 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImg2CADSeq: Image-to-CAD Generation via Sequence-Based Diffusion
May 13, 2026Boundary Representation (BRep) is the standard format for Computer-Aided Design (CAD), yet reconstructing high-quality BReps from single-view images remains challenging due to the complexity of topological constraints and operation sequences. We present Img2CADSeq, a multi-stage pipeline that overcomes these limitations by encoding CAD sequences into a three-level hierarchical codebook. Guided by an importance prioritization, this strategy values profiles over details, compressing long sequences into a stable discrete latent space. To bridge the modality gap, we leverage a coarse-to-fine point cloud intermediate, aligning 2D visual features with 3D CAD sequences via contrastive learning to condition a VQ-Diffusion model. Supported by newly introduced CAD-220K and PrintCAD datasets, our approach ensures robust industrial domain adaptation. Extensive experiments demonstrate that Img2CADSeq significantly outperforms state-of-the-art methods, producing standard STEP files that can be directly used in commercial CAD software.
IOVS4NeRF:Incremental Optimal View Selection for Large-Scale NeRFs
Jul 26, 2024



Urban-level three-dimensional reconstruction for modern applications demands high rendering fidelity while minimizing computational costs. The advent of Neural Radiance Fields (NeRF) has enhanced 3D reconstruction, yet it exhibits artifacts under multiple viewpoints. In this paper, we propose a new NeRF framework method to address these issues. Our method uses image content and pose data to iteratively plan the next best view. A crucial aspect of this method involves uncertainty estimation, guiding the selection of views with maximum information gain from a candidate set. This iterative process enhances rendering quality over time. Simultaneously, we introduce the Vonoroi diagram and threshold sampling together with flight classifier to boost the efficiency, while keep the original NeRF network intact. It can serve as a plug-in tool to assist in better rendering, outperforming baselines and similar prior works.
Foveated Thermal Computational Imaging in the Wild Using All-Silicon Meta-Optics
Dec 13, 2022Foveated imaging provides a better tradeoff between situational awareness (field of view) and resolution and is critical in long-wavelength infrared regimes because of the size, weight, power, and cost of thermal sensors. We demonstrate computational foveated imaging by exploiting the ability of a meta-optical frontend to discriminate between different polarization states and a computational backend to reconstruct the captured image/video. The frontend is a three-element optic: the first element which we call the "foveal" element is a metalens that focuses s-polarized light at a distance of $f_1$ without affecting the p-polarized light; the second element which we call the "perifoveal" element is another metalens that focuses p-polarized light at a distance of $f_2$ without affecting the s-polarized light. The third element is a freely rotating polarizer that dynamically changes the mixing ratios between the two polarization states. Both the foveal element (focal length = 150mm; diameter = 75mm), and the perifoveal element (focal length = 25mm; diameter = 25mm) were fabricated as polarization-sensitive, all-silicon, meta surfaces resulting in a large-aperture, 1:6 foveal expansion, thermal imaging capability. A computational backend then utilizes a deep image prior to separate the resultant multiplexed image or video into a foveated image consisting of a high-resolution center and a lower-resolution large field of view context. We build a first-of-its-kind prototype system and demonstrate 12 frames per second real-time, thermal, foveated image, and video capture in the wild.
CodedStereo: Learned Phase Masks for Large Depth-of-field Stereo
Apr 09, 2021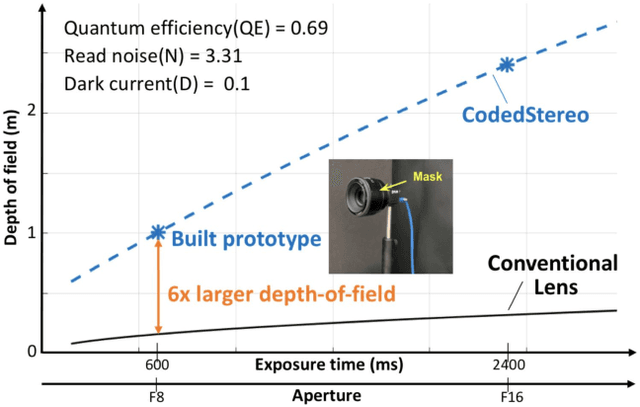
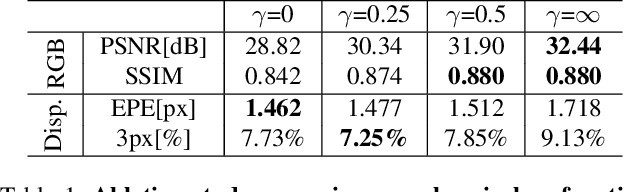
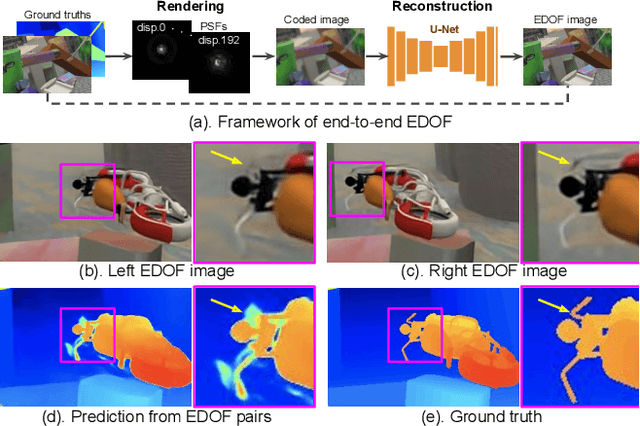
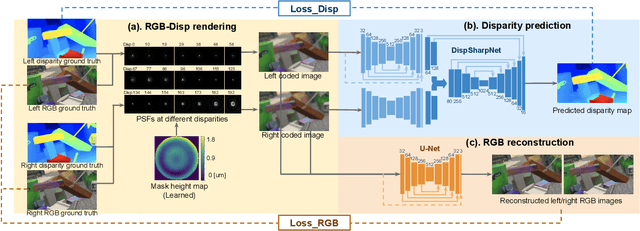
Conventional stereo suffers from a fundamental trade-off between imaging volume and signal-to-noise ratio (SNR) -- due to the conflicting impact of aperture size on both these variables. Inspired by the extended depth of field cameras, we propose a novel end-to-end learning-based technique to overcome this limitation, by introducing a phase mask at the aperture plane of the cameras in a stereo imaging system. The phase mask creates a depth-dependent point spread function, allowing us to recover sharp image texture and stereo correspondence over a significantly extended depth of field (EDOF) than conventional stereo. The phase mask pattern, the EDOF image reconstruction, and the stereo disparity estimation are all trained together using an end-to-end learned deep neural network. We perform theoretical analysis and characterization of the proposed approach and show a 6x increase in volume that can be imaged in simulation. We also build an experimental prototype and validate the approach using real-world results acquired using this prototype system.