 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptation Method for Misinformation Identification
Apr 19, 2025



Multimodal fake news detection plays a crucial role in combating online misinformation. Unfortunately, effective detection methods rely on annotated labels and encounter significant performance degradation when domain shifts exist between training (source) and test (target) data. To address the problems, we propose ADOSE, an Active Domain Adaptation (ADA) framework for multimodal fake news detection which actively annotates a small subset of target samples to improve detection performance. To identify various deceptive patterns in cross-domain settings, we design multiple expert classifiers to learn dependencies across different modalities. These classifiers specifically target the distinct deception patterns exhibited in fake news, where two unimodal classifiers capture knowledge errors within individual modalities while one cross-modal classifier identifies semantic inconsistencies between text and images. To reduce annotation costs from the target domain, we propose a least-disagree uncertainty selector with a diversity calculator for selecting the most informative samples. The selector leverages prediction disagreement before and after perturbations by multiple classifiers as an indicator of uncertain samples, whose deceptive patterns deviate most from source domains. It further incorporates diversity scores derived from multi-view features to ensure the chosen samples achieve maximal coverage of target domain features. The extensive experiments on multiple datasets show that ADOSE outperforms existing ADA methods by 2.72\% $\sim$ 14.02\%, indicating the superiority of our model.
DIDS: Domain Impact-aware Data Sampling for Large Language Model Training
Apr 17, 2025



Large language models (LLMs) are commonly trained on multi-domain datasets, where domain sampling strategies significantly impact model performance due to varying domain importance across downstream tasks. Existing approaches for optimizing domain-level sampling strategies struggle with maintaining intra-domain consistency and accurately measuring domain impact. In this paper, we present Domain Impact-aware Data Sampling (DIDS). To ensure intra-domain consistency, a gradient clustering algorithm is proposed to group training data based on their learning effects, where a proxy language model and dimensionality reduction are employed to reduce computational overhead. To accurately measure domain impact, we develop a Fisher Information Matrix (FIM) guided metric that quantifies how domain-specific parameter updates affect the model's output distributions on downstream tasks, with theoretical guarantees. Furthermore, to determine optimal sampling ratios, DIDS combines both the FIM-guided domain impact assessment and loss learning trajectories that indicate domain-specific potential, while accounting for diminishing marginal returns. Extensive experiments demonstrate that DIDS achieves 3.4% higher average performance while maintaining comparable training efficiency.
Transferable Deployment of Semantic Edge Inference Systems via Unsupervised Domain Adaption
Apr 16, 2025This paper investigates deploying semantic edge inference systems for performing a common image clarification task. In particular, each system consists of multiple Internet of Things (IoT) devices that first locally encode the sensing data into semantic features and then transmit them to an edge server for subsequent data fusion and task inference. The inference accuracy is determined by efficient training of the feature encoder/decoder using labeled data samples. Due to the difference in sensing data and communication channel distributions, deploying the system in a new environment may induce high costs in annotating data labels and re-training the encoder/decoder models. To achieve cost-effective transferable system deployment, we propose an efficient Domain Adaptation method for Semantic Edge INference systems (DASEIN) that can maintain high inference accuracy in a new environment without the need for labeled samples. Specifically, DASEIN exploits the task-relevant data correlation between different deployment scenarios by leveraging the techniques of unsupervised domain adaptation and knowledge distillation. It devises an efficient two-step adaptation procedure that sequentially aligns the data distributions and adapts to the channel variations. Numerical results show that, under a substantial change in sensing data distributions, the proposed DASEIN outperforms the best-performing benchmark method by 7.09% and 21.33% in inference accuracy when the new environment has similar or 25 dB lower channel signal to noise power ratios (SNRs), respectively. This verifies the effectiveness of the proposed method in adapting both data and channel distributions in practical transfer deployment applications.
CheatAgent: Attacking LLM-Empowered Recommender Systems via LLM Agent
Apr 13, 2025Recently, Large Language Model (LLM)-empowered recommender systems (RecSys) have brought significant advances in personalized user experience and have attracted considerable attention. Despite the impressive progress, the research question regarding the safety vulnerability of LLM-empowered RecSys still remains largely under-investigated. Given the security and privacy concerns, it is more practical to focus on attacking the black-box RecSys, where attackers can only observe the system's inputs and outputs. However, traditional attack approaches employing reinforcement learning (RL) agents are not effective for attacking LLM-empowered RecSys due to the limited capabilities in processing complex textual inputs, planning, and reasoning. On the other hand, LLMs provide unprecedented opportunities to serve as attack agents to attack RecSys because of their impressive capability in simulating human-like decision-making processes. Therefore, in this paper, we propose a novel attack framework called CheatAgent by harnessing the human-like capabilities of LLMs, where an LLM-based agent is developed to attack LLM-Empowered RecSys. Specifically, our method first identifies the insertion position for maximum impact with minimal input modification. After that, the LLM agent is designed to generate adversarial perturbations to insert at target positions. To further improve the quality of generated perturbations, we utilize the prompt tuning technique to improve attacking strategies via feedback from the victim RecSys iteratively. Extensive experiments across three real-world datasets demonstrate the effectiveness of our proposed attacking method.
Seaweed-7B: Cost-Effective Training of Video Generation Foundation Model
Apr 11, 2025



This technical report presents a cost-efficient strategy for training a video generation foundation model. We present a mid-sized research model with approximately 7 billion parameters (7B) called Seaweed-7B trained from scratch using 665,000 H100 GPU hours. Despite being trained with moderate computational resources, Seaweed-7B demonstrates highly competitive performance compared to contemporary video generation models of much larger size. Design choices are especially crucial in a resource-constrained setting. This technical report highlights the key design decisions that enhance the performance of the medium-sized diffusion model. Empirically, we make two observations: (1) Seaweed-7B achieves performance comparable to, or even surpasses, larger models trained on substantially greater GPU resources, and (2) our model, which exhibits strong generalization ability, can be effectively adapted across a wide range of downstream applications either by lightweight fine-tuning or continue training. See the project page at https://seaweed.video/
Multi-modal Reference Learning for Fine-grained Text-to-Image Retrieval
Apr 10, 2025Fine-grained text-to-image retrieval aims to retrieve a fine-grained target image with a given text query. Existing methods typically assume that each training image is accurately depicted by its textual descriptions. However, textual descriptions can be ambiguous and fail to depict discriminative visual details in images, leading to inaccurate representation learning. To alleviate the effects of text ambiguity, we propose a Multi-Modal Reference learning framework to learn robust representations. We first propose a multi-modal reference construction module to aggregate all visual and textual details of the same object into a comprehensive multi-modal reference. The multi-modal reference hence facilitates the subsequent representation learning and retrieval similarity computation. Specifically, a reference-guided representation learning module is proposed to use multi-modal references to learn more accurate visual and textual representations. Additionally, we introduce a reference-based refinement method that employs the object references to compute a reference-based similarity that refines the initial retrieval results. Extensive experiments are conducted on five fine-grained text-to-image retrieval datasets for different text-to-image retrieval tasks. The proposed method has achieved superior performance over state-of-the-art methods. For instance, on the text-to-person image retrieval dataset RSTPReid, our method achieves the Rank1 accuracy of 56.2\%, surpassing the recent CFine by 5.6\%.
Fusing Global and Local: Transformer-CNN Synergy for Next-Gen Current Estimation
Apr 08, 2025This paper presents a hybrid model combining Transformer and CNN for predicting the current waveform in signal lines. Unlike traditional approaches such as current source models, driver linear representations, waveform functional fitting, or equivalent load capacitance methods, our model does not rely on fixed simplified models of standard-cell drivers or RC loads. Instead, it replaces the complex Newton iteration process used in traditional SPICE simulations, leveraging the powerful sequence modeling capabilities of the Transformer framework to directly predict current responses without iterative solving steps. The hybrid architecture effectively integrates the global feature-capturing ability of Transformers with the local feature extraction advantages of CNNs, significantly improving the accuracy of current waveform predictions. Experimental results demonstrate that, compared to traditional SPICE simulations, the proposed algorithm achieves an error of only 0.0098. These results highlight the algorithm's superior capabilities in predicting signal line current waveforms, timing analysis, and power evaluation, making it suitable for a wide range of technology nodes, from 40nm to 3nm.
POMATO: Marrying Pointmap Matching with Temporal Motion for Dynamic 3D Reconstruction
Apr 08, 20253D reconstruction in dynamic scenes primarily relies on the combination of geometry estimation and matching modules where the latter task is pivotal for distinguishing dynamic regions which can help to mitigate the interference introduced by camera and object motion. Furthermore, the matching module explicitly models object motion, enabling the tracking of specific targets and advancing motion understanding in complex scenarios. Recently, the proposed representation of pointmap in DUSt3R suggests a potential solution to unify both geometry estimation and matching in 3D space, but it still struggles with ambiguous matching in dynamic regions, which may hamper further improvement. In this work, we present POMATO, a unified framework for dynamic 3D reconstruction by marrying pointmap matching with temporal motion. Specifically, our method first learns an explicit matching relationship by mapping RGB pixels from both dynamic and static regions across different views to 3D pointmaps within a unified coordinate system. Furthermore, we introduce a temporal motion module for dynamic motions that ensures scale consistency across different frames and enhances performance in tasks requiring both precise geometry and reliable matching, most notably 3D point tracking. We show the effectiveness of the proposed pointmap matching and temporal fusion paradigm by demonstrating the remarkable performance across multiple downstream tasks, including video depth estimation, 3D point tracking, and pose estimation. Code and models are publicly available at https://github.com/wyddmw/POMATO.
A Survey of Pathology Foundation Model: Progress and Future Directions
Apr 05, 2025



Computational pathology, analyzing whole slide images for automated cancer diagnosis, relies on the multiple instance learning framework where performance heavily depends on the feature extractor and aggregator. Recent Pathology Foundation Models (PFMs), pretrained on large-scale histopathology data, have significantly enhanced capabilities of extractors and aggregators but lack systematic analysis frameworks. This survey presents a hierarchical taxonomy organizing PFMs through a top-down philosophy that can be utilized to analyze FMs in any domain: model scope, model pretraining, and model design. Additionally, we systematically categorize PFM evaluation tasks into slide-level, patch-level, multimodal, and biological tasks, providing comprehensive benchmarking criteria. Our analysis identifies critical challenges in both PFM development (pathology-specific methodology, end-to-end pretraining, data-model scalability) and utilization (effective adaptation, model maintenance), paving the way for future directions in this promising field. Resources referenced in this survey are available at https://github.com/BearCleverProud/AwesomeWSI.
Monocular and Generalizable Gaussian Talking Head Animation
Apr 01, 2025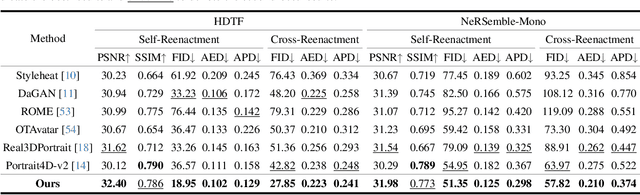
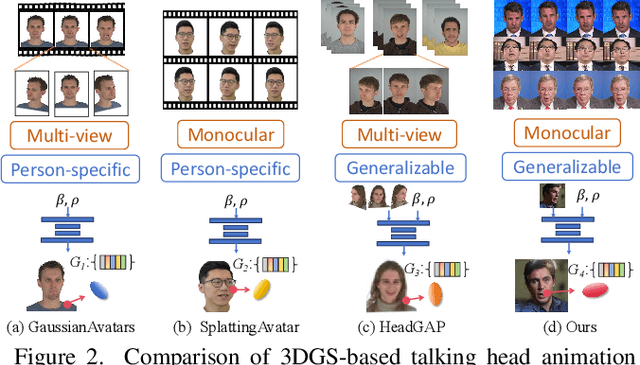
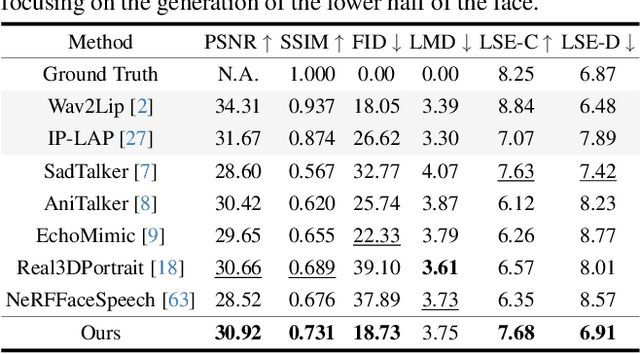
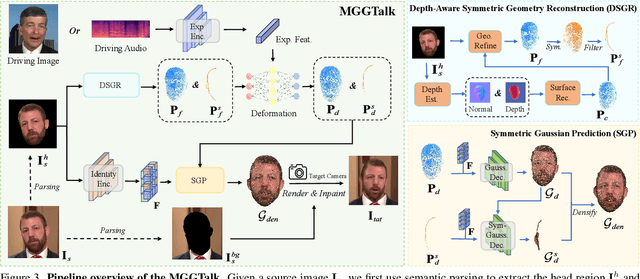
In this work, we introduce Monocular and Generalizable Gaussian Talking Head Animation (MGGTalk), which requires monocular datasets and generalizes to unseen identities without personalized re-training. Compared with previous 3D Gaussian Splatting (3DGS) methods that requires elusive multi-view datasets or tedious personalized learning/inference, MGGtalk enables more practical and broader applications. However, in the absence of multi-view and personalized training data, the incompleteness of geometric and appearance information poses a significant challenge. To address these challenges, MGGTalk explores depth information to enhance geometric and facial symmetry characteristics to supplement both geometric and appearance features. Initially, based on the pixel-wise geometric information obtained from depth estimation, we incorporate symmetry operations and point cloud filtering techniques to ensure a complete and precise position parameter for 3DGS. Subsequently, we adopt a two-stage strategy with symmetric priors for predicting the remaining 3DGS parameters. We begin by predicting Gaussian parameters for the visible facial regions of the source image. These parameters are subsequently utilized to improve the prediction of Gaussian parameters for the non-visible regions. Extensive experiments demonstrate that MGGTalk surpasses previous state-of-the-art methods, achieving superior performance across various metrics.