 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorSeg: Language Grounded Query Banks for Reasoning Segmentation
Apr 22, 2026Reasoning segmentation requires models to ground complex, implicit textual queries into precise pixel-level masks. Existing approaches rely on a single segmentation token $\texttt{<SEG>}$, whose hidden state implicitly encodes both semantic reasoning and spatial localization, limiting the model's ability to explicitly disentangle what to segment from where to segment. We introduce AnchorSeg, which reformulates reasoning segmentation as a structured conditional generation process over image tokens, conditioned on language grounded query banks. Instead of compressing all semantic reasoning and spatial localization into a single embedding, AnchorSeg constructs an ordered sequence of query banks: latent reasoning tokens that capture intermediate semantic states, and a segmentation anchor token that provides explicit spatial grounding. We model spatial conditioning as a factorized distribution over image tokens, where the anchor query determines localization signals while contextual queries provide semantic modulation. To bridge token-level predictions and pixel-level supervision, we propose Token--Mask Cycle Consistency (TMCC), a bidirectional training objective that enforces alignment across resolutions. By explicitly decoupling spatial grounding from semantic reasoning through structured language grounded query banks, AnchorSeg achieves state-of-the-art results on ReasonSeg test set (67.7\% gIoU and 68.1\% cIoU). All code and models are publicly available at https://github.com/rui-qian/AnchorSeg.
Unrewarded Exploration in Large Language Models Reveals Latent Learning from Psychology
Jan 30, 2026Latent learning, classically theorized by Tolman, shows that biological agents (e.g., rats) can acquire internal representations of their environment without rewards, enabling rapid adaptation once rewards are introduced. In contrast, from a cognitive science perspective, reward learning remains overly dependent on external feedback, limiting flexibility and generalization. Although recent advances in the reasoning capabilities of large language models (LLMs), such as OpenAI-o1 and DeepSeek-R1, mark a significant breakthrough, these models still rely primarily on reward-centric reinforcement learning paradigms. Whether and how the well-established phenomenon of latent learning in psychology can inform or emerge within LLMs' training remains largely unexplored. In this work, we present novel findings from our experiments that LLMs also exhibit the latent learning dynamics. During an initial phase of unrewarded exploration, LLMs display modest performance improvements, as this phase allows LLMs to organize task-relevant knowledge without being constrained by reward-driven biases, and performance is further enhanced once rewards are introduced. LLMs post-trained under this two-stage exploration regime ultimately achieve higher competence than those post-trained with reward-based reinforcement learning throughout. Beyond these empirical observations, we also provide theoretical analyses for our experiments explaining why unrewarded exploration yields performance gains, offering a mechanistic account of these dynamics. Specifically, we conducted extensive experiments across multiple model families and diverse task domains to establish the existence of the latent learning dynamics in LLMs.
OmegaUse: Building a General-Purpose GUI Agent for Autonomous Task Execution
Jan 28, 2026Graphical User Interface (GUI) agents show great potential for enabling foundation models to complete real-world tasks, revolutionizing human-computer interaction and improving human productivity. In this report, we present OmegaUse, a general-purpose GUI agent model for autonomous task execution on both mobile and desktop platforms, supporting computer-use and phone-use scenarios. Building an effective GUI agent model relies on two factors: (1) high-quality data and (2) effective training methods. To address these, we introduce a carefully engineered data-construction pipeline and a decoupled training paradigm. For data construction, we leverage rigorously curated open-source datasets and introduce a novel automated synthesis framework that integrates bottom-up autonomous exploration with top-down taxonomy-guided generation to create high-fidelity synthetic data. For training, to better leverage these data, we adopt a two-stage strategy: Supervised Fine-Tuning (SFT) to establish fundamental interaction syntax, followed by Group Relative Policy Optimization (GRPO) to improve spatial grounding and sequential planning. To balance computational efficiency with agentic reasoning capacity, OmegaUse is built on a Mixture-of-Experts (MoE) backbone. To evaluate cross-terminal capabilities in an offline setting, we introduce OS-Nav, a benchmark suite spanning multiple operating systems: ChiM-Nav, targeting Chinese Android mobile environments, and Ubu-Nav, focusing on routine desktop interactions on Ubuntu. Extensive experiments show that OmegaUse is highly competitive across established GUI benchmarks, achieving a state-of-the-art (SOTA) score of 96.3% on ScreenSpot-V2 and a leading 79.1% step success rate on AndroidControl. OmegaUse also performs strongly on OS-Nav, reaching 74.24% step success on ChiM-Nav and 55.9% average success on Ubu-Nav.
Low-Altitude ISAC with Rotatable Active and Passive Arrays
Dec 24, 2025This paper investigates a low-altitude integrated sensing and communication (ISAC) system that leverages cooperative rotatable active and passive arrays. We consider a downlink scenario where a base station (BS) with an active rotatable array serves multiple communication users and senses low-altitude targets, assisted by a rotatable reconfigurable intelligent surface (RIS). A rotation-aware geometry-based multipath model is developed to capture the impact of three-dimensional (3D) array orientations on both steering vectors and direction-dependent element gains. On this basis, we formulate a new optimization problem that maximizes the downlink sum rate subject to a transmit power budget, RIS unit-modulus constraints, mechanical rotation limits, and a sensing beampattern mean-squared-error (MSE) constraint. To address the resulting highly non-convex problem, we propose a penalty-based alternating-optimization (AO) framework that alternately updates the BS precoder, RIS phase shifts, and BS/RIS array rotation angles. The three blocks are efficiently handled via a convex optimization method based on quadratic-transform (QT) and majorization-minorization (MM), Riemannian conjugate gradient (RCG) on the unit-modulus manifold, and projected gradient descent (PGD) with Barzilai-Borwein step sizes, respectively. Numerical results in low-altitude geometries demonstrate that the proposed jointly rotatable BS-RIS architecture achieves significant sum-rate gains over fixed or partially rotatable baselines while guaranteeing sensing requirements, especially with directional antennas and in interference-limited regimes.
Effective Gaussian Management for High-fidelity Object Reconstruction
Sep 16, 2025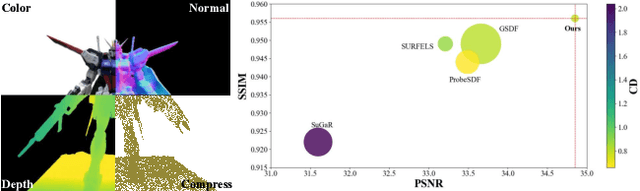
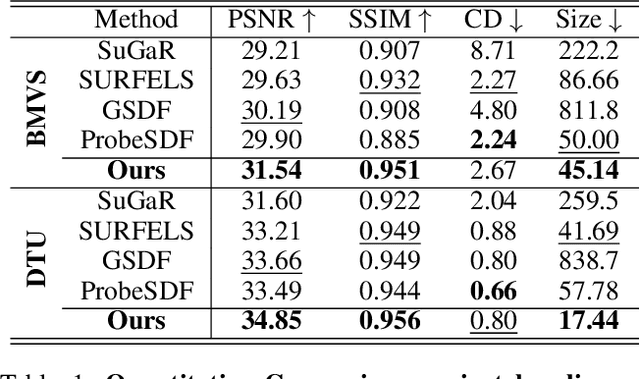
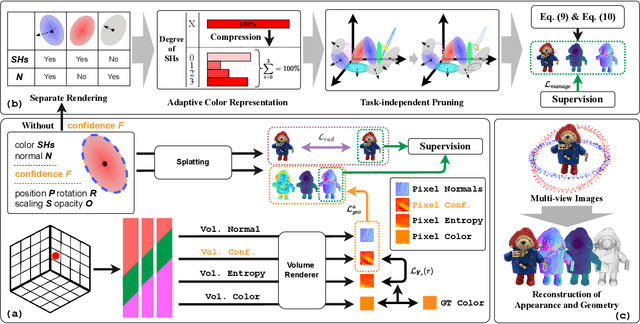
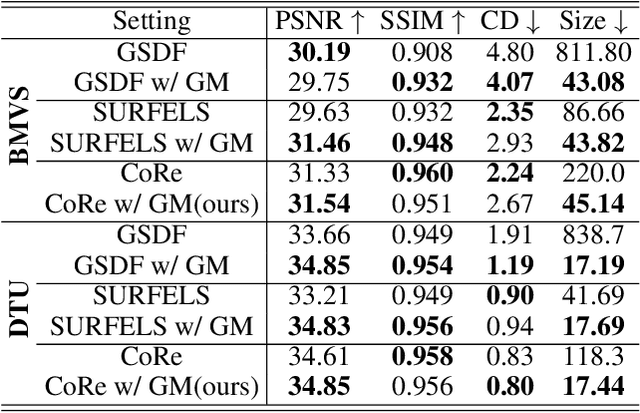
This paper proposes an effective Gaussian management approach for high-fidelity object reconstruction. Departing from recent Gaussian Splatting (GS) methods that employ indiscriminate attribute assignment, our approach introduces a novel densification strategy that dynamically activates spherical harmonics (SHs) or normals under the supervision of a surface reconstruction module, which effectively mitigates the gradient conflicts caused by dual supervision and achieves superior reconstruction results. To further improve representation efficiency, we develop a lightweight Gaussian representation that adaptively adjusts the SH orders of each Gaussian based on gradient magnitudes and performs task-decoupled pruning to remove Gaussian with minimal impact on a reconstruction task without sacrificing others, which balances the representational capacity with parameter quantity. Notably, our management approach is model-agnostic and can be seamlessly integrated into other frameworks, enhancing performance while reducing model size. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art approaches in both reconstruction quality and efficiency, achieving superior performance with significantly fewer parameters.
Capacity-Optimized Pre-Equalizer Design for Visible Light Communication Systems
May 26, 2025Since commercial LEDs are primarily designed for illumination rather than data transmission, their modulation bandwidth is inherently limited to a few MHz. This becomes a major bottleneck in the implementation of visible light communication (VLC) systems necessiating the design of pre-equalizers. While state-of-the-art equalizer designs primarily focus on the data rate increasing through bandwidth expansion, they often overlook the accompanying degradation in signal-to-noise ratio (SNR). Achieving effective bandwidth extension without introducing excessive SNR penalties remains a significant challenge, since the channel capacity is a non-linear function of both parameters. In this paper, we present a fundamental analysis of how the parameters of the LED and pre-equalization circuits influence the channel capacity in intensity modulation and direct detection (IMDD)-based VLC systems. We derive a closed-form expression for channel capacity model that is an explicitly function of analog pre-equalizer circuit parameters. Building upon the derived capacity expression, we propose a systematic design methodology for analog pre-equalizers that effectively balances bandwidth and SNR, thereby maximizing the overall channel capacity across a wide range of channel attenuations. We present extensive numerical results to validate the effectiveness of the proposed design and demonstrate the improvements over conventional bandwidth-optimized pre-equalizer designs.
AAPO: Enhance the Reasoning Capabilities of LLMs with Advantage Momentum
May 20, 2025Reinforcement learning (RL) has emerged as an effective approach for enhancing the reasoning capabilities of large language models (LLMs), especially in scenarios where supervised fine-tuning (SFT) falls short due to limited chain-of-thought (CoT) data. Among RL-based post-training methods, group relative advantage estimation, as exemplified by Group Relative Policy Optimization (GRPO), has attracted considerable attention for eliminating the dependency on the value model, thereby simplifying training compared to traditional approaches like Proximal Policy Optimization (PPO). However, we observe that exsiting group relative advantage estimation method still suffers from training inefficiencies, particularly when the estimated advantage approaches zero. To address this limitation, we propose Advantage-Augmented Policy Optimization (AAPO), a novel RL algorithm that optimizes the cross-entropy (CE) loss using advantages enhanced through a momentum-based estimation scheme. This approach effectively mitigates the inefficiencies associated with group relative advantage estimation. Experimental results on multiple mathematical reasoning benchmarks demonstrate the superior performance of AAPO.
Regression-free Blind Image Quality Assessment
Jul 18, 2023



Regression-based blind image quality assessment (IQA) models are susceptible to biased training samples, leading to a biased estimation of model parameters. To mitigate this issue, we propose a regression-free framework for image quality evaluation, which is founded upon retrieving similar instances by incorporating semantic and distortion features. The motivation behind this approach is rooted in the observation that the human visual system (HVS) has analogous visual responses to semantically similar image contents degraded by the same distortion. The proposed framework comprises two classification-based modules: semantic-based classification (SC) module and distortion-based classification (DC) module. Given a test image and an IQA database, the SC module retrieves multiple pristine images based on semantic similarity. The DC module then retrieves instances based on distortion similarity from the distorted images that correspond to each retrieved pristine image. Finally, the predicted quality score is derived by aggregating the subjective quality scores of multiple retrieved instances. Experimental results on four benchmark databases validate that the proposed model can remarkably outperform the state-of-the-art regression-based models.
Joint Spatial Division and Coaxial Multiplexing for Downlink Multi-User OAM Wireless Backhaul
Oct 18, 2021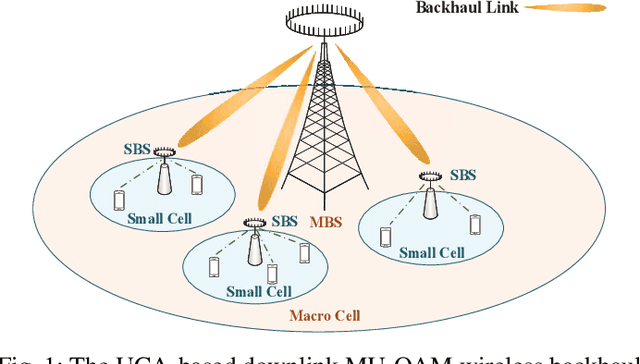
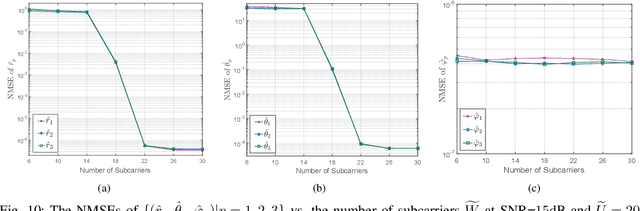
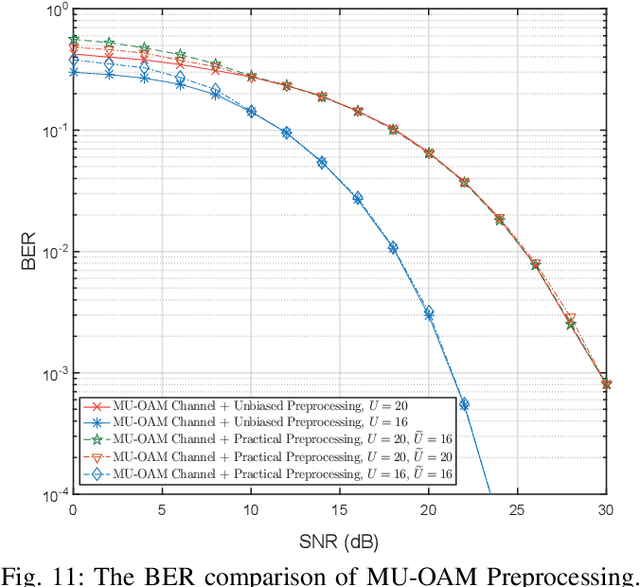
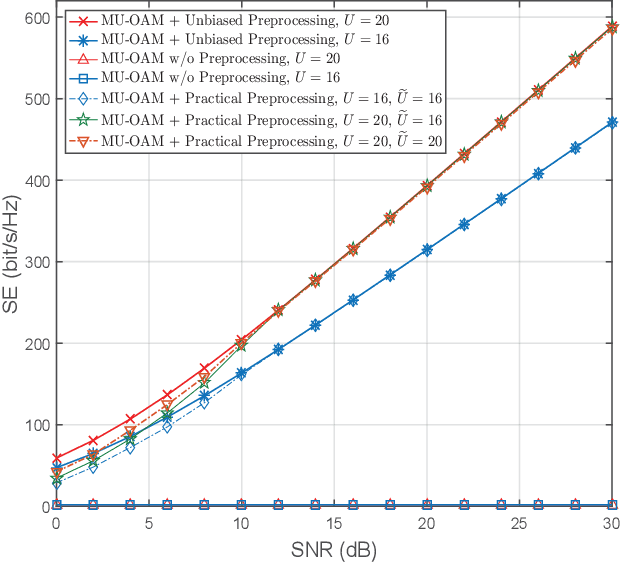
Orbital angular momentum (OAM) at radio frequency (RF) provides a novel approach of multiplexing a set of orthogonal modes on the same frequency channel to achieve high spectral efficiencies (SEs). However, the existing research on OAM wireless communications is mainly focused on pointto-point transmission in the line-of-sight (LoS) scenario. In this paper, we propose an overall scheme of the downlink multi-user OAM (MU-OAM) wireless backhaul based on uniform circular arrays (UCAs) for broadcasting networks, which can achieve the joint spatial division and coaxial multiplexing (JSDCM). A salient feature of the proposed downlink MU-OAM wireless backhaul systems is that the channel matrices are completely characterized by the position of each small base station (SBS), independent of the numbers of subcarriers and antennas, which avoids estimating large channel matrices required by the traditional downlink multi-user multiple-input multiple-output (MU-MIMO) wireless backhaul systems. Thereafter, we propose an OAM-based multiuser distance and angle of arrival (AoA) estimation method, which is able to simultaneously estimate the positions of multiple SBSs with a flexible number of training symbols. With the estimated distances and AoAs, a MU-OAM preprocessing scheme is applied to eliminate the co-mode and inter-mode interferences in the downlink MU-OAM channel. At last, the proposed methods are extended to the downlink MU-OAM-MIMO wireless backhaul system equipped with uniform concentric circular arrays (UCCAs), for which much higher spectral efficiency (SE) and energy efficiency (EE) than traditional MU-MIMO systems can be achieved. Both mathematical analysis and simulation results validate that the proposed scheme can effectively eliminate both interferences of the practical downlink MU-OAM channel and approaches the performance of the ideal MU-OAM channel.
Advanced Geometry Surface Coding for Dynamic Point Cloud Compression
Mar 11, 2021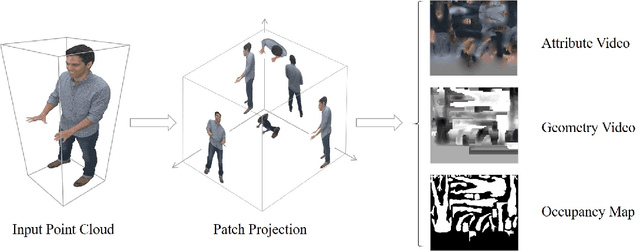
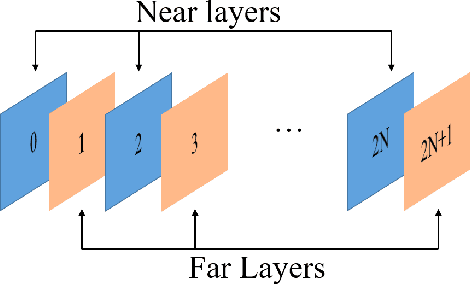
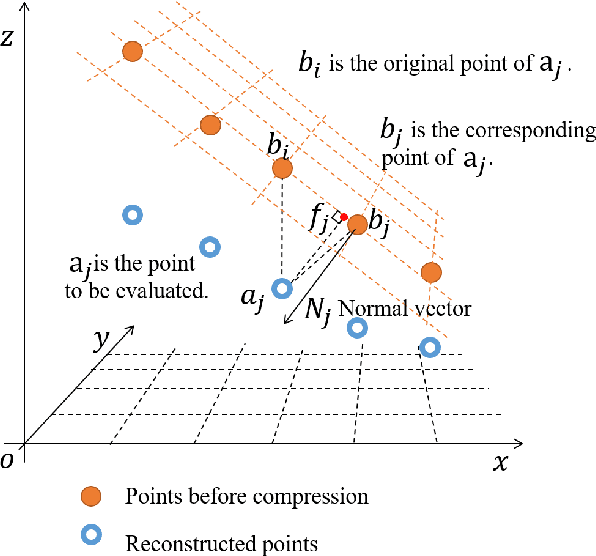
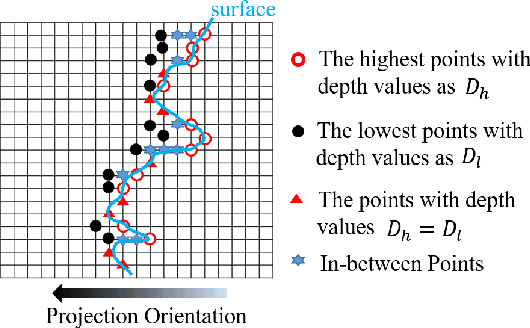
In video-based dynamic point cloud compression (V-PCC), 3D point clouds are projected onto 2D images for compressing with the existing video codecs. However, the existing video codecs are originally designed for natural visual signals, and it fails to account for the characteristics of point clouds. Thus, there are still problems in the compression of geometry information generated from the point clouds. Firstly, the distortion model in the existing rate-distortion optimization (RDO) is not consistent with the geometry quality assessment metrics. Secondly, the prediction methods in video codecs fail to account for the fact that the highest depth values of a far layer is greater than or equal to the corresponding lowest depth values of a near layer. This paper proposes an advanced geometry surface coding (AGSC) method for dynamic point clouds (DPC) compression. The proposed method consists of two modules, including an error projection model-based (EPM-based) RDO and an occupancy map-based (OM-based) merge prediction. Firstly, the EPM model is proposed to describe the relationship between the distortion model in the existing video codec and the geometry quality metric. Secondly, the EPM-based RDO method is presented to project the existing distortion model on the plane normal and is simplified to estimate the average normal vectors of coding units (CUs). Finally, we propose the OM-based merge prediction approach, in which the prediction pixels of merge modes are refined based on the occupancy map. Experiments tested on the standard point clouds show that the proposed method achieves an average 9.84\% bitrate saving for geometry compression.