 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Single-Point Judgment: Distribution Alignment for LLM-as-a-Judge
May 18, 2025



LLMs have emerged as powerful evaluators in the LLM-as-a-Judge paradigm, offering significant efficiency and flexibility compared to human judgments. However, previous methods primarily rely on single-point evaluations, overlooking the inherent diversity and uncertainty in human evaluations. This approach leads to information loss and decreases the reliability of evaluations. To address this limitation, we propose a novel training framework that explicitly aligns the LLM-generated judgment distribution with empirical human distributions. Specifically, we propose a distributional alignment objective based on KL divergence, combined with an auxiliary cross-entropy regularization to stabilize the training process. Furthermore, considering that empirical distributions may derive from limited human annotations, we incorporate adversarial training to enhance model robustness against distribution perturbations. Extensive experiments across various LLM backbones and evaluation tasks demonstrate that our framework significantly outperforms existing closed-source LLMs and conventional single-point alignment methods, with improved alignment quality, evaluation accuracy, and robustness.
MambaControl: Anatomy Graph-Enhanced Mamba ControlNet with Fourier Refinement for Diffusion-Based Disease Trajectory Prediction
May 15, 2025Modelling disease progression in precision medicine requires capturing complex spatio-temporal dynamics while preserving anatomical integrity. Existing methods often struggle with longitudinal dependencies and structural consistency in progressive disorders. To address these limitations, we introduce MambaControl, a novel framework that integrates selective state-space modelling with diffusion processes for high-fidelity prediction of medical image trajectories. To better capture subtle structural changes over time while maintaining anatomical consistency, MambaControl combines Mamba-based long-range modelling with graph-guided anatomical control to more effectively represent anatomical correlations. Furthermore, we introduce Fourier-enhanced spectral graph representations to capture spatial coherence and multiscale detail, enabling MambaControl to achieve state-of-the-art performance in Alzheimer's disease prediction. Quantitative and regional evaluations demonstrate improved progression prediction quality and anatomical fidelity, highlighting its potential for personalised prognosis and clinical decision support.
BioVFM-21M: Benchmarking and Scaling Self-Supervised Vision Foundation Models for Biomedical Image Analysis
May 14, 2025Scaling up model and data size have demonstrated impressive performance improvement over a wide range of tasks. Despite extensive studies on scaling behaviors for general-purpose tasks, medical images exhibit substantial differences from natural data. It remains unclear the key factors in developing medical vision foundation models at scale due to the absence of an extensive understanding of scaling behavior in the medical domain. In this paper, we explored the scaling behavior across model sizes, training algorithms, data sizes, and imaging modalities in developing scalable medical vision foundation models by self-supervised learning. To support scalable pretraining, we introduce BioVFM-21M, a large-scale biomedical image dataset encompassing a wide range of biomedical image modalities and anatomies. We observed that scaling up does provide benefits but varies across tasks. Additional analysis reveals several factors correlated with scaling benefits. Finally, we propose BioVFM, a large-scale medical vision foundation model pretrained on 21 million biomedical images, which outperforms the previous state-of-the-art foundation models across 12 medical benchmarks. Our results highlight that while scaling up is beneficial for pursuing better performance, task characteristics, data diversity, pretraining methods, and computational efficiency remain critical considerations for developing scalable medical foundation models.
Learning from Peers in Reasoning Models
May 12, 2025Large Reasoning Models (LRMs) have the ability to self-correct even when they make mistakes in their reasoning paths. However, our study reveals that when the reasoning process starts with a short but poor beginning, it becomes difficult for the model to recover. We refer to this phenomenon as the "Prefix Dominance Trap". Inspired by psychological findings that peer interaction can promote self-correction without negatively impacting already accurate individuals, we propose **Learning from Peers** (LeaP) to address this phenomenon. Specifically, every tokens, each reasoning path summarizes its intermediate reasoning and shares it with others through a routing mechanism, enabling paths to incorporate peer insights during inference. However, we observe that smaller models sometimes fail to follow summarization and reflection instructions effectively. To address this, we fine-tune them into our **LeaP-T** model series. Experiments on AIME 2024, AIME 2025, AIMO 2025, and GPQA Diamond show that LeaP provides substantial improvements. For instance, QwQ-32B with LeaP achieves nearly 5 absolute points higher than the baseline on average, and surpasses DeepSeek-R1-671B on three math benchmarks with an average gain of 3.3 points. Notably, our fine-tuned LeaP-T-7B matches the performance of DeepSeek-R1-Distill-Qwen-14B on AIME 2024. In-depth analysis reveals LeaP's robust error correction by timely peer insights, showing strong error tolerance and handling varied task difficulty. LeaP marks a milestone by enabling LRMs to collaborate during reasoning. Our code, datasets, and models are available at https://learning-from-peers.github.io/ .
A Preliminary Study for GPT-4o on Image Restoration
May 08, 2025



OpenAI's GPT-4o model, integrating multi-modal inputs and outputs within an autoregressive architecture, has demonstrated unprecedented performance in image generation. In this work, we investigate its potential impact on the image restoration community. We present the first systematic evaluation of GPT-4o across diverse restoration tasks. Our experiments reveal that, although restoration outputs from GPT-4o are visually appealing, they often suffer from pixel-level structural fidelity when compared to ground-truth images. Common issues are variations in image proportions, shifts in object positions and quantities, and changes in viewpoint.To address it, taking image dehazing, derainning, and low-light enhancement as representative case studies, we show that GPT-4o's outputs can serve as powerful visual priors, substantially enhancing the performance of existing dehazing networks. It offers practical guidelines and a baseline framework to facilitate the integration of GPT-4o into future image restoration pipelines. We hope the study on GPT-4o image restoration will accelerate innovation in the broader field of image generation areas. To support further research, we will release GPT-4o-restored images from over 10 widely used image restoration datasets.
Memory Reviving, Continuing Learning and Beyond: Evaluation of Pre-trained Encoders and Decoders for Multimodal Machine Translation
Apr 25, 2025Multimodal Machine Translation (MMT) aims to improve translation quality by leveraging auxiliary modalities such as images alongside textual input. While recent advances in large-scale pre-trained language and vision models have significantly benefited unimodal natural language processing tasks, their effectiveness and role in MMT remain underexplored. In this work, we conduct a systematic study on the impact of pre-trained encoders and decoders in multimodal translation models. Specifically, we analyze how different training strategies, from training from scratch to using pre-trained and partially frozen components, affect translation performance under a unified MMT framework. Experiments are carried out on the Multi30K and CoMMuTE dataset across English-German and English-French translation tasks. Our results reveal that pre-training plays a crucial yet asymmetrical role in multimodal settings: pre-trained decoders consistently yield more fluent and accurate outputs, while pre-trained encoders show varied effects depending on the quality of visual-text alignment. Furthermore, we provide insights into the interplay between modality fusion and pre-trained components, offering guidance for future architecture design in multimodal translation systems.
Kimi-Audio Technical Report
Apr 25, 2025
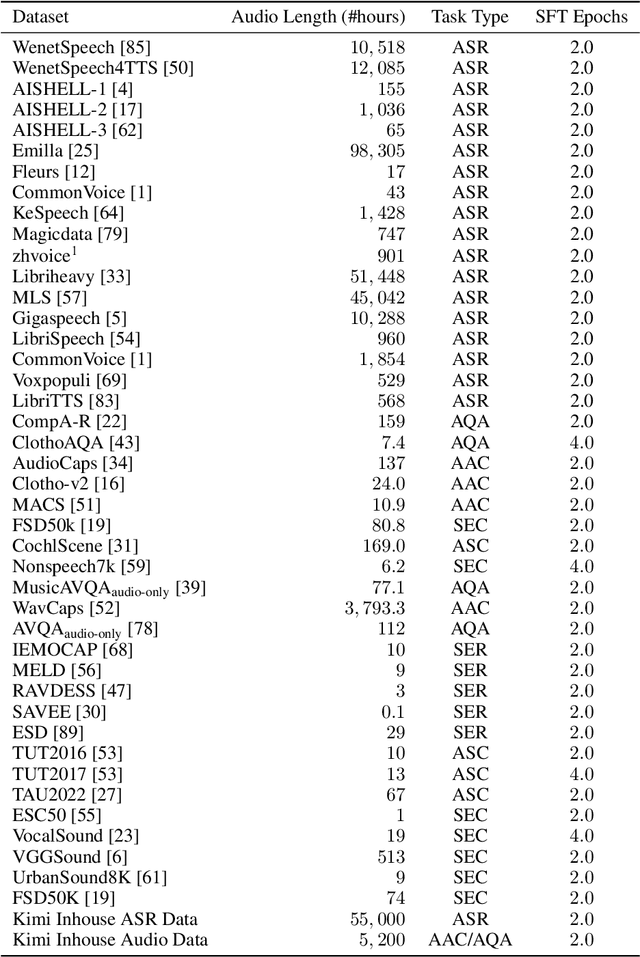
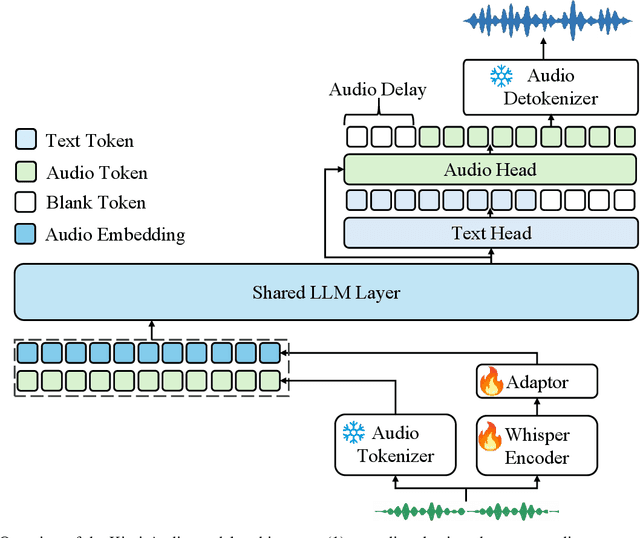
We present Kimi-Audio, an open-source audio foundation model that excels in audio understanding, generation, and conversation. We detail the practices in building Kimi-Audio, including model architecture, data curation, training recipe, inference deployment, and evaluation. Specifically, we leverage a 12.5Hz audio tokenizer, design a novel LLM-based architecture with continuous features as input and discrete tokens as output, and develop a chunk-wise streaming detokenizer based on flow matching. We curate a pre-training dataset that consists of more than 13 million hours of audio data covering a wide range of modalities including speech, sound, and music, and build a pipeline to construct high-quality and diverse post-training data. Initialized from a pre-trained LLM, Kimi-Audio is continual pre-trained on both audio and text data with several carefully designed tasks, and then fine-tuned to support a diverse of audio-related tasks. Extensive evaluation shows that Kimi-Audio achieves state-of-the-art performance on a range of audio benchmarks including speech recognition, audio understanding, audio question answering, and speech conversation. We release the codes, model checkpoints, as well as the evaluation toolkits in https://github.com/MoonshotAI/Kimi-Audio.
DIMT25@ICDAR2025: HW-TSC's End-to-End Document Image Machine Translation System Leveraging Large Vision-Language Model
Apr 24, 2025This paper presents the technical solution proposed by Huawei Translation Service Center (HW-TSC) for the "End-to-End Document Image Machine Translation for Complex Layouts" competition at the 19th International Conference on Document Analysis and Recognition (DIMT25@ICDAR2025). Leveraging state-of-the-art open-source large vision-language model (LVLM), we introduce a training framework that combines multi-task learning with perceptual chain-of-thought to develop a comprehensive end-to-end document translation system. During the inference phase, we apply minimum Bayesian decoding and post-processing strategies to further enhance the system's translation capabilities. Our solution uniquely addresses both OCR-based and OCR-free document image translation tasks within a unified framework. This paper systematically details the training methods, inference strategies, LVLM base models, training data, experimental setups, and results, demonstrating an effective approach to document image machine translation.
Evaluating Menu OCR and Translation: A Benchmark for Aligning Human and Automated Evaluations in Large Vision-Language Models
Apr 22, 2025The rapid advancement of large vision-language models (LVLMs) has significantly propelled applications in document understanding, particularly in optical character recognition (OCR) and multilingual translation. However, current evaluations of LVLMs, like the widely used OCRBench, mainly focus on verifying the correctness of their short-text responses and long-text responses with simple layout, while the evaluation of their ability to understand long texts with complex layout design is highly significant but largely overlooked. In this paper, we propose Menu OCR and Translation Benchmark (MOTBench), a specialized evaluation framework emphasizing the pivotal role of menu translation in cross-cultural communication. MOTBench requires LVLMs to accurately recognize and translate each dish, along with its price and unit items on a menu, providing a comprehensive assessment of their visual understanding and language processing capabilities. Our benchmark is comprised of a collection of Chinese and English menus, characterized by intricate layouts, a variety of fonts, and culturally specific elements across different languages, along with precise human annotations. Experiments show that our automatic evaluation results are highly consistent with professional human evaluation. We evaluate a range of publicly available state-of-the-art LVLMs, and through analyzing their output to identify the strengths and weaknesses in their performance, offering valuable insights to guide future advancements in LVLM development. MOTBench is available at https://github.com/gitwzl/MOTBench.
Automatic Evaluation Metrics for Document-level Translation: Overview, Challenges and Trends
Apr 21, 2025With the rapid development of deep learning technologies, the field of machine translation has witnessed significant progress, especially with the advent of large language models (LLMs) that have greatly propelled the advancement of document-level translation. However, accurately evaluating the quality of document-level translation remains an urgent issue. This paper first introduces the development status of document-level translation and the importance of evaluation, highlighting the crucial role of automatic evaluation metrics in reflecting translation quality and guiding the improvement of translation systems. It then provides a detailed analysis of the current state of automatic evaluation schemes and metrics, including evaluation methods with and without reference texts, as well as traditional metrics, Model-based metrics and LLM-based metrics. Subsequently, the paper explores the challenges faced by current evaluation methods, such as the lack of reference diversity, dependence on sentence-level alignment information, and the bias, inaccuracy, and lack of interpretability of the LLM-as-a-judge method. Finally, the paper looks ahead to the future trends in evaluation methods, including the development of more user-friendly document-level evaluation methods and more robust LLM-as-a-judge methods, and proposes possible research directions, such as reducing the dependency on sentence-level information, introducing multi-level and multi-granular evaluation approaches, and training models specifically for machine translation evaluation. This study aims to provide a comprehensive analysis of automatic evaluation for document-level translation and offer insights into future developments.