 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePianoFlow: Music-Aware Streaming Piano Motion Generation with Bimanual Coordination
Apr 14, 2026Audio-driven bimanual piano motion generation requires precise modeling of complex musical structures and dynamic cross-hand coordination. However, existing methods often rely on acoustic-only representations lacking symbolic priors, employ inflexible interaction mechanisms, and are limited to computationally expensive short-sequence generation. To address these limitations, we propose PianoFlow, a flow-matching framework for precise and coordinated bimanual piano motion synthesis. Our approach strategically leverages MIDI as a privileged modality during training, distilling these structured musical priors to achieve deep semantic understanding while maintaining audio-only inference. Furthermore, we introduce an asymmetric role-gated interaction module to explicitly capture dynamic cross-hand coordination through role-aware attention and temporal gating. To enable real-time streaming generation for arbitrarily long sequences, we design an autoregressive flow continuation scheme that ensures seamless cross-chunk temporal coherence. Extensive experiments on the PianoMotion10M dataset demonstrate that PianoFlow achieves superior quantitative and qualitative performance, while accelerating inference by over 9\times compared to previous methods.
X-MoGen: Unified Motion Generation across Humans and Animals
Aug 07, 2025Text-driven motion generation has attracted increasing attention due to its broad applications in virtual reality, animation, and robotics. While existing methods typically model human and animal motion separately, a joint cross-species approach offers key advantages, such as a unified representation and improved generalization. However, morphological differences across species remain a key challenge, often compromising motion plausibility. To address this, we propose \textbf{X-MoGen}, the first unified framework for cross-species text-driven motion generation covering both humans and animals. X-MoGen adopts a two-stage architecture. First, a conditional graph variational autoencoder learns canonical T-pose priors, while an autoencoder encodes motion into a shared latent space regularized by morphological loss. In the second stage, we perform masked motion modeling to generate motion embeddings conditioned on textual descriptions. During training, a morphological consistency module is employed to promote skeletal plausibility across species. To support unified modeling, we construct \textbf{UniMo4D}, a large-scale dataset of 115 species and 119k motion sequences, which integrates human and animal motions under a shared skeletal topology for joint training. Extensive experiments on UniMo4D demonstrate that X-MoGen outperforms state-of-the-art methods on both seen and unseen species.
Benchmarking LLMs' Swarm intelligence
May 07, 2025



Large Language Models (LLMs) show potential for complex reasoning, yet their capacity for emergent coordination in Multi-Agent Systems (MAS) when operating under strict constraints-such as limited local perception and communication, characteristic of natural swarms-remains largely unexplored, particularly concerning the nuances of swarm intelligence. Existing benchmarks often do not fully capture the unique challenges of decentralized coordination that arise when agents operate with incomplete spatio-temporal information. To bridge this gap, we introduce SwarmBench, a novel benchmark designed to systematically evaluate the swarm intelligence capabilities of LLMs acting as decentralized agents. SwarmBench features five foundational MAS coordination tasks within a configurable 2D grid environment, forcing agents to rely primarily on local sensory input (k x k view) and local communication. We propose metrics for coordination effectiveness and analyze emergent group dynamics. Evaluating several leading LLMs in a zero-shot setting, we find significant performance variations across tasks, highlighting the difficulties posed by local information constraints. While some coordination emerges, results indicate limitations in robust planning and strategy formation under uncertainty in these decentralized scenarios. Assessing LLMs under swarm-like conditions is crucial for realizing their potential in future decentralized systems. We release SwarmBench as an open, extensible toolkit-built upon a customizable and scalable physical system with defined mechanical properties. It provides environments, prompts, evaluation scripts, and the comprehensive experimental datasets generated, aiming to foster reproducible research into LLM-based MAS coordination and the theoretical underpinnings of Embodied MAS. Our code repository is available at https://github.com/x66ccff/swarmbench.
LiveIdeaBench: Evaluating LLMs' Scientific Creativity and Idea Generation with Minimal Context
Dec 23, 2024

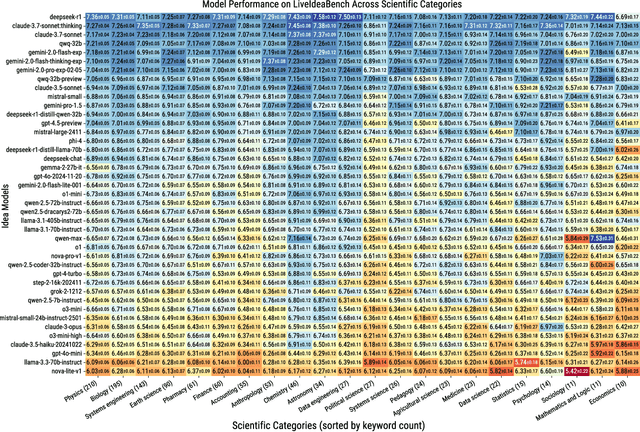
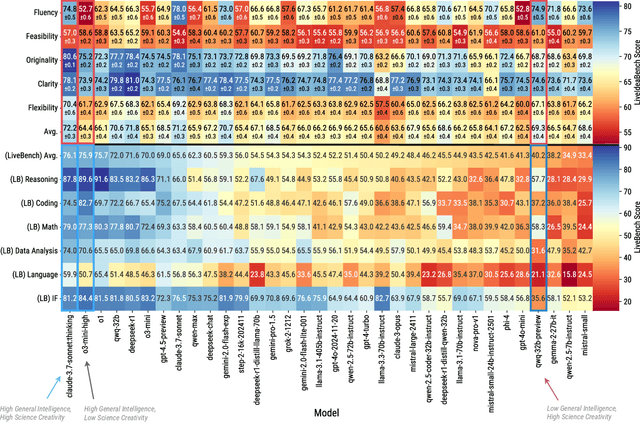
While Large Language Models (LLMs) have demonstrated remarkable capabilities in scientific tasks, existing evaluation frameworks primarily assess their performance using rich contextual inputs, overlooking their ability to generate novel ideas from minimal information. We introduce LiveIdeaBench, a comprehensive benchmark that evaluates LLMs' scientific creativity and divergent thinking capabilities using single-keyword prompts. Drawing from Guilford's creativity theory, our framework employs a dynamic panel of state-of-the-art LLMs to assess generated ideas across four key dimensions: originality, feasibility, fluency, and flexibility. Through extensive experimentation with 20 leading models across 1,180 keywords spanning 18 scientific domains, we reveal that scientific creative ability shows distinct patterns from general intelligence metrics. Notably, our results demonstrate that models like QwQ-32B-preview achieve comparable creative performance to top-tier models like o1-preview, despite significant gaps in their general intelligence scores. These findings highlight the importance of specialized evaluation frameworks for scientific creativity and suggest that the development of creative capabilities in LLMs may follow different trajectories than traditional problem-solving abilities.
Discovering symbolic expressions with parallelized tree search
Jul 05, 2024Symbolic regression plays a crucial role in modern scientific research thanks to its capability of discovering concise and interpretable mathematical expressions from data. A grand challenge lies in the arduous search for parsimonious and generalizable mathematical formulas, in an infinite search space, while intending to fit the training data. Existing algorithms have faced a critical bottleneck of accuracy and efficiency over a decade when handling problems of complexity, which essentially hinders the pace of applying symbolic regression for scientific exploration across interdisciplinary domains. To this end, we introduce a parallelized tree search (PTS) model to efficiently distill generic mathematical expressions from limited data. Through a series of extensive experiments, we demonstrate the superior accuracy and efficiency of PTS for equation discovery, which greatly outperforms the state-of-the-art baseline models on over 80 synthetic and experimental datasets (e.g., lifting its performance by up to 99% accuracy improvement and one-order of magnitude speed up). PTS represents a key advance in accurate and efficient data-driven discovery of symbolic, interpretable models (e.g., underlying physical laws) and marks a pivotal transition towards scalable symbolic learning.