 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Universe: Scale Real-World Verifiable Environments to Millions
Feb 02, 2026We propose SWE-Universe, a scalable and efficient framework for automatically constructing real-world software engineering (SWE) verifiable environments from GitHub pull requests (PRs). To overcome the prevalent challenges of automatic building, such as low production yield, weak verifiers, and prohibitive cost, our framework utilizes a building agent powered by an efficient custom-trained model. This agent employs iterative self-verification and in-loop hacking detection to ensure the reliable generation of high-fidelity, verifiable tasks. Using this method, we scale the number of real-world multilingual SWE environments to a million scale (807,693). We demonstrate the profound value of our environments through large-scale agentic mid-training and reinforcement learning. Finally, we applied this technique to Qwen3-Max-Thinking and achieved a score of 75.3% on SWE-Bench Verified. Our work provides both a critical resource and a robust methodology to advance the next generation of coding agents.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
ByteScale: Efficient Scaling of LLM Training with a 2048K Context Length on More Than 12,000 GPUs
Feb 28, 2025Scaling long-context ability is essential for Large Language Models (LLMs). To amortize the memory consumption across multiple devices in long-context training, inter-data partitioning (a.k.a. Data Parallelism) and intra-data partitioning (a.k.a. Context Parallelism) are commonly used. Current training frameworks predominantly treat the two techniques as orthogonal, and establish static communication groups to organize the devices as a static mesh (e.g., a 2D mesh). However, the sequences for LLM training typically vary in lengths, no matter for texts, multi-modalities or reinforcement learning. The mismatch between data heterogeneity and static mesh causes redundant communication and imbalanced computation, degrading the training efficiency. In this work, we introduce ByteScale, an efficient, flexible, and scalable LLM training framework for large-scale mixed training of long and short sequences. The core of ByteScale is a novel parallelism strategy, namely Hybrid Data Parallelism (HDP), which unifies the inter- and intra-data partitioning with a dynamic mesh design. In particular, we build a communication optimizer, which eliminates the redundant communication for short sequences by data-aware sharding and dynamic communication, and further compresses the communication cost for long sequences by selective offloading. Besides, we also develop a balance scheduler to mitigate the imbalanced computation by parallelism-aware data assignment. We evaluate ByteScale with the model sizes ranging from 7B to 141B, context lengths from 256K to 2048K, on a production cluster with more than 12,000 GPUs. Experiment results show that ByteScale outperforms the state-of-the-art training system by up to 7.89x.
Demystifying Workload Imbalances in Large Transformer Model Training over Variable-length Sequences
Dec 10, 2024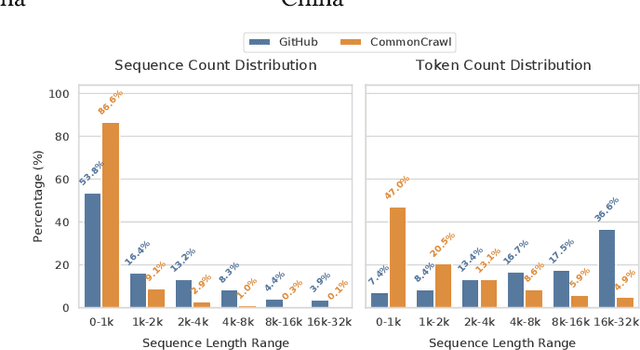
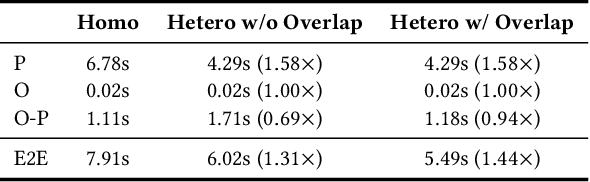
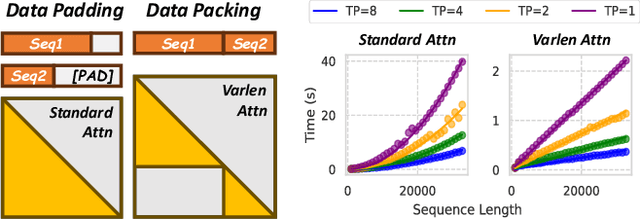

To optimize large Transformer model training, efficient parallel computing and advanced data management are essential. However, current methods often assume a stable and uniform training workload, neglecting imbalances in data sampling and packing that can impede performance. Specifically, data sampling imbalance arises from uneven sequence length distribution of the training data, while data packing imbalance stems from the discrepancy between the linear memory complexity and quadratic time complexity of the attention mechanism. To address these imbalance issues, we develop Hydraulis, which jointly optimizes the parallel strategies and data assignment. For one thing, we introduce large model training with dynamic heterogeneous parallel strategies in response to the sequence length variations within and across training iterations. For another, we devise a two-stage data assignment approach, which strikes a good balance in terms of the training workloads both within and across model replicas. Empirical results demonstrate that Hydraulis outperforms existing systems by 1.32-2.66 times.
Rethinking the Threat and Accessibility of Adversarial Attacks against Face Recognition Systems
Jul 11, 2024



Face recognition pipelines have been widely deployed in various mission-critical systems in trust, equitable and responsible AI applications. However, the emergence of adversarial attacks has threatened the security of the entire recognition pipeline. Despite the sheer number of attack methods proposed for crafting adversarial examples in both digital and physical forms, it is never an easy task to assess the real threat level of different attacks and obtain useful insight into the key risks confronted by face recognition systems. Traditional attacks view imperceptibility as the most important measurement to keep perturbations stealthy, while we suspect that industry professionals may possess a different opinion. In this paper, we delve into measuring the threat brought about by adversarial attacks from the perspectives of the industry and the applications of face recognition. In contrast to widely studied sophisticated attacks in the field, we propose an effective yet easy-to-launch physical adversarial attack, named AdvColor, against black-box face recognition pipelines in the physical world. AdvColor fools models in the recognition pipeline via directly supplying printed photos of human faces to the system under adversarial illuminations. Experimental results show that physical AdvColor examples can achieve a fooling rate of more than 96% against the anti-spoofing model and an overall attack success rate of 88% against the face recognition pipeline. We also conduct a survey on the threats of prevailing adversarial attacks, including AdvColor, to understand the gap between the machine-measured and human-assessed threat levels of different forms of adversarial attacks. The survey results surprisingly indicate that, compared to deliberately launched imperceptible attacks, perceptible but accessible attacks pose more lethal threats to real-world commercial systems of face recognition.
LocalStyleFool: Regional Video Style Transfer Attack Using Segment Anything Model
Mar 27, 2024



Previous work has shown that well-crafted adversarial perturbations can threaten the security of video recognition systems. Attackers can invade such models with a low query budget when the perturbations are semantic-invariant, such as StyleFool. Despite the query efficiency, the naturalness of the minutia areas still requires amelioration, since StyleFool leverages style transfer to all pixels in each frame. To close the gap, we propose LocalStyleFool, an improved black-box video adversarial attack that superimposes regional style-transfer-based perturbations on videos. Benefiting from the popularity and scalably usability of Segment Anything Model (SAM), we first extract different regions according to semantic information and then track them through the video stream to maintain the temporal consistency. Then, we add style-transfer-based perturbations to several regions selected based on the associative criterion of transfer-based gradient information and regional area. Perturbation fine adjustment is followed to make stylized videos adversarial. We demonstrate that LocalStyleFool can improve both intra-frame and inter-frame naturalness through a human-assessed survey, while maintaining competitive fooling rate and query efficiency. Successful experiments on the high-resolution dataset also showcase that scrupulous segmentation of SAM helps to improve the scalability of adversarial attacks under high-resolution data.
3D Face Reconstruction Using A Spectral-Based Graph Convolution Encoder
Mar 08, 2024


Monocular 3D face reconstruction plays a crucial role in avatar generation, with significant demand in web-related applications such as generating virtual financial advisors in FinTech. Current reconstruction methods predominantly rely on deep learning techniques and employ 2D self-supervision as a means to guide model learning. However, these methods encounter challenges in capturing the comprehensive 3D structural information of the face due to the utilization of 2D images for model training purposes. To overcome this limitation and enhance the reconstruction of 3D structural features, we propose an innovative approach that integrates existing 2D features with 3D features to guide the model learning process. Specifically, we introduce the 3D-ID Loss, which leverages the high-dimensional structure features extracted from a Spectral-Based Graph Convolution Encoder applied to the facial mesh. This approach surpasses the sole reliance on the 3D information provided by the facial mesh vertices coordinates. Our model is trained using 2D-3D data pairs from a combination of datasets and achieves state-of-the-art performance on the NoW benchmark.
Unsupervised multiple choices question answering via universal corpus
Feb 27, 2024Unsupervised question answering is a promising yet challenging task, which alleviates the burden of building large-scale annotated data in a new domain. It motivates us to study the unsupervised multiple-choice question answering (MCQA) problem. In this paper, we propose a novel framework designed to generate synthetic MCQA data barely based on contexts from the universal domain without relying on any form of manual annotation. Possible answers are extracted and used to produce related questions, then we leverage both named entities (NE) and knowledge graphs to discover plausible distractors to form complete synthetic samples. Experiments on multiple MCQA datasets demonstrate the effectiveness of our method.
Influential Recommender System
Nov 23, 2022Traditional recommender systems are typically passive in that they try to adapt their recommendations to the user's historical interests. However, it is highly desirable for commercial applications, such as e-commerce, advertisement placement, and news portals, to be able to expand the users' interests so that they would accept items that they were not originally aware of or interested in to increase customer interactions. In this paper, we present Influential Recommender System (IRS), a new recommendation paradigm that aims to proactively lead a user to like a given objective item by progressively recommending to the user a sequence of carefully selected items (called an influence path). We propose the Influential Recommender Network (IRN), which is a Transformer-based sequential model to encode the items' sequential dependencies. Since different people react to external influences differently, we introduce the Personalized Impressionability Mask (PIM) to model how receptive a user is to external influence to generate the most effective influence path for the user. To evaluate IRN, we design several performance metrics to measure whether or not the influence path can smoothly expand the user interest to include the objective item while maintaining the user's satisfaction with the recommendation. Experimental results show that IRN significantly outperforms the baseline recommenders and demonstrates its capability of influencing users' interests.
What's the relationship between CNNs and communication systems?
Mar 03, 2020The interpretability of Convolutional Neural Networks (CNNs) is an important topic in the field of computer vision. In recent years, works in this field generally adopt a mature model to reveal the internal mechanism of CNNs, helping to understand CNNs thoroughly. In this paper, we argue the working mechanism of CNNs can be revealed through a totally different interpretation, by comparing the communication systems and CNNs. This paper successfully obtained the corresponding relationship between the modules of the two, and verified the rationality of the corresponding relationship with experiments. Finally, through the analysis of some cutting-edge research on neural networks, we find the inherent relation between these two tasks can be of help in explaining these researches reasonably, as well as helping us discover the correct research direction of neural networks.