 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-ODE: Ricci Curvature Tells When You Will be Informed
May 27, 2024


Information diffusion prediction is fundamental to understand the structure and organization of the online social networks, and plays a crucial role to blocking rumor spread, influence maximization, political propaganda, etc. So far, most existing solutions primarily predict the next user who will be informed with historical cascades, but ignore an important factor in the diffusion process - the time. Such limitation motivates us to pose the problem of the time-aware personalized information diffusion prediction for the first time, telling the time when the target user will be informed. In this paper, we address this problem from a fresh geometric perspective of Ricci curvature, and propose a novel Ricci-curvature regulated Ordinary Differential Equation (R-ODE). In the diffusion process, R-ODE considers that the inter-correlated users are organized in a dynamic system in the representation space, and the cascades give the observations sampled from the continuous realm. At each infection time, the message diffuses along the largest Ricci curvature, signifying less transportation effort. In the continuous realm, the message triggers users' movement, whose trajectory in the space is parameterized by an ODE with graph neural network. Consequently, R-ODE predicts the infection time of a target user by the movement trajectory learnt from the observations. Extensive experiments evaluate the personalized time prediction ability of R-ODE, and show R-ODE outperforms the state-of-the-art baselines.
LSEnet: Lorentz Structural Entropy Neural Network for Deep Graph Clustering
May 20, 2024



Graph clustering is a fundamental problem in machine learning. Deep learning methods achieve the state-of-the-art results in recent years, but they still cannot work without predefined cluster numbers. Such limitation motivates us to pose a more challenging problem of graph clustering with unknown cluster number. We propose to address this problem from a fresh perspective of graph information theory (i.e., structural information). In the literature, structural information has not yet been introduced to deep clustering, and its classic definition falls short of discrete formulation and modeling node features. In this work, we first formulate a differentiable structural information (DSI) in the continuous realm, accompanied by several theoretical results. By minimizing DSI, we construct the optimal partitioning tree where densely connected nodes in the graph tend to have the same assignment, revealing the cluster structure. DSI is also theoretically presented as a new graph clustering objective, not requiring the predefined cluster number. Furthermore, we design a neural LSEnet in the Lorentz model of hyperbolic space, where we integrate node features to structural information via manifold-valued graph convolution. Extensive empirical results on real graphs show the superiority of our approach.
SeBot: Structural Entropy Guided Multi-View Contrastive Learning for Social Bot Detection
May 18, 2024



Recent advancements in social bot detection have been driven by the adoption of Graph Neural Networks. The social graph, constructed from social network interactions, contains benign and bot accounts that influence each other. However, previous graph-based detection methods that follow the transductive message-passing paradigm may not fully utilize hidden graph information and are vulnerable to adversarial bot behavior. The indiscriminate message passing between nodes from different categories and communities results in excessively homogeneous node representations, ultimately reducing the effectiveness of social bot detectors. In this paper, we propose SEBot, a novel multi-view graph-based contrastive learning-enabled social bot detector. In particular, we use structural entropy as an uncertainty metric to optimize the entire graph's structure and subgraph-level granularity, revealing the implicitly existing hierarchical community structure. And we design an encoder to enable message passing beyond the homophily assumption, enhancing robustness to adversarial behaviors of social bots. Finally, we employ multi-view contrastive learning to maximize mutual information between different views and enhance the detection performance through multi-task learning. Experimental results demonstrate that our approach significantly improves the performance of social bot detection compared with SOTA methods.
Event GDR: Event-Centric Generative Document Retrieval
May 11, 2024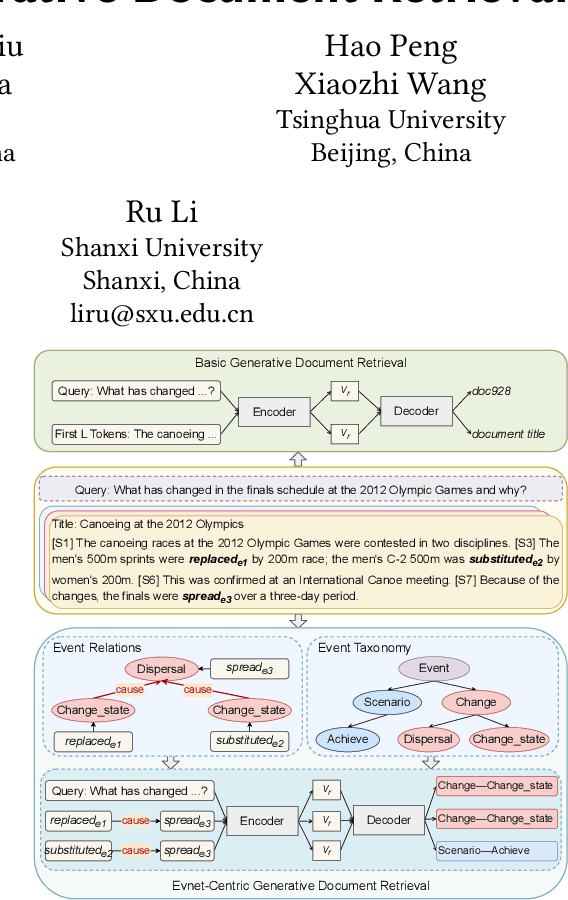
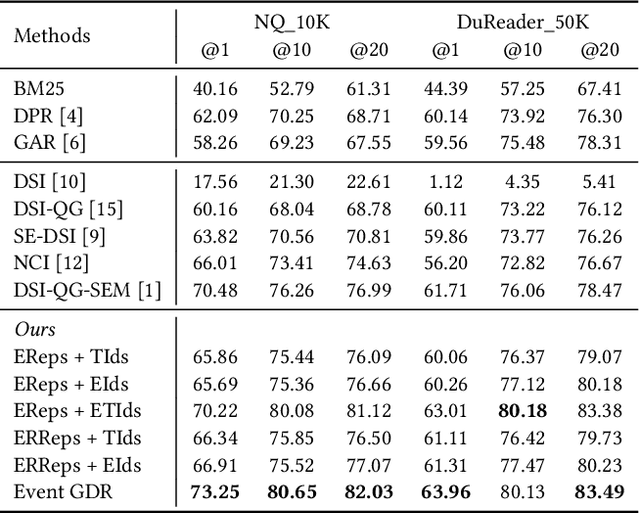
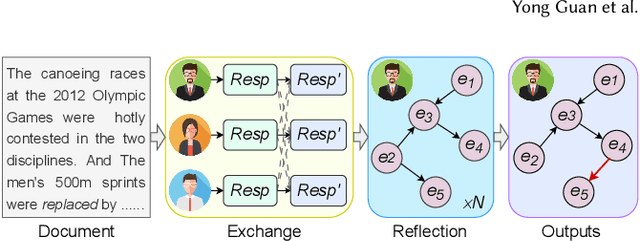
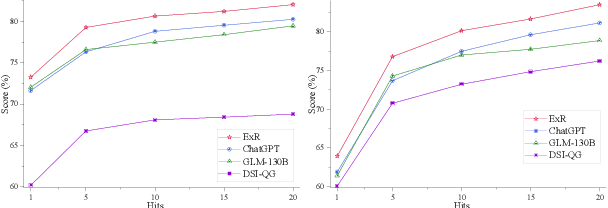
Generative document retrieval, an emerging paradigm in information retrieval, learns to build connections between documents and identifiers within a single model, garnering significant attention. However, there are still two challenges: (1) neglecting inner-content correlation during document representation; (2) lacking explicit semantic structure during identifier construction. Nonetheless, events have enriched relations and well-defined taxonomy, which could facilitate addressing the above two challenges. Inspired by this, we propose Event GDR, an event-centric generative document retrieval model, integrating event knowledge into this task. Specifically, we utilize an exchange-then-reflection method based on multi-agents for event knowledge extraction. For document representation, we employ events and relations to model the document to guarantee the comprehensiveness and inner-content correlation. For identifier construction, we map the events to well-defined event taxonomy to construct the identifiers with explicit semantic structure. Our method achieves significant improvement over the baselines on two datasets, and also hopes to provide insights for future research.
ADELIE: Aligning Large Language Models on Information Extraction
May 08, 2024Large language models (LLMs) usually fall short on information extraction (IE) tasks and struggle to follow the complex instructions of IE tasks. This primarily arises from LLMs not being aligned with humans, as mainstream alignment datasets typically do not include IE data. In this paper, we introduce ADELIE (Aligning large language moDELs on Information Extraction), an aligned LLM that effectively solves various IE tasks, including closed IE, open IE, and on-demand IE. We first collect and construct a high-quality alignment corpus IEInstruct for IE. Then we train ADELIE_SFT using instruction tuning on IEInstruct. We further train ADELIE_SFT with direct preference optimization (DPO) objective, resulting in ADELIE_DPO. Extensive experiments on various held-out IE datasets demonstrate that our models (ADELIE_SFT and ADELIE_DPO) achieve state-of-the-art (SoTA) performance among open-source models. We further explore the general capabilities of ADELIE, and experimental results reveal that their general capabilities do not exhibit a noticeable decline. We will release the code, data, and models to facilitate further research.
Hyperbolic Geometric Latent Diffusion Model for Graph Generation
May 06, 2024Diffusion models have made significant contributions to computer vision, sparking a growing interest in the community recently regarding the application of them to graph generation. Existing discrete graph diffusion models exhibit heightened computational complexity and diminished training efficiency. A preferable and natural way is to directly diffuse the graph within the latent space. However, due to the non-Euclidean structure of graphs is not isotropic in the latent space, the existing latent diffusion models effectively make it difficult to capture and preserve the topological information of graphs. To address the above challenges, we propose a novel geometrically latent diffusion framework HypDiff. Specifically, we first establish a geometrically latent space with interpretability measures based on hyperbolic geometry, to define anisotropic latent diffusion processes for graphs. Then, we propose a geometrically latent diffusion process that is constrained by both radial and angular geometric properties, thereby ensuring the preservation of the original topological properties in the generative graphs. Extensive experimental results demonstrate the superior effectiveness of HypDiff for graph generation with various topologies.
BotDGT: Dynamicity-aware Social Bot Detection with Dynamic Graph Transformers
Apr 24, 2024



Detecting social bots has evolved into a pivotal yet intricate task, aimed at combating the dissemination of misinformation and preserving the authenticity of online interactions. While earlier graph-based approaches, which leverage topological structure of social networks, yielded notable outcomes, they overlooked the inherent dynamicity of social networks -- In reality, they largely depicted the social network as a static graph and solely relied on its most recent state. Due to the absence of dynamicity modeling, such approaches are vulnerable to evasion, particularly when advanced social bots interact with other users to camouflage identities and escape detection. To tackle these challenges, we propose BotDGT, a novel framework that not only considers the topological structure, but also effectively incorporates dynamic nature of social network. Specifically, we characterize a social network as a dynamic graph. A structural module is employed to acquire topological information from each historical snapshot. Additionally, a temporal module is proposed to integrate historical context and model the evolving behavior patterns exhibited by social bots and legitimate users. Experimental results demonstrate the superiority of BotDGT against the leading methods that neglected the dynamic nature of social networks in terms of accuracy, recall, and F1-score.
Retrieval Head Mechanistically Explains Long-Context Factuality
Apr 24, 2024



Despite the recent progress in long-context language models, it remains elusive how transformer-based models exhibit the capability to retrieve relevant information from arbitrary locations within the long context. This paper aims to address this question. Our systematic investigation across a wide spectrum of models reveals that a special type of attention heads are largely responsible for retrieving information, which we dub retrieval heads. We identify intriguing properties of retrieval heads:(1) universal: all the explored models with long-context capability have a set of retrieval heads; (2) sparse: only a small portion (less than 5\%) of the attention heads are retrieval. (3) intrinsic: retrieval heads already exist in models pretrained with short context. When extending the context length by continual pretraining, it is still the same set of heads that perform information retrieval. (4) dynamically activated: take Llama-2 7B for example, 12 retrieval heads always attend to the required information no matter how the context is changed. The rest of the retrieval heads are activated in different contexts. (5) causal: completely pruning retrieval heads leads to failure in retrieving relevant information and results in hallucination, while pruning random non-retrieval heads does not affect the model's retrieval ability. We further show that retrieval heads strongly influence chain-of-thought (CoT) reasoning, where the model needs to frequently refer back the question and previously-generated context. Conversely, tasks where the model directly generates the answer using its intrinsic knowledge are less impacted by masking out retrieval heads. These observations collectively explain which internal part of the model seeks information from the input tokens. We believe our insights will foster future research on reducing hallucination, improving reasoning, and compressing the KV cache.
Effective Reinforcement Learning Based on Structural Information Principles
Apr 15, 2024Although Reinforcement Learning (RL) algorithms acquire sequential behavioral patterns through interactions with the environment, their effectiveness in noisy and high-dimensional scenarios typically relies on specific structural priors. In this paper, we propose a novel and general Structural Information principles-based framework for effective Decision-Making, namely SIDM, approached from an information-theoretic perspective. This paper presents a specific unsupervised partitioning method that forms vertex communities in the state and action spaces based on their feature similarities. An aggregation function, which utilizes structural entropy as the vertex weight, is devised within each community to obtain its embedding, thereby facilitating hierarchical state and action abstractions. By extracting abstract elements from historical trajectories, a directed, weighted, homogeneous transition graph is constructed. The minimization of this graph's high-dimensional entropy leads to the generation of an optimal encoding tree. An innovative two-layer skill-based learning mechanism is introduced to compute the common path entropy of each state transition as its identified probability, thereby obviating the requirement for expert knowledge. Moreover, SIDM can be flexibly incorporated into various single-agent and multi-agent RL algorithms, enhancing their performance. Finally, extensive evaluations on challenging benchmarks demonstrate that, compared with SOTA baselines, our framework significantly and consistently improves the policy's quality, stability, and efficiency up to 32.70%, 88.26%, and 64.86%, respectively.
Relational Prompt-based Pre-trained Language Models for Social Event Detection
Apr 12, 2024Social Event Detection (SED) aims to identify significant events from social streams, and has a wide application ranging from public opinion analysis to risk management. In recent years, Graph Neural Network (GNN) based solutions have achieved state-of-the-art performance. However, GNN-based methods often struggle with noisy and missing edges between messages, affecting the quality of learned message embedding. Moreover, these methods statically initialize node embedding before training, which, in turn, limits the ability to learn from message texts and relations simultaneously. In this paper, we approach social event detection from a new perspective based on Pre-trained Language Models (PLMs), and present RPLM_SED (Relational prompt-based Pre-trained Language Models for Social Event Detection). We first propose a new pairwise message modeling strategy to construct social messages into message pairs with multi-relational sequences. Secondly, a new multi-relational prompt-based pairwise message learning mechanism is proposed to learn more comprehensive message representation from message pairs with multi-relational prompts using PLMs. Thirdly, we design a new clustering constraint to optimize the encoding process by enhancing intra-cluster compactness and inter-cluster dispersion, making the message representation more distinguishable. We evaluate the RPLM_SED on three real-world datasets, demonstrating that the RPLM_SED model achieves state-of-the-art performance in offline, online, low-resource, and long-tail distribution scenarios for social event detection tasks.