idea from the computer vision domain, we incorporate a render-compare architecture within the energy-based score network to significantly enhance sim-to-real performance, as demonstrated by our ablation studies. We conduct comprehensive experiments to show that our method outperforms conventional baselines based on regression, matching, and registration techniques, while also exhibiting strong intra-category generalization to previously unseen CAD models. Moreover, our approach integrates tactile object pose estimation, pose tracking, and uncertainty estimation into a unified framework, enabling robust performance across a variety of real-world conditions.
CorrectNav: Self-Correction Flywheel Empowers Vision-Language-Action Navigation Model
Aug 14, 2025Existing vision-and-language navigation models often deviate from the correct trajectory when executing instructions. However, these models lack effective error correction capability, hindering their recovery from errors. To address this challenge, we propose Self-correction Flywheel, a novel post-training paradigm. Instead of considering the model's error trajectories on the training set as a drawback, our paradigm emphasizes their significance as a valuable data source. We have developed a method to identify deviations in these error trajectories and devised innovative techniques to automatically generate self-correction data for perception and action. These self-correction data serve as fuel to power the model's continued training. The brilliance of our paradigm is revealed when we re-evaluate the model on the training set, uncovering new error trajectories. At this time, the self-correction flywheel begins to spin. Through multiple flywheel iterations, we progressively enhance our monocular RGB-based VLA navigation model CorrectNav. Experiments on R2R-CE and RxR-CE benchmarks show CorrectNav achieves new state-of-the-art success rates of 65.1% and 69.3%, surpassing prior best VLA navigation models by 8.2% and 16.4%. Real robot tests in various indoor and outdoor environments demonstrate \method's superior capability of error correction, dynamic obstacle avoidance, and long instruction following.
Adapting Vision-Language Models Without Labels: A Comprehensive Survey
Aug 07, 2025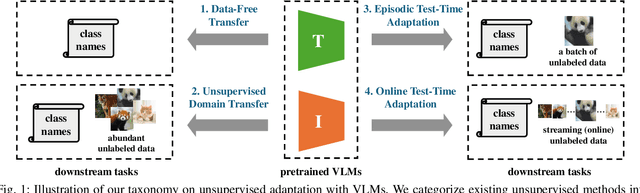
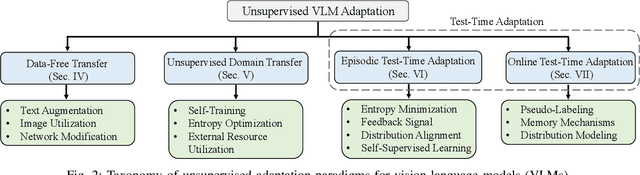
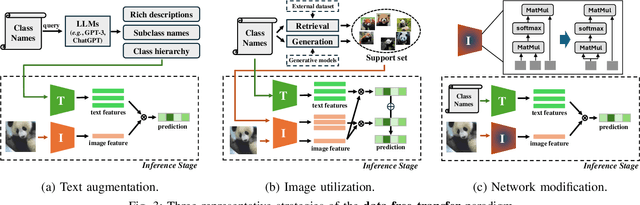
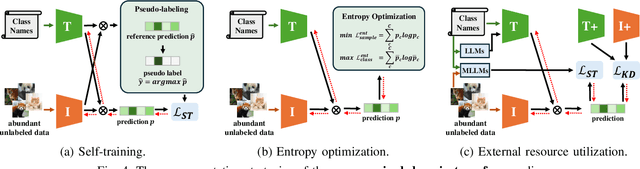
Vision-Language Models (VLMs) have demonstrated remarkable generalization capabilities across a wide range of tasks. However, their performance often remains suboptimal when directly applied to specific downstream scenarios without task-specific adaptation. To enhance their utility while preserving data efficiency, recent research has increasingly focused on unsupervised adaptation methods that do not rely on labeled data. Despite the growing interest in this area, there remains a lack of a unified, task-oriented survey dedicated to unsupervised VLM adaptation. To bridge this gap, we present a comprehensive and structured overview of the field. We propose a taxonomy based on the availability and nature of unlabeled visual data, categorizing existing approaches into four key paradigms: Data-Free Transfer (no data), Unsupervised Domain Transfer (abundant data), Episodic Test-Time Adaptation (batch data), and Online Test-Time Adaptation (streaming data). Within this framework, we analyze core methodologies and adaptation strategies associated with each paradigm, aiming to establish a systematic understanding of the field. Additionally, we review representative benchmarks across diverse applications and highlight open challenges and promising directions for future research. An actively maintained repository of relevant literature is available at https://github.com/tim-learn/Awesome-LabelFree-VLMs.