 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImg2CADSeq: Image-to-CAD Generation via Sequence-Based Diffusion
May 13, 2026Boundary Representation (BRep) is the standard format for Computer-Aided Design (CAD), yet reconstructing high-quality BReps from single-view images remains challenging due to the complexity of topological constraints and operation sequences. We present Img2CADSeq, a multi-stage pipeline that overcomes these limitations by encoding CAD sequences into a three-level hierarchical codebook. Guided by an importance prioritization, this strategy values profiles over details, compressing long sequences into a stable discrete latent space. To bridge the modality gap, we leverage a coarse-to-fine point cloud intermediate, aligning 2D visual features with 3D CAD sequences via contrastive learning to condition a VQ-Diffusion model. Supported by newly introduced CAD-220K and PrintCAD datasets, our approach ensures robust industrial domain adaptation. Extensive experiments demonstrate that Img2CADSeq significantly outperforms state-of-the-art methods, producing standard STEP files that can be directly used in commercial CAD software.
Instance-level Visual Active Tracking with Occlusion-Aware Planning
Apr 23, 2026Visual Active Tracking (VAT) aims to control cameras to follow a target in 3D space, which is critical for applications like drone navigation and security surveillance. However, it faces two key bottlenecks in real-world deployment: confusion from visually similar distractors caused by insufficient instance-level discrimination and severe failure under occlusions due to the absence of active planning. To address these, we propose OA-VAT, a unified pipeline with three complementary modules. First, a training-free Instance-Aware Offline Prototype Initialization aggregates multi-view augmented features via DINOv3 to construct discriminative instance prototypes, mitigating distractor confusion. Second, an Online Prototype Enhancement Tracker enhances prototypes online and integrates a confidence-aware Kalman filter for stable tracking under appearance and motion changes. Third, an Occlusion-Aware Trajectory Planner, trained on our new Planning-20k dataset, uses conditional diffusion to generate obstacle-avoiding paths for occlusion recovery. Experiments demonstrate OA-VAT achieves 0.93 average SR on UnrealCV (+2.2% vs. SOTA TrackVLA), 90.8% average CAR on real-world datasets (+12.1% vs. SOTA GC-VAT), and 81.6% TSR on a DJI Tello drone. Running at 35 FPS on an RTX 3090, it delivers robust, real-time performance for practical deployment.
RAD-2: Scaling Reinforcement Learning in a Generator-Discriminator Framework
Apr 16, 2026High-level autonomous driving requires motion planners capable of modeling multimodal future uncertainties while remaining robust in closed-loop interactions. Although diffusion-based planners are effective at modeling complex trajectory distributions, they often suffer from stochastic instabilities and the lack of corrective negative feedback when trained purely with imitation learning. To address these issues, we propose RAD-2, a unified generator-discriminator framework for closed-loop planning. Specifically, a diffusion-based generator is used to produce diverse trajectory candidates, while an RL-optimized discriminator reranks these candidates according to their long-term driving quality. This decoupled design avoids directly applying sparse scalar rewards to the full high-dimensional trajectory space, thereby improving optimization stability. To further enhance reinforcement learning, we introduce Temporally Consistent Group Relative Policy Optimization, which exploits temporal coherence to alleviate the credit assignment problem. In addition, we propose On-policy Generator Optimization, which converts closed-loop feedback into structured longitudinal optimization signals and progressively shifts the generator toward high-reward trajectory manifolds. To support efficient large-scale training, we introduce BEV-Warp, a high-throughput simulation environment that performs closed-loop evaluation directly in Bird's-Eye View feature space via spatial warping. RAD-2 reduces the collision rate by 56% compared with strong diffusion-based planners. Real-world deployment further demonstrates improved perceived safety and driving smoothness in complex urban traffic.
Senna-2: Aligning VLM and End-to-End Driving Policy for Consistent Decision Making and Planning
Mar 11, 2026Vision-language models (VLMs) enhance the planning capability of end-to-end (E2E) driving policy by leveraging high-level semantic reasoning. However, existing approaches often overlook the dual-system consistency between VLM's high-level decision and E2E's low-level planning. As a result, the generated trajectories may misalign with the intended driving decisions, leading to weakened top-down guidance and decision-following ability of the system. To address this issue, we propose Senna-2, an advanced VLM-E2E driving policy that explicitly aligns the two systems for consistent decision-making and planning. Our method follows a consistency-oriented three-stage training paradigm. In the first stage, we conduct driving pre-training to achieve preliminary decision-making and planning, with a decision adapter transmitting VLM decisions to E2E policy in the form of implicit embeddings. In the second stage, we align the VLM and the E2E policy in an open-loop setting. In the third stage, we perform closed-loop alignment via bottom-up Hierarchical Reinforcement Learning in 3DGS environments to reinforce the safety and efficiency. Extensive experiments demonstrate that Senna-2 achieves superior dual-system consistency (19.3% F1 score improvement) and significantly enhances driving safety in both open-loop (5.7% FDE reduction) and closed-loop settings (30.6% AF-CR reduction).
Effective Gaussian Management for High-fidelity Object Reconstruction
Sep 16, 2025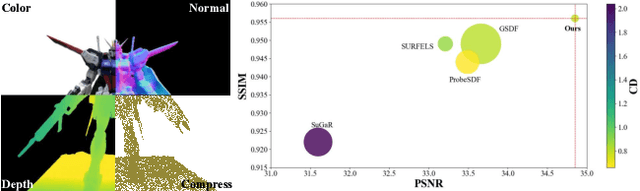
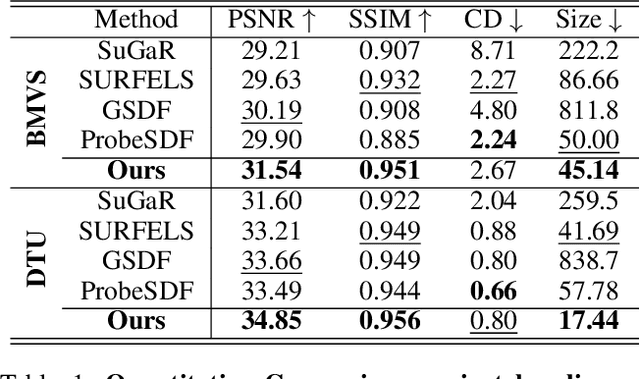
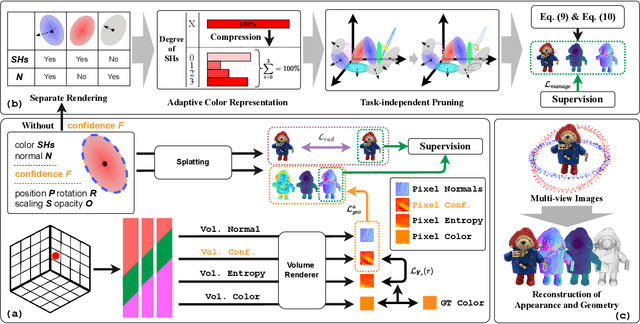
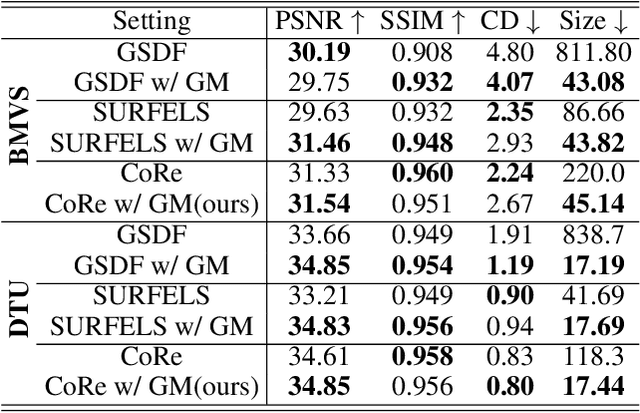
This paper proposes an effective Gaussian management approach for high-fidelity object reconstruction. Departing from recent Gaussian Splatting (GS) methods that employ indiscriminate attribute assignment, our approach introduces a novel densification strategy that dynamically activates spherical harmonics (SHs) or normals under the supervision of a surface reconstruction module, which effectively mitigates the gradient conflicts caused by dual supervision and achieves superior reconstruction results. To further improve representation efficiency, we develop a lightweight Gaussian representation that adaptively adjusts the SH orders of each Gaussian based on gradient magnitudes and performs task-decoupled pruning to remove Gaussian with minimal impact on a reconstruction task without sacrificing others, which balances the representational capacity with parameter quantity. Notably, our management approach is model-agnostic and can be seamlessly integrated into other frameworks, enhancing performance while reducing model size. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art approaches in both reconstruction quality and efficiency, achieving superior performance with significantly fewer parameters.
LLM-Enabled In-Context Learning for Data Collection Scheduling in UAV-assisted Sensor Networks
Apr 20, 2025Unmanned Aerial Vehicles (UAVs) are increasingly being used in various private and commercial applications, e.g. traffic control, package delivery, and Search and Rescue (SAR) operations. Machine Learning (ML) methods used in UAV-assisted Sensor Networks (UASNETs) and especially in Deep Reinforcement Learning (DRL) face challenges such as complex and lengthy model training, gaps between simulation and reality, and low sample efficiency, which conflict with the urgency of emergencies such as SAR operations. This paper proposes In-Context Learning (ICL)-based Data Collection Scheduling (ICLDC) scheme, as an alternative to DRL in emergencies. The UAV collects and transmits logged sensory data, to an LLM, to generate a task description in natural language, from which it obtains a data collection schedule to be executed by the UAV. The system continuously adapts by adding feedback to task descriptions and utilizing feedback for future decisions. This method is tested against jailbreaking attacks, where task description is manipulated to undermine network performance, highlighting the vulnerability of LLMs to such attacks. The proposed ICLDC outperforms the Maximum Channel Gain by reducing cumulative packet loss by approximately 56\%. ICLDC presents a promising direction for intelligent scheduling and control in UAV-assisted data collection.
RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-based Reinforcement Learning
Feb 18, 2025



Existing end-to-end autonomous driving (AD) algorithms typically follow the Imitation Learning (IL) paradigm, which faces challenges such as causal confusion and the open-loop gap. In this work, we establish a 3DGS-based closed-loop Reinforcement Learning (RL) training paradigm. By leveraging 3DGS techniques, we construct a photorealistic digital replica of the real physical world, enabling the AD policy to extensively explore the state space and learn to handle out-of-distribution scenarios through large-scale trial and error. To enhance safety, we design specialized rewards that guide the policy to effectively respond to safety-critical events and understand real-world causal relationships. For better alignment with human driving behavior, IL is incorporated into RL training as a regularization term. We introduce a closed-loop evaluation benchmark consisting of diverse, previously unseen 3DGS environments. Compared to IL-based methods, RAD achieves stronger performance in most closed-loop metrics, especially 3x lower collision rate. Abundant closed-loop results are presented at https://hgao-cv.github.io/RAD.
An Oversampling-enhanced Multi-class Imbalanced Classification Framework for Patient Health Status Prediction Using Patient-reported Outcomes
Nov 16, 2024



Patient-reported outcomes (PROs) directly collected from cancer patients being treated with radiation therapy play a vital role in assisting clinicians in counseling patients regarding likely toxicities. Precise prediction and evaluation of symptoms or health status associated with PROs are fundamental to enhancing decision-making and planning for the required services and support as patients transition into survivorship. However, the raw PRO data collected from hospitals exhibits some intrinsic challenges such as incomplete item reports and imbalance patient toxicities. To the end, in this study, we explore various machine learning techniques to predict patient outcomes related to health status such as pain levels and sleep discomfort using PRO datasets from a cancer photon/proton therapy center. Specifically, we deploy six advanced machine learning classifiers -- Random Forest (RF), XGBoost, Gradient Boosting (GB), Support Vector Machine (SVM), Multi-Layer Perceptron with Bagging (MLP-Bagging), and Logistic Regression (LR) -- to tackle a multi-class imbalance classification problem across three prevalent cancer types: head and neck, prostate, and breast cancers. To address the class imbalance issue, we employ an oversampling strategy, adjusting the training set sample sizes through interpolations of in-class neighboring samples, thereby augmenting minority classes without deviating from the original skewed class distribution. Our experimental findings across multiple PRO datasets indicate that the RF and XGB methods achieve robust generalization performance, evidenced by weighted AUC and detailed confusion matrices, in categorizing outcomes as mild, intermediate, and severe post-radiation therapy. These results underscore the models' effectiveness and potential utility in clinical settings.
LASER: Script Execution by Autonomous Agents for On-demand Traffic Simulation
Oct 21, 2024



Autonomous Driving Systems (ADS) require diverse and safety-critical traffic scenarios for effective training and testing, but the existing data generation methods struggle to provide flexibility and scalability. We propose LASER, a novel frame-work that leverage large language models (LLMs) to conduct traffic simulations based on natural language inputs. The framework operates in two stages: it first generates scripts from user-provided descriptions and then executes them using autonomous agents in real time. Validated in the CARLA simulator, LASER successfully generates complex, on-demand driving scenarios, significantly improving ADS training and testing data generation.
Adaptive Advantage-Guided Policy Regularization for Offline Reinforcement Learning
Jun 01, 2024In offline reinforcement learning, the challenge of out-of-distribution (OOD) is pronounced. To address this, existing methods often constrain the learned policy through policy regularization. However, these methods often suffer from the issue of unnecessary conservativeness, hampering policy improvement. This occurs due to the indiscriminate use of all actions from the behavior policy that generates the offline dataset as constraints. The problem becomes particularly noticeable when the quality of the dataset is suboptimal. Thus, we propose Adaptive Advantage-guided Policy Regularization (A2PR), obtaining high-advantage actions from an augmented behavior policy combined with VAE to guide the learned policy. A2PR can select high-advantage actions that differ from those present in the dataset, while still effectively maintaining conservatism from OOD actions. This is achieved by harnessing the VAE capacity to generate samples matching the distribution of the data points. We theoretically prove that the improvement of the behavior policy is guaranteed. Besides, it effectively mitigates value overestimation with a bounded performance gap. Empirically, we conduct a series of experiments on the D4RL benchmark, where A2PR demonstrates state-of-the-art performance. Furthermore, experimental results on additional suboptimal mixed datasets reveal that A2PR exhibits superior performance. Code is available at https://github.com/ltlhuuu/A2PR.