 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Large Language Models for Text-rich Image Understanding: A Comprehensive Review
Feb 23, 2025The recent emergence of Multi-modal Large Language Models (MLLMs) has introduced a new dimension to the Text-rich Image Understanding (TIU) field, with models demonstrating impressive and inspiring performance. However, their rapid evolution and widespread adoption have made it increasingly challenging to keep up with the latest advancements. To address this, we present a systematic and comprehensive survey to facilitate further research on TIU MLLMs. Initially, we outline the timeline, architecture, and pipeline of nearly all TIU MLLMs. Then, we review the performance of selected models on mainstream benchmarks. Finally, we explore promising directions, challenges, and limitations within the field.
Rethinking Diverse Human Preference Learning through Principal Component Analysis
Feb 18, 2025Understanding human preferences is crucial for improving foundation models and building personalized AI systems. However, preferences are inherently diverse and complex, making it difficult for traditional reward models to capture their full range. While fine-grained preference data can help, collecting it is expensive and hard to scale. In this paper, we introduce Decomposed Reward Models (DRMs), a novel approach that extracts diverse human preferences from binary comparisons without requiring fine-grained annotations. Our key insight is to represent human preferences as vectors and analyze them using Principal Component Analysis (PCA). By constructing a dataset of embedding differences between preferred and rejected responses, DRMs identify orthogonal basis vectors that capture distinct aspects of preference. These decomposed rewards can be flexibly combined to align with different user needs, offering an interpretable and scalable alternative to traditional reward models. We demonstrate that DRMs effectively extract meaningful preference dimensions (e.g., helpfulness, safety, humor) and adapt to new users without additional training. Our results highlight DRMs as a powerful framework for personalized and interpretable LLM alignment.
UniGO: A Unified Graph Neural Network for Modeling Opinion Dynamics on Graphs
Feb 17, 2025



Polarization and fragmentation in social media amplify user biases, making it increasingly important to understand the evolution of opinions. Opinion dynamics provide interpretability for studying opinion evolution, yet incorporating these insights into predictive models remains challenging. This challenge arises due to the inherent complexity of the diversity of opinion fusion rules and the difficulty in capturing equilibrium states while avoiding over-smoothing. This paper constructs a unified opinion dynamics model to integrate different opinion fusion rules and generates corresponding synthetic datasets. To fully leverage the advantages of unified opinion dynamics, we introduces UniGO, a framework for modeling opinion evolution on graphs. Using a coarsen-refine mechanism, UniGO efficiently models opinion dynamics through a graph neural network, mitigating over-smoothing while preserving equilibrium phenomena. UniGO leverages pretraining on synthetic datasets, which enhances its ability to generalize to real-world scenarios, providing a viable paradigm for applications of opinion dynamics. Experimental results on both synthetic and real-world datasets demonstrate UniGO's effectiveness in capturing complex opinion formation processes and predicting future evolution. The pretrained model also shows strong generalization capability, validating the benefits of using synthetic data to boost real-world performance.
Reviving The Classics: Active Reward Modeling in Large Language Model Alignment
Feb 04, 2025



Building neural reward models from human preferences is a pivotal component in reinforcement learning from human feedback (RLHF) and large language model alignment research. Given the scarcity and high cost of human annotation, how to select the most informative pairs to annotate is an essential yet challenging open problem. In this work, we highlight the insight that an ideal comparison dataset for reward modeling should balance exploration of the representation space and make informative comparisons between pairs with moderate reward differences. Technically, challenges arise in quantifying the two objectives and efficiently prioritizing the comparisons to be annotated. To address this, we propose the Fisher information-based selection strategies, adapt theories from the classical experimental design literature, and apply them to the final linear layer of the deep neural network-based reward modeling tasks. Empirically, our method demonstrates remarkable performance, high computational efficiency, and stability compared to other selection methods from deep learning and classical statistical literature across multiple open-source LLMs and datasets. Further ablation studies reveal that incorporating cross-prompt comparisons in active reward modeling significantly enhances labeling efficiency, shedding light on the potential for improved annotation strategies in RLHF.
Reusing Embeddings: Reproducible Reward Model Research in Large Language Model Alignment without GPUs
Feb 04, 2025



Large Language Models (LLMs) have made substantial strides in structured tasks through Reinforcement Learning (RL), demonstrating proficiency in mathematical reasoning and code generation. However, applying RL in broader domains like chatbots and content generation -- through the process known as Reinforcement Learning from Human Feedback (RLHF) -- presents unique challenges. Reward models in RLHF are critical, acting as proxies that evaluate the alignment of LLM outputs with human intent. Despite advancements, the development of reward models is hindered by challenges such as computational heavy training, costly evaluation, and therefore poor reproducibility. We advocate for using embedding-based input in reward model research as an accelerated solution to those challenges. By leveraging embeddings for reward modeling, we can enhance reproducibility, reduce computational demands on hardware, improve training stability, and significantly reduce training and evaluation costs, hence facilitating fair and efficient comparisons in this active research area. We then show a case study of reproducing existing reward model ensemble research using embedding-based reward models. We discussed future avenues for research, aiming to contribute to safer and more effective LLM deployments.
MultiPDENet: PDE-embedded Learning with Multi-time-stepping for Accelerated Flow Simulation
Jan 27, 2025Solving partial differential equations (PDEs) by numerical methods meet computational cost challenge for getting the accurate solution since fine grids and small time steps are required. Machine learning can accelerate this process, but struggle with weak generalizability, interpretability, and data dependency, as well as suffer in long-term prediction. To this end, we propose a PDE-embedded network with multiscale time stepping (MultiPDENet), which fuses the scheme of numerical methods and machine learning, for accelerated simulation of flows. In particular, we design a convolutional filter based on the structure of finite difference stencils with a small number of parameters to optimize, which estimates the equivalent form of spatial derivative on a coarse grid to minimize the equation's residual. A Physics Block with a 4th-order Runge-Kutta integrator at the fine time scale is established that embeds the structure of PDEs to guide the prediction. To alleviate the curse of temporal error accumulation in long-term prediction, we introduce a multiscale time integration approach, where a neural network is used to correct the prediction error at a coarse time scale. Experiments across various PDE systems, including the Navier-Stokes equations, demonstrate that MultiPDENet can accurately predict long-term spatiotemporal dynamics, even given small and incomplete training data, e.g., spatiotemporally down-sampled datasets. MultiPDENet achieves the state-of-the-art performance compared with other neural baseline models, also with clear speedup compared to classical numerical methods.
A Support Vector Approach in Segmented Regression for Map-assisted Non-cooperative Source Localization
Jan 08, 2025This paper presents a non-cooperative source localization approach based on received signal strength (RSS) and 2D environment map, considering both line-of-sight (LOS) and non-line-of-sight (NLOS) conditions. Conventional localization methods, e.g., weighted centroid localization (WCL), may perform bad. This paper proposes a segmented regression approach using 2D maps to estimate source location and propagation environment jointly. By leveraging topological information from the 2D maps, a support vector-assisted algorithm is developed to solve the segmented regression problem, separate the LOS and NLOS measurements, and estimate the location of source. The proposed method demonstrates a good localization performance with an improvement of over 30% in localization rooted mean squared error (RMSE) compared to the baseline methods.
GeAR: Generation Augmented Retrieval
Jan 06, 2025



Document retrieval techniques form the foundation for the development of large-scale information systems. The prevailing methodology is to construct a bi-encoder and compute the semantic similarity. However, such scalar similarity is difficult to reflect enough information and impedes our comprehension of the retrieval results. In addition, this computational process mainly emphasizes the global semantics and ignores the fine-grained semantic relationship between the query and the complex text in the document. In this paper, we propose a new method called $\textbf{Ge}$neration $\textbf{A}$ugmented $\textbf{R}$etrieval ($\textbf{GeAR}$) that incorporates well-designed fusion and decoding modules. This enables GeAR to generate the relevant text from documents based on the fused representation of the query and the document, thus learning to "focus on" the fine-grained information. Also when used as a retriever, GeAR does not add any computational burden over bi-encoders. To support the training of the new framework, we have introduced a pipeline to efficiently synthesize high-quality data by utilizing large language models. GeAR exhibits competitive retrieval and localization performance across diverse scenarios and datasets. Moreover, the qualitative analysis and the results generated by GeAR provide novel insights into the interpretation of retrieval results. The code, data, and models will be released after completing technical review to facilitate future research.
Conservation-informed Graph Learning for Spatiotemporal Dynamics Prediction
Dec 30, 2024



Data-centric methods have shown great potential in understanding and predicting spatiotemporal dynamics, enabling better design and control of the object system. However, pure deep learning models often lack interpretability, fail to obey intrinsic physics, and struggle to cope with the various domains. While geometry-based methods, e.g., graph neural networks (GNNs), have been proposed to further tackle these challenges, they still need to find the implicit physical laws from large datasets and rely excessively on rich labeled data. In this paper, we herein introduce the conservation-informed GNN (CiGNN), an end-to-end explainable learning framework, to learn spatiotemporal dynamics based on limited training data. The network is designed to conform to the general conservation law via symmetry, where conservative and non-conservative information passes over a multiscale space enhanced by a latent temporal marching strategy. The efficacy of our model has been verified in various spatiotemporal systems based on synthetic and real-world datasets, showing superiority over baseline models. Results demonstrate that CiGNN exhibits remarkable accuracy and generalization ability, and is readily applicable to learning for prediction of various spatiotemporal dynamics in a spatial domain with complex geometry.
LiveIdeaBench: Evaluating LLMs' Scientific Creativity and Idea Generation with Minimal Context
Dec 23, 2024

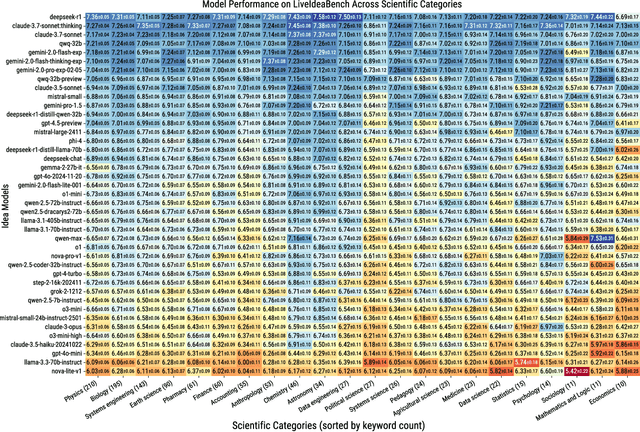
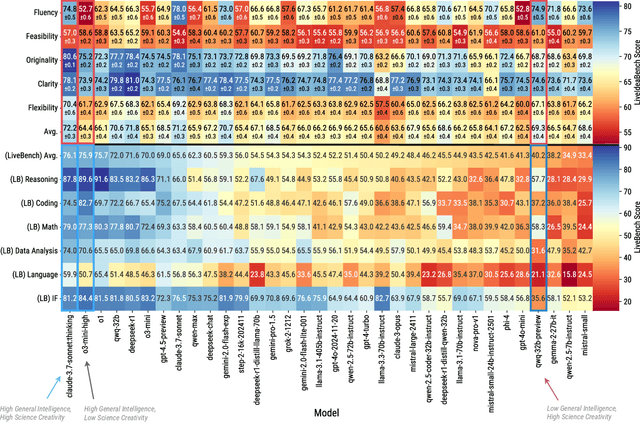
While Large Language Models (LLMs) have demonstrated remarkable capabilities in scientific tasks, existing evaluation frameworks primarily assess their performance using rich contextual inputs, overlooking their ability to generate novel ideas from minimal information. We introduce LiveIdeaBench, a comprehensive benchmark that evaluates LLMs' scientific creativity and divergent thinking capabilities using single-keyword prompts. Drawing from Guilford's creativity theory, our framework employs a dynamic panel of state-of-the-art LLMs to assess generated ideas across four key dimensions: originality, feasibility, fluency, and flexibility. Through extensive experimentation with 20 leading models across 1,180 keywords spanning 18 scientific domains, we reveal that scientific creative ability shows distinct patterns from general intelligence metrics. Notably, our results demonstrate that models like QwQ-32B-preview achieve comparable creative performance to top-tier models like o1-preview, despite significant gaps in their general intelligence scores. These findings highlight the importance of specialized evaluation frameworks for scientific creativity and suggest that the development of creative capabilities in LLMs may follow different trajectories than traditional problem-solving abilities.