 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Reference Learning for Fine-grained Text-to-Image Retrieval
Apr 10, 2025Fine-grained text-to-image retrieval aims to retrieve a fine-grained target image with a given text query. Existing methods typically assume that each training image is accurately depicted by its textual descriptions. However, textual descriptions can be ambiguous and fail to depict discriminative visual details in images, leading to inaccurate representation learning. To alleviate the effects of text ambiguity, we propose a Multi-Modal Reference learning framework to learn robust representations. We first propose a multi-modal reference construction module to aggregate all visual and textual details of the same object into a comprehensive multi-modal reference. The multi-modal reference hence facilitates the subsequent representation learning and retrieval similarity computation. Specifically, a reference-guided representation learning module is proposed to use multi-modal references to learn more accurate visual and textual representations. Additionally, we introduce a reference-based refinement method that employs the object references to compute a reference-based similarity that refines the initial retrieval results. Extensive experiments are conducted on five fine-grained text-to-image retrieval datasets for different text-to-image retrieval tasks. The proposed method has achieved superior performance over state-of-the-art methods. For instance, on the text-to-person image retrieval dataset RSTPReid, our method achieves the Rank1 accuracy of 56.2\%, surpassing the recent CFine by 5.6\%.
Deep Residual Correction Network for Partial Domain Adaptation
Apr 10, 2020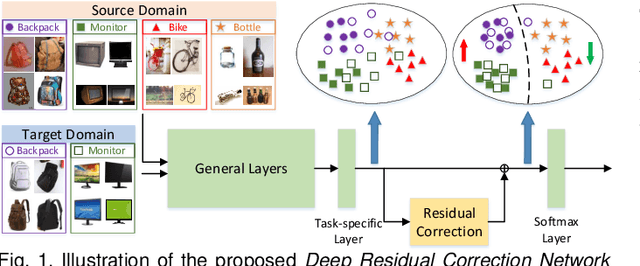
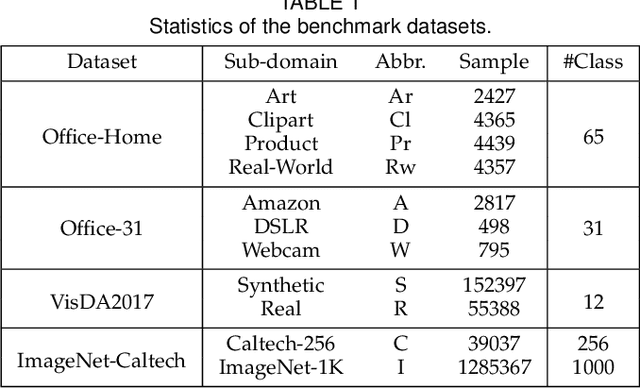
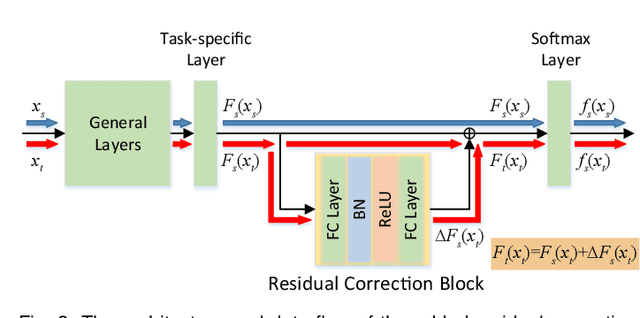
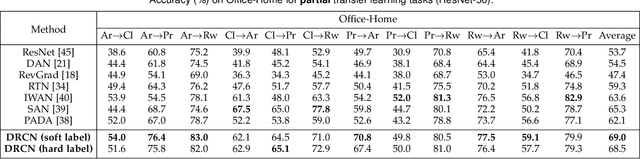
Deep domain adaptation methods have achieved appealing performance by learning transferable representations from a well-labeled source domain to a different but related unlabeled target domain. Most existing works assume source and target data share the identical label space, which is often difficult to be satisfied in many real-world applications. With the emergence of big data, there is a more practical scenario called partial domain adaptation, where we are always accessible to a more large-scale source domain while working on a relative small-scale target domain. In this case, the conventional domain adaptation assumption should be relaxed, and the target label space tends to be a subset of the source label space. Intuitively, reinforcing the positive effects of the most relevant source subclasses and reducing the negative impacts of irrelevant source subclasses are of vital importance to address partial domain adaptation challenge. This paper proposes an efficiently-implemented Deep Residual Correction Network (DRCN) by plugging one residual block into the source network along with the task-specific feature layer, which effectively enhances the adaptation from source to target and explicitly weakens the influence from the irrelevant source classes. Specifically, the plugged residual block, which consists of several fully-connected layers, could deepen basic network and boost its feature representation capability correspondingly. Moreover, we design a weighted class-wise domain alignment loss to couple two domains by matching the feature distributions of shared classes between source and target. Comprehensive experiments on partial, traditional and fine-grained cross-domain visual recognition demonstrate that DRCN is superior to the competitive deep domain adaptation approaches.