 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL-VLA$^3$: Reinforcement Learning VLA Accelerating via Full Asynchronism
Feb 05, 2026In recent years, Vision-Language-Action (VLA) models have emerged as a crucial pathway towards general embodied intelligence, yet their training efficiency has become a key bottleneck. Although existing reinforcement learning (RL)-based training frameworks like RLinf can enhance model generalization, they still rely on synchronous execution, leading to severe resource underutilization and throughput limitations during environment interaction, policy generation (rollout), and model update phases (actor). To overcome this challenge, this paper, for the first time, proposes and implements a fully-asynchronous policy training framework encompassing the entire pipeline from environment interaction, rollout generation, to actor policy updates. Systematically drawing inspiration from asynchronous optimization ideas in large model RL, our framework designs a multi-level decoupled architecture. This includes asynchronous parallelization of environment interaction and trajectory collection, streaming execution for policy generation, and decoupled scheduling for training updates. We validated the effectiveness of our method across diverse VLA models and environments. On the LIBERO benchmark, the framework achieves throughput improvements of up to 59.25\% compared to existing synchronous strategies. When deeply optimizing separation strategies, throughput can be increased by as much as 126.67\%. We verified the effectiveness of each asynchronous component via ablation studies. Scaling law validation across 8 to 256 GPUs demonstrates our method's excellent scalability under most conditions.
Systematic Analysis of MCP Security
Aug 18, 2025The Model Context Protocol (MCP) has emerged as a universal standard that enables AI agents to seamlessly connect with external tools, significantly enhancing their functionality. However, while MCP brings notable benefits, it also introduces significant vulnerabilities, such as Tool Poisoning Attacks (TPA), where hidden malicious instructions exploit the sycophancy of large language models (LLMs) to manipulate agent behavior. Despite these risks, current academic research on MCP security remains limited, with most studies focusing on narrow or qualitative analyses that fail to capture the diversity of real-world threats. To address this gap, we present the MCP Attack Library (MCPLIB), which categorizes and implements 31 distinct attack methods under four key classifications: direct tool injection, indirect tool injection, malicious user attacks, and LLM inherent attack. We further conduct a quantitative analysis of the efficacy of each attack. Our experiments reveal key insights into MCP vulnerabilities, including agents' blind reliance on tool descriptions, sensitivity to file-based attacks, chain attacks exploiting shared context, and difficulty distinguishing external data from executable commands. These insights, validated through attack experiments, underscore the urgency for robust defense strategies and informed MCP design. Our contributions include 1) constructing a comprehensive MCP attack taxonomy, 2) introducing a unified attack framework MCPLIB, and 3) conducting empirical vulnerability analysis to enhance MCP security mechanisms. This work provides a foundational framework, supporting the secure evolution of MCP ecosystems.
Query-Efficient Video Adversarial Attack with Stylized Logo
Aug 22, 2024Video classification systems based on Deep Neural Networks (DNNs) have demonstrated excellent performance in accurately verifying video content. However, recent studies have shown that DNNs are highly vulnerable to adversarial examples. Therefore, a deep understanding of adversarial attacks can better respond to emergency situations. In order to improve attack performance, many style-transfer-based attacks and patch-based attacks have been proposed. However, the global perturbation of the former will bring unnatural global color, while the latter is difficult to achieve success in targeted attacks due to the limited perturbation space. Moreover, compared to a plethora of methods targeting image classifiers, video adversarial attacks are still not that popular. Therefore, to generate adversarial examples with a low budget and to provide them with a higher verisimilitude, we propose a novel black-box video attack framework, called Stylized Logo Attack (SLA). SLA is conducted through three steps. The first step involves building a style references set for logos, which can not only make the generated examples more natural, but also carry more target class features in the targeted attacks. Then, reinforcement learning (RL) is employed to determine the style reference and position parameters of the logo within the video, which ensures that the stylized logo is placed in the video with optimal attributes. Finally, perturbation optimization is designed to optimize perturbations to improve the fooling rate in a step-by-step manner. Sufficient experimental results indicate that, SLA can achieve better performance than state-of-the-art methods and still maintain good deception effects when facing various defense methods.
Rethinking the Threat and Accessibility of Adversarial Attacks against Face Recognition Systems
Jul 11, 2024



Face recognition pipelines have been widely deployed in various mission-critical systems in trust, equitable and responsible AI applications. However, the emergence of adversarial attacks has threatened the security of the entire recognition pipeline. Despite the sheer number of attack methods proposed for crafting adversarial examples in both digital and physical forms, it is never an easy task to assess the real threat level of different attacks and obtain useful insight into the key risks confronted by face recognition systems. Traditional attacks view imperceptibility as the most important measurement to keep perturbations stealthy, while we suspect that industry professionals may possess a different opinion. In this paper, we delve into measuring the threat brought about by adversarial attacks from the perspectives of the industry and the applications of face recognition. In contrast to widely studied sophisticated attacks in the field, we propose an effective yet easy-to-launch physical adversarial attack, named AdvColor, against black-box face recognition pipelines in the physical world. AdvColor fools models in the recognition pipeline via directly supplying printed photos of human faces to the system under adversarial illuminations. Experimental results show that physical AdvColor examples can achieve a fooling rate of more than 96% against the anti-spoofing model and an overall attack success rate of 88% against the face recognition pipeline. We also conduct a survey on the threats of prevailing adversarial attacks, including AdvColor, to understand the gap between the machine-measured and human-assessed threat levels of different forms of adversarial attacks. The survey results surprisingly indicate that, compared to deliberately launched imperceptible attacks, perceptible but accessible attacks pose more lethal threats to real-world commercial systems of face recognition.
AI Agents Under Threat: A Survey of Key Security Challenges and Future Pathways
Jun 04, 2024



An Artificial Intelligence (AI) agent is a software entity that autonomously performs tasks or makes decisions based on pre-defined objectives and data inputs. AI agents, capable of perceiving user inputs, reasoning and planning tasks, and executing actions, have seen remarkable advancements in algorithm development and task performance. However, the security challenges they pose remain under-explored and unresolved. This survey delves into the emerging security threats faced by AI agents, categorizing them into four critical knowledge gaps: unpredictability of multi-step user inputs, complexity in internal executions, variability of operational environments, and interactions with untrusted external entities. By systematically reviewing these threats, this paper highlights both the progress made and the existing limitations in safeguarding AI agents. The insights provided aim to inspire further research into addressing the security threats associated with AI agents, thereby fostering the development of more robust and secure AI agent applications.
The "Beatrix'' Resurrections: Robust Backdoor Detection via Gram Matrices
Sep 26, 2022Deep Neural Networks (DNNs) are susceptible to backdoor attacks during training. The model corrupted in this way functions normally, but when triggered by certain patterns in the input, produces a predefined target label. Existing defenses usually rely on the assumption of the universal backdoor setting in which poisoned samples share the same uniform trigger. However, recent advanced backdoor attacks show that this assumption is no longer valid in dynamic backdoors where the triggers vary from input to input, thereby defeating the existing defenses. In this work, we propose a novel technique, Beatrix (backdoor detection via Gram matrix). Beatrix utilizes Gram matrix to capture not only the feature correlations but also the appropriately high-order information of the representations. By learning class-conditional statistics from activation patterns of normal samples, Beatrix can identify poisoned samples by capturing the anomalies in activation patterns. To further improve the performance in identifying target labels, Beatrix leverages kernel-based testing without making any prior assumptions on representation distribution. We demonstrate the effectiveness of our method through extensive evaluation and comparison with state-of-the-art defensive techniques. The experimental results show that our approach achieves an F1 score of 91.1% in detecting dynamic backdoors, while the state of the art can only reach 36.9%.
StyleFool: Fooling Video Classification Systems via Style Transfer
Mar 30, 2022
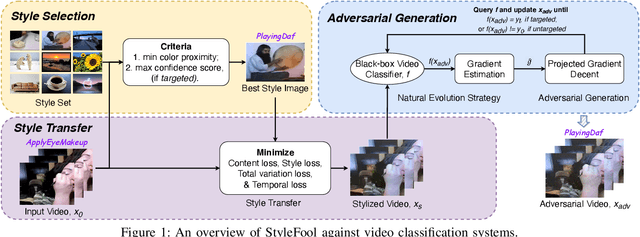

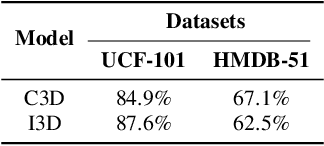
Video classification systems are vulnerable to adversarial attacks, which can create severe security problems in video verification. Current black-box attacks need a large number of queries to succeed, resulting in high computational overhead in the process of attack. On the other hand, attacks with restricted perturbations are ineffective against defenses such as denoising or adversarial training. In this paper, we focus on unrestricted perturbations and propose StyleFool, a black-box video adversarial attack via style transfer to fool the video classification system. StyleFool first utilizes color theme proximity to select the best style image, which helps avoid unnatural details in the stylized videos. Meanwhile, the target class confidence is additionally considered in targeted attack to influence the output distribution of the classifier by moving the stylized video closer to or even across the decision boundary. A gradient-free method is then employed to further optimize the adversarial perturbation. We carry out extensive experiments to evaluate StyleFool on two standard datasets, UCF-101 and HMDB-51. The experimental results suggest that StyleFool outperforms the state-of-the-art adversarial attacks in terms of both number of queries and robustness against existing defenses. We identify that 50% of the stylized videos in untargeted attack do not need any query since they can already fool the video classification model. Furthermore, we evaluate the indistinguishability through a user study to show that the adversarial samples of StyleFool look imperceptible to human eyes, despite unrestricted perturbations.
DeFuzz: Deep Learning Guided Directed Fuzzing
Oct 23, 2020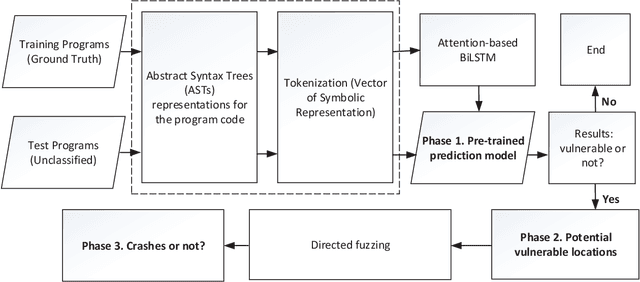

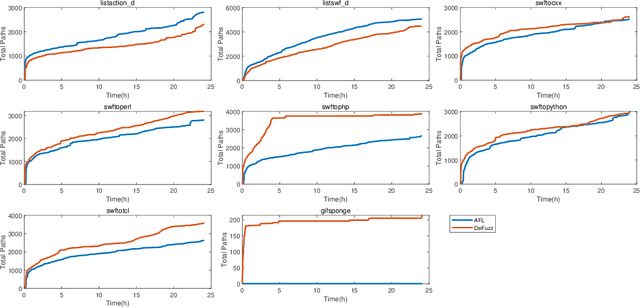
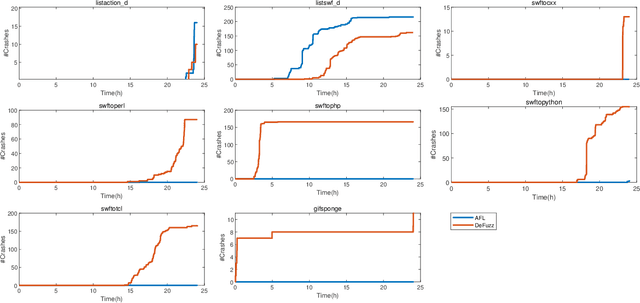
Fuzzing is one of the most effective technique to identify potential software vulnerabilities. Most of the fuzzers aim to improve the code coverage, and there is lack of directedness (e.g., fuzz the specified path in a software). In this paper, we proposed a deep learning (DL) guided directed fuzzing for software vulnerability detection, named DeFuzz. DeFuzz includes two main schemes: (1) we employ a pre-trained DL prediction model to identify the potentially vulnerable functions and the locations (i.e., vulnerable addresses). Precisely, we employ Bidirectional-LSTM (BiLSTM) to identify attention words, and the vulnerabilities are associated with these attention words in functions. (2) then we employ directly fuzzing to fuzz the potential vulnerabilities by generating inputs that tend to arrive the predicted locations. To evaluate the effectiveness and practical of the proposed DeFuzz technique, we have conducted experiments on real-world data sets. Experimental results show that our DeFuzz can discover coverage more and faster than AFL. Moreover, DeFuzz exposes 43 more bugs than AFL on real-world applications.
Man-in-the-Middle Attacks against Machine Learning Classifiers via Malicious Generative Models
Oct 14, 2019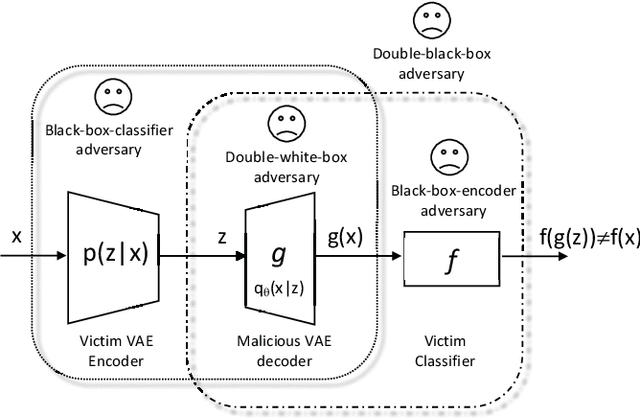
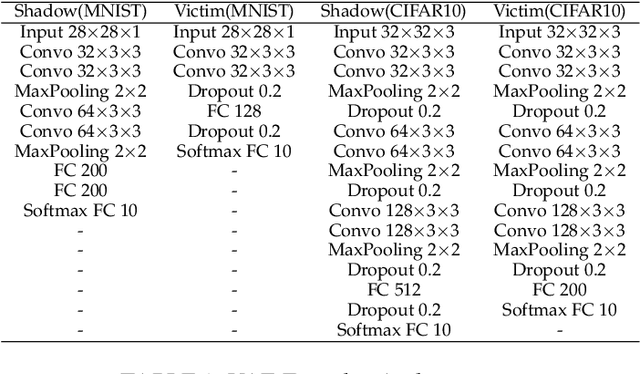
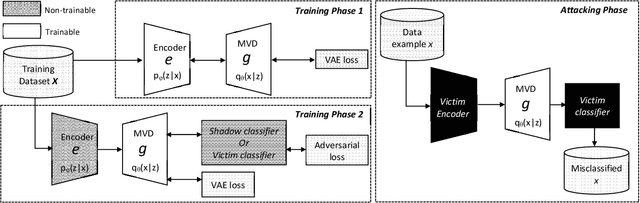

Deep Neural Networks (DNNs) are vulnerable to deliberately crafted adversarial examples. In the past few years, many efforts have been spent on exploring query-optimisation attacks to find adversarial examples of either black-box or white-box DNN models, as well as the defending countermeasures against those attacks. In this work, we explore vulnerabilities of DNN models under the umbrella of Man-in-the-Middle (MitM) attacks, which has not been investigated before. From the perspective of an MitM adversary, the aforementioned adversarial example attacks are not viable anymore. First, such attacks must acquire the outputs from the models by multiple times before actually launching attacks, which is difficult for the MitM adversary in practice. Second, such attacks are one-off and cannot be directly generalised onto new data examples, which decreases the rate of return for the attacker. In contrast, using generative models to craft adversarial examples on the fly can mitigate the drawbacks. However, the adversarial capability of the generative models, such as Variational Auto-Encoder (VAE), has not been extensively studied. Therefore, given a classifier, we investigate using a VAE decoder to either transform benign inputs to their adversarial counterparts or decode outputs from benign VAE encoders to be adversarial examples. The proposed method can endue more capability to MitM attackers. Based on our evaluation, the proposed attack can achieve above 95% success rate on both MNIST and CIFAR10 datasets, which is better or comparable with state-of-the-art query-optimisation attacks. At the meantime, the attack is 104 times faster than the query-optimisation attacks.
Daedalus: Breaking Non-Maximum Suppression in Object Detection via Adversarial Examples
Feb 06, 2019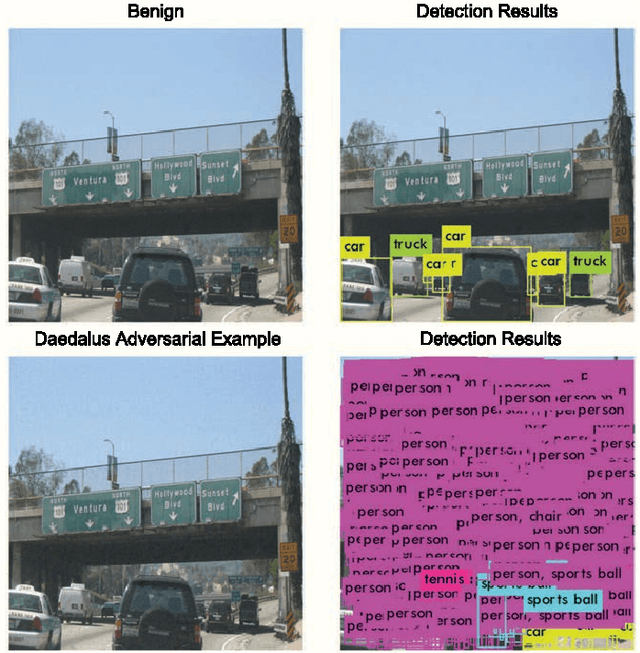
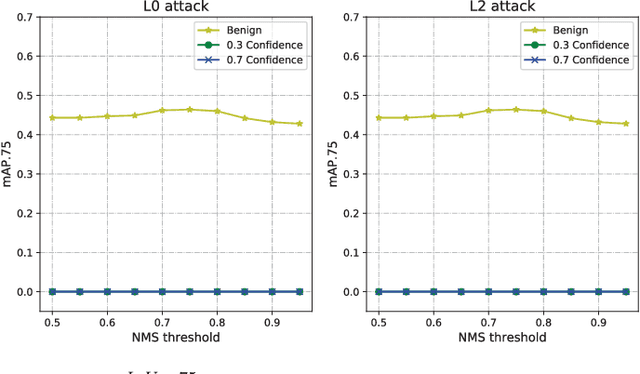
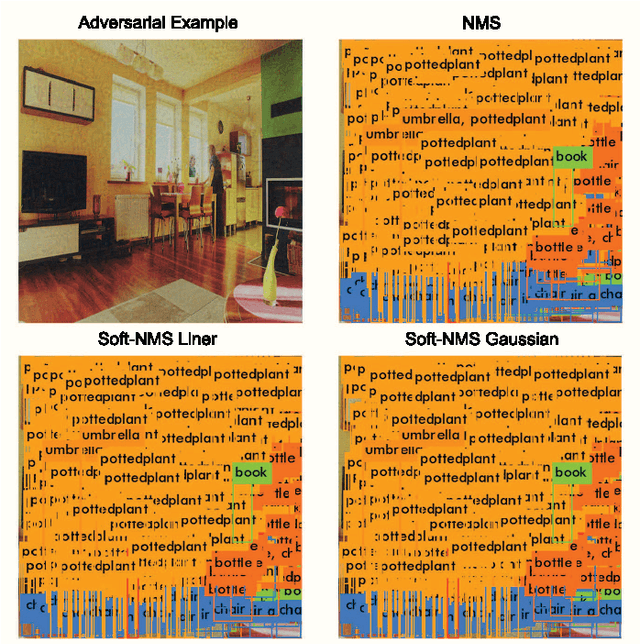

We demonstrated that Non-Maximum Suppression (NMS), which is commonly used in object detection tasks to filter redundant detection results, is no longer secure. NMS has always been an integral part of object detection algorithms. Currently, Fully Convolutional Network (FCN) is widely used as the backbone architecture of object detection models. Given an input instance, since FCN generates end-to-end detection results in a single stage, it outputs a large number of raw detection boxes. These bounding boxes are then filtered by NMS to make the final detection results. In this paper, we propose an adversarial example attack which triggers malfunctioning of NMS in the end-to-end object detection models. Our attack, namely Daedalus, manipulates the detection box regression values to compress the dimensions of detection boxes. Henceforth, NMS will no longer be able to filter redundant detection boxes correctly. And as a result, the final detection output contains extremely dense false positives. This can be fatal for many object detection applications such as autonomous vehicle and smart manufacturing industry. Our attack can be applied to different end-to-end object detection models. Furthermore, we suggest crafting robust adversarial examples by using an ensemble of popular detection models as the substitutes. Considering that model reusing is commonly seen in real-world object detection scenarios, Daedalus examples crafted based on an ensemble of substitutes can launch attacks without knowing the details of the victim models. Our experiments demonstrate that our attack effectively stops NMS from filtering redundant bounding boxes. As the evaluation results suggest, Daedalus increases the false positive rate in detection results to 99.9% and reduces the mean average precision scores to 0, while maintaining a low cost of distortion on the original inputs.